1. 접속 환경 설정

build.gradle 의존성 추가
// Elasticsearch
implementation 'org.springframework.data:spring-data-elasticsearch:5.1.3'
Java
복사
application.properties 연결 주소 입력
# Elasticsearch URL 설정
spring.elastic.url=localhost:9200
Java
복사
ElasticsearchConfig.java를 통한 Elasticsearch 실제 커넥션
application.properties에서 직접 연결 할 수도 있지만 모듈화시켜서 구조를 살펴보고자 했습니다.
@Configuration
public class ElasticsearchConfig extends ElasticsearchConfiguration {
@Value("${spring.elastic.url}")
private String elasticUrl;
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo(elasticUrl)
.build();
}
}
Java
복사
2. 3 Layered 아키텍처와 Elasticsearch 연결
ElasticsearchBook.java JPA엔티티와의 충돌을 막기 위한 전용 엔티티 생성
기존 Book.java 엔티티에 @Document 어노테이션을 사용하면 JPA와 Elasticsearch가 동시에 해당 엔티티에 접근하게 되면서 충돌 문제가 발생했었습니다. 여러 참고자료를 찾아본 결과 ~Application.java 메인 이닛 클래스에서 @Enable.. 어노테이션을 통해서 각각 스캔 대상을 분리 시킬 수도 있지만, 우선 간략한 테스트 과정을 위해서 우선 별도의 엔티티를 생성하는 것으로 대체했습니다.
•
@Document어노테이션으로 인덱스명(RDBMS의 테이블명과 비슷)을 입력하면 의 인덱스와 맵핑됩니다.
•
@Field어노테이션으로 각 필드(RDBMS의 컬럼과 비슷) 타입, 이름을 지정하게 됩니다.
•
Elasticsearch는 소문자로만 구성하라는 주의사항이 있었고 이름에 스네이크 컨벤션을 유지했습니다.
@Document(indexName = "book")
public class ElasticsearchBook {
@Id
@Field(type = FieldType.Long, name = "book_id")
private Long bookId;
@Field(type = FieldType.Text, name = "book_author")
private String bookAuthor;
@Field(type = FieldType.Keyword, name = "book_status")
private String bookStatus;
@Field(type = FieldType.Keyword, name = "book_publish")
private String bookPublish;
@Field(type = FieldType.Keyword, name = "book_name")
private String bookName;
// 나머지 필드들에 대한 매핑 추가
}
Java
복사
Controller
기본적인 테스트를 위한 컨트롤러 작성입니다. Elasticsearch용 엔티티인 ElasticsearchBook.java 를 사용해서 어떤 결과가 나타나는지 확인하고자 했습니다.
@RequiredArgsConstructor
@RequestMapping
@Controller
public class ElasticBookSearchController {
private final ElasticBookService elasticBookService;
// Elasticsearch + 무한스크롤 기능 구현 초기 페이지 진입
@GetMapping("/search/el1")
public String elasticSearchResults(
@RequestParam(value = "keyword", required = false) String keyword,
@RequestParam(value = "page", defaultValue = "0", required = false) Integer page,
@RequestParam(value = "size", defaultValue = "20", required = false) Integer size,
Model model) {
long startTime = System.currentTimeMillis(); // 실행시간 측정
// 페이지 요청 시, 현재까지의 모든 페이지를 가져오도록 수정
List<ElasticBookResponseDto> elasticBookResponseDtos = elasticBookService.searchByBookName(keyword, page, size);
model.addAttribute("currentPage", page);
model.addAttribute("books", elasticBookResponseDtos);
model.addAttribute("hasNext", !elasticBookResponseDtos.isEmpty());
long endTime = System.currentTimeMillis();
long durationTimeSec = endTime - startTime;
System.out.println(durationTimeSec + "m/s"); // 실행시간 측정
return "users/searchEL1";
}
// Elasticsearch 무한 스크롤 데이터 요청 API
@GetMapping("search/elastic")
@ResponseBody
public ResponseEntity<List<ElasticBookResponseDto>> search(
@RequestParam("keyword") String book_name,
@RequestParam(value = "page", defaultValue = "0", required = false) Integer page,
@RequestParam(value = "size", defaultValue = "20", required = false) Integer size) {
List<ElasticBookResponseDto> elasticBookResponses = elasticBookService.searchByBookName(book_name, page, size)
.stream()
.map(ElasticBookResponseDto::from)
.collect(Collectors.toList());
return ResponseEntity.ok(elasticBookResponses);
}
}
Java
복사
Service
기존 JPA로 MySQL과 연결된 Repository들과 차이점을 보기위해 별도로 ElasticBookSearchRepository 로 부터 접근하도록 했습니다.
