


AI/딥러닝(CNN/RNN), 스마트시티, 딥페이크의 핵심 이론을 배우고, Colab 환경에서 Python(Numpy/Pandas, librosa)으로 데이터 분석 실습을 진행함.
Table of Content

1일차: AI 혁신과 스마트시티: 딥페이크 탐지 첫걸음
부제: AI 기본기, 스마트시티 적용, 그리고 딥페이크 문제의 이해
Agenda: 1일차 학습 목표 및 일정
1.
AI/DL 이론: AI, 머신러닝, 딥러닝 개념 및 차이점 이해
2.
실습 1 (환경): Colab 및 Python 데이터 분석 도구 (Numpy/Pandas) 활용
3.
스마트시티 이론: 스마트시티 개념, AI 활용 방안
4.
딥페이크 이론: 딥페이크 기술 원리 및 사회적 문제점 인지
5.
실습 2 (분석): 딥페이크 샘플 데이터 분석 및 토론
모듈 1: AI 개요 및 딥러닝 (이론)
1. 인공지능(AI)의 정의


•
인간의 지적 능력(학습, 추론, 지각 등)을 모방하는 컴퓨터 시스템.

이번 과정에서 우리가 만들게 될 딥페이크 탐지 시스템의 가장 근간이 되는 개념입니다. 먼저 AI, 즉 인공지능의 정의부터 짚고 넘어가겠습니다.
AI는 인간의 지적 능력을 모방하는 컴퓨터 시스템'으로 정의합니다.
여기서 저희 개발자들에게 중요한 키워드는 '학습', '추론', '지각'입니다.
과거의 소프트웨어가 명확한 '규칙 기반(Rule-based)'으로, 즉 개발자가 조건문을 통해서 if-else로 모든 분기점을 정의했다면, AI는 정해진 규칙이 아니라 데이터를 통해 스스로 규칙을 찾아내는 시스템을 의미합니다.
결론적으론 단순한 연산 능력을 가지던 컴퓨터가 스스로 판단과 결과를 분석하는 과정이 있을 이야기합니다.
•
스마트시티의 핵심 두뇌 역할.
두 번째 항목인 '스마트시티의 핵심 두뇌 역할'이 바로 이 과정과 AI를 연결하는 핵심입니다.
스마트시티는 도시 전역의 IoT 센서, CCTV, 교통 정보 등 막대한 데이터를 수집합니다. AI는 이 데이터를 분석하여 '의사결정'을 내리는 두뇌 역할을 수행합니다. 예를 들어, 교통 흐름을 예측하고, 에너지 사용을 최적화하며, 이상 징후(안전 문제)를 감지하는 것이죠.
그리고 우리 과정의 최종 목표인 '딥페이크 탐지' 역시 이 AI의 핵심 역할 중 하나입니다.
딥페이크는 'AI가 만들어낸 위협(AI-generated threat)'입니다. 따라서 우리는 또 다른 'AI 모델'을 훈련시켜, 스마트시티의 비대면 인증이나 보안 시스템을 교란하는 이 딥페이크 위협을 '탐지'하고 '방어'하는 방법을 배우게 될 것입니다.
즉, AI는 스마트시티의 강력한 두뇌이자, 동시에 우리가 해결해야 할 과제를 제시하는 주체이기도 합니다.
2. 머신러닝(ML) vs 딥러닝(DL)
•
머신러닝: 데이터로부터 패턴을 학습하여 스스로 판단하는 기술.
•
딥러닝: 머신러닝의 하위 분야. 인간의 신경망을 모방 (ANN).
•
핵심 차이: 딥러닝은 데이터의 '특징(Feature)'까지 스스로 학습함.
"앞서 AI가 '스스로 학습하는 시스템'이라고 말씀드렸는데, 이 '학습'을 구현하는 대표적인 방식이 바로 머신러닝(ML)입니다.
머신러닝은 말 그대로 “머신(기계)이 학습한다.” 그대로 데이터로부터 패턴을 학습하여 스스로 판단하는 기술입니다.
예를 들어, 스팸 메일 필터를 만든다고 가정해 보죠. 과거의 스팸 메일 데이터에서 '광고', '무료', '당첨' 같은 단어가 얼마나 자주 등장하는지 통계를 냅니다. 그리고 이 통계(패턴)를 기반으로 '이건 80% 확률로 스팸이다'라고 판단하는 모델을 만드는 것이죠.
그런데 이 머신러닝의 한계는 '무엇을 학습할지', 즉 '특징(Feature)'을 사람이 정해줘야 한다는 점입니다.
방금 예시처럼 '광고'나 '무료'라는 단어가 중요하다는 것을 '개발자'가 미리 알고 모델에 알려줘야 합니다. 이것을 전문 용어로 '특징 공학(Feature Engineering)'이라고 부르는데, 사실상 모델 성능의 대부분이 이 특징 공학에서 결정됩니다.
여기서 딥러닝(DL)이 등장합니다.
딥러닝은 이 머신러닝 기법 중 하나이며, 보시는 것처럼 '인간의 신경망(ANN)' 구조를 모방한 모델을 사용합니다. 이름처럼 더 '깊은(Deep)' 신경망 층을 가지고 있죠.
가장 중요한 것은 핵심 차이입니다.
딥러닝은 머신러닝과 달리, 데이터의 '특징(Feature)'까지 스스로 학습합니다.