@Slf4j
@RequiredArgsConstructor
@Transactional(readOnly = true)
@Service
public class ElasticBookService {
private final BookRepository bookRepository;
private final ElasticBookSearchRepository elasticBookSearchRepository;
public List<ElasticBookResponseDto> searchByBookName(String keyword, int page, int size) {
if (keyword == null) {
// 검색 키워드가 null인 경우에 대한 처리
return Collections.emptyList();
}
Sort sort = Sort.by(Sort.Direction.ASC, "_id");
Pageable pageable = PageRequest.of(page, size, sort);
return elasticBookSearchRepository.findByBookNameContains(keyword, pageable)
.stream()
.map(ElasticBookResponseDto::from)
.collect(Collectors.toList());
}
}
Java
복사
Repository
ElasticsearchRepository를 상속받는 인터페이스를 구성합니다. 이는 마치 이전 JPA를 사용하기 위해서 JpaRepository를 상속받았던 것과 비슷하다고 볼 수 있습니다. ElasticsearchRepository의 구현체를 정의한다고 볼 수 있습니다.
/**
* 엘라스틱 서치를 사용해서 도서 검색을 위한 기본 레포지토리입니다.
* */
public interface ElasticBookSearchRepository extends ElasticsearchRepository<ElasticsearchBook, Long>, ElasticCustomBookSearchRepository {
List<ElasticsearchBook> findByBookNameContains(String keyword);
}
Java
복사
public interface ElasticCustomBookSearchRepository {
List<ElasticsearchBook> findByBookNameContains(String keyword, Pageable pageable);
}
Java
복사
ElasticCustomBookSearchRepositoryImpl 을 통해서 쿼리문을 튜닝 할 수 있도록 합니다.
@Repository
@RequiredArgsConstructor
public class ElasticCustomBookSearchRepositoryImpl implements ElasticCustomBookSearchRepository {
private final ElasticsearchOperations elasticsearchOperations;
@Override
public List<ElasticsearchBook> findByBookNameContains(String keyword, Pageable pageable){
Criteria criteria = Criteria.where("bookName").contains(keyword);
Query query = new CriteriaQuery(criteria).setPageable(pageable);
SearchHits<ElasticsearchBook> search = elasticsearchOperations.search(query, ElasticsearchBook.class);
return search.stream()
.map(SearchHit::getContent)
.collect(Collectors.toList());
}
}
Java
복사
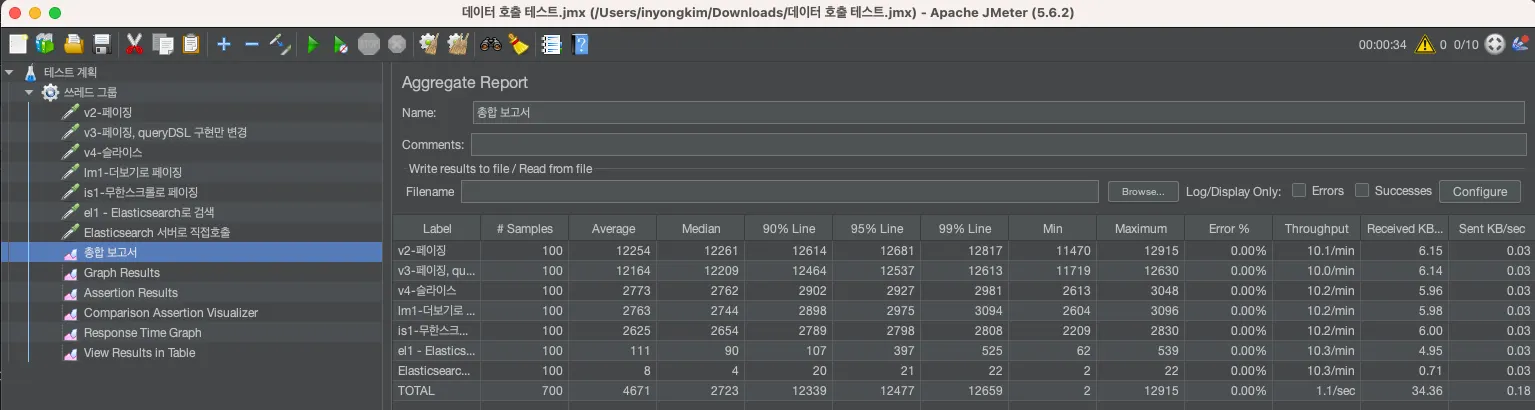
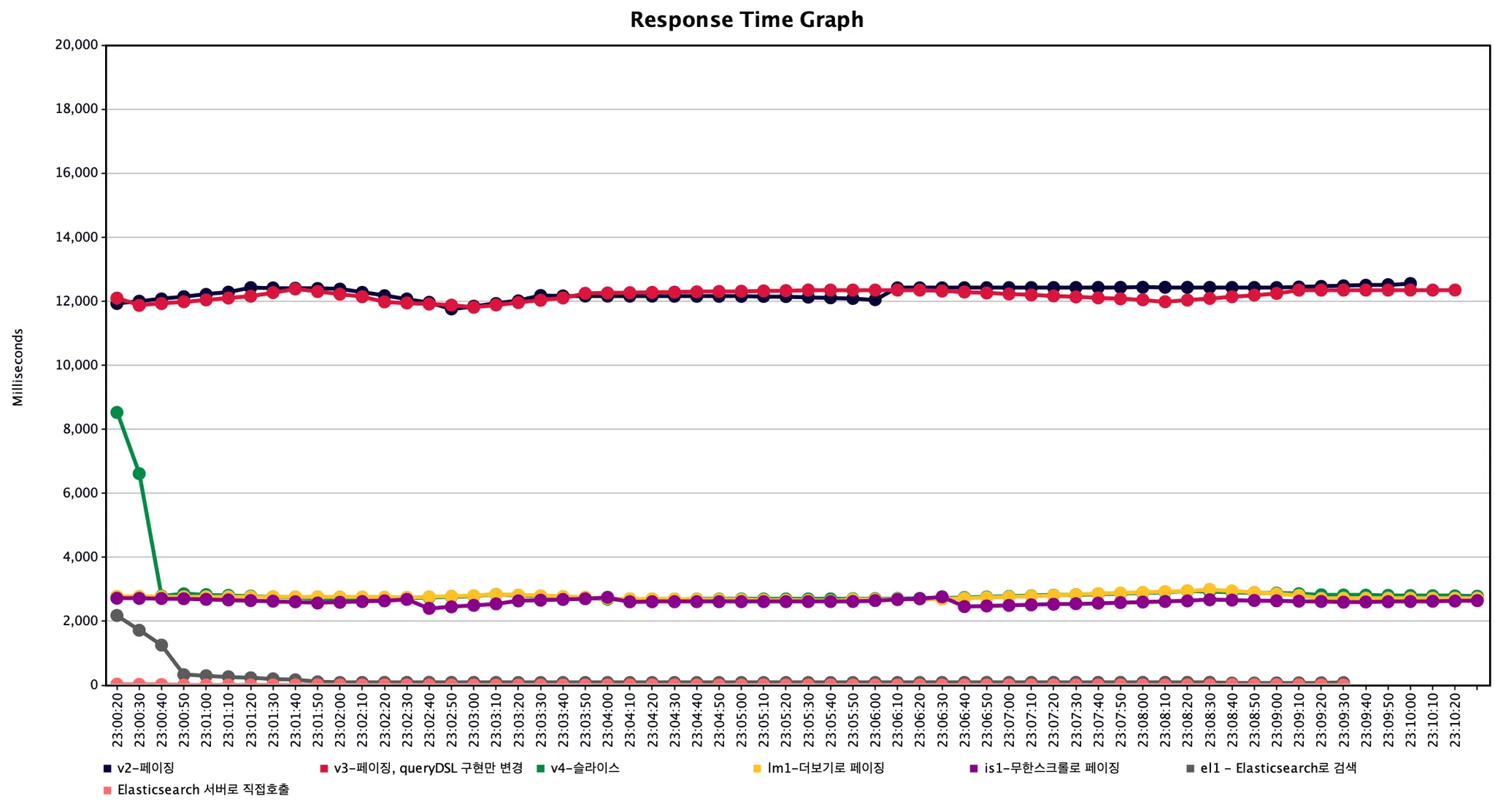
3. 테스트
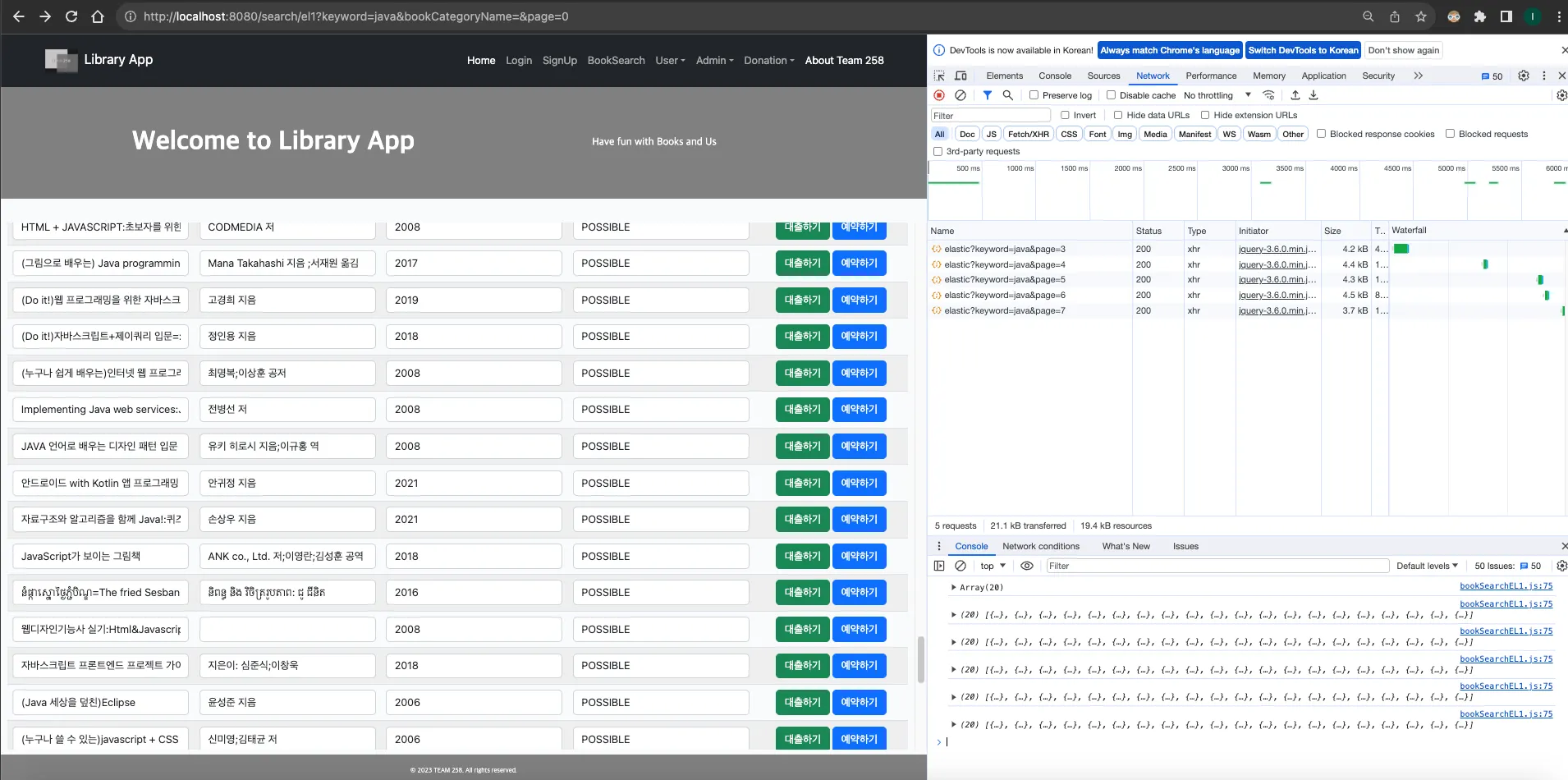
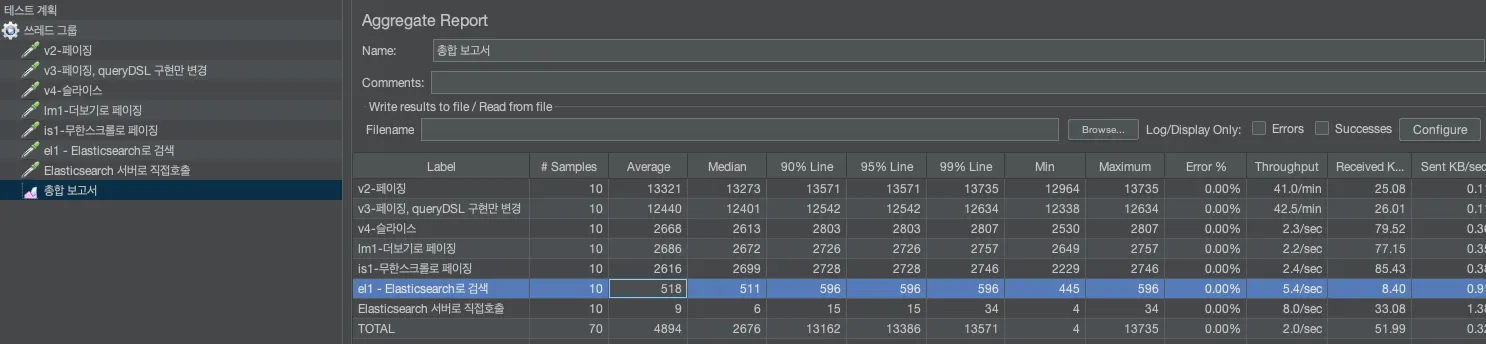
Elasticsearch는 기본적으로 데이터를 캐싱하여 검색 성능을 최적화하는데, 이는 반복되는 동일한 검색 요청에 대해 더 빠른 응답을 제공할 수 있습니다. 이러한 캐싱은 검색 결과, 필터링, 집계 등에 적용될 수 있습니다. 기본적으로 키워드 검색에 대하여 높은 성능을 가지고 있음과 동시에 동일한 검색 요청이 누적됨에 따라 계속하여 요청 속도가 증가하는 것을 살펴 볼 수 있습니다.