개발자가 '광고'나 '무료' 같은 특징을 알려주지 않아도, 딥러닝 모델은 수많은 이메일 원본(Raw Data)을 보고 '아, 이런 단어들이 스팸을 구분하는 중요한 특징이구나'를 스스로 알아냅니다.
우리가 이 과정에서 다룰 딥페이크 탐지도 마찬가지입니다.
딥페이크 이미지를 구분하기 위해 '눈 깜빡임이 부자연스럽다'거나 '피부 경계면이 어색하다' 같은 특징을 우리가 일일이 코딩하는 것이 아닙니다.
우리는 그저 딥러닝 모델에게 수많은 진짜 이미지와 가짜(딥페이크) 이미지를 보여주기만 하면 됩니다. 그러면 모델이 스스로 '진짜와 가짜를 구분하는 결정적인 차이', 즉 미세한 픽셀의 깨짐이나 어색함 같은 '특징'을 학습하게 됩니다.
이것이 딥러닝이 이미지, 음성 분야에서 강력한 이유이며, 우리가 앞으로 배울 CNN, RNN 모델의 핵심 원리입니다.
3. 딥러닝 주요 모델
"앞서 딥러닝이 스스로 '특징'을 학습한다고 말씀드렸습니다.
그러면 딥러닝 모델은 어떤 데이터에서 어떻게 특징을 학습할까요? 데이터의 종류에 따라 매우 효율적인 두 가지 대표 모델이 있습니다. 바로 CNN과 RNN입니다.
•
CNN (Convolutional Neural Network)
먼저 CNN, '합성곱 신경망'입니다.
CNN은 이미지, 즉 공간적인(2D/3D) 데이터 처리에 특화된 모델입니다.
어떻게 이미지에 특화되어 있느냐면, 바로 '필터(Filter)' 또는 '커널(Kernel)'을 사용하기 때문입니다.
이 '필터'라는 것을 이미지 위에서 쭉 훑고(Convolution) 지나가면서, 이미지의 부분적인 특징(예: 수직선, 수평선, 특정 질감, 엣지 등)을 추출합니다. 그리고 이 작은 특징들을 조합해서 더 복잡한 특징(예: 눈, 코, 입)을 학습하고, 최종적으로 이미지를 분류(예: '이것은 고양이다')하게 됩니다.
이 CNN이 바로 5일차, 6일차에 다룰 '딥페이크 이미지/영상 탐지'의 핵심 기술입니다.
딥페이크 이미지는 픽셀 레벨에서 미세한 '깨짐(artifact)'이나 '비일관성'을 보입니다. 사람 눈에는 완벽해 보여도, CNN 필터는 이 미세한 공간적 오류(특징)를 기가 막히게 잡아내도록 학습될 수 있습니다. 물론 스마트시티의 지능형 CCTV가 객체를 탐지할 때도 동일하게 CNN이 사용됩니다.
◦
이미지, 공간 데이터 처리에 특화.
◦
필터(Filter)를 사용하여 이미지의 특징을 추출/학습.
◦
적용: 딥페이크 이미지/영상 탐지, 스마트시티 CCTV 분석.
•
RNN (Recurrent Neural Network)
다음은 RNN, '순환 신경망'입니다.
RNN은 순서가 있는 데이터, 즉 '시계열(Time-series)' 데이터 처리에 특화되어 있습니다. 대표적으로 음성, 텍스트, 주식 가격 같은 데이터죠.
RNN의 핵심은 '순환 구조', 즉 '메모리(Memory)'입니다.
우리가 문장을 이해할 때, 마지막 단어만 보는 게 아니라 '앞에서부터 읽어온 단어들(문맥)'을 기억해야 뜻을 알 수 있습니다. RNN이 바로 이 '문맥'을 기억합니다. 즉, 이전 단계의 정보(출력)를 기억했다가, 다음 단계의 입력과 함께 활용하여 예측을 수행합니다.
이 RNN (혹은 이것의 발전형인 LSTM, GRU)이 바로 '딥보이스(음성) 탐지'에 사용되는 핵심 모델입니다.
딥보이스는 사람의 목소리를 시계열로 분석했을 때, 정상적인 발화 패턴(주파수 변화)과 미세하게 다른 '비정상적인 순서'나 '패턴'을 보입니다. RNN은 이 시간의 흐름에 따른 특징을 학습하여 '이건 합성된 음성이다'라고 탐지하게 됩니다. 스마트시티의 교통량 예측도 마찬가지로 시간 순서가 중요하기에 RNN 계열이 사용됩니다.
◦
순서가 있는 데이터(시계열, 음성) 처리에 특화.
◦
이전 단계의 정보를 기억하여 다음 예측에 활용 (순환 구조).
◦
적용: 딥보이스(음성) 탐지, 스마트시티 교통량 예측.
정리하자면,
이미지/영상(공간 데이터) 탐지를 위해 CNN을,음성(시계열 데이터) 탐지를 위해 RNN을
분석하고 활용하게 됩니다.
4. 주요 프레임워크 비교
•
TensorFlow (Google)
◦
강력한 생태계, 배포(Serving)에 강점.
•
PyTorch (Meta/Facebook)
◦
유연성, 직관적, 'Pythonic' 접근.
◦
연구 및 신속한 프로토타이핑에 용이.
•
본 과정에서는 두 프레임워크 모두 설치 및 체험.
모듈 2: 실습 1 - AI 개발 환경 구축 (Colab 및 라이브러리)
1. 실습 목표
•
Google Colab 환경 설정 및 기본 사용법 숙달.
•
Python 데이터 분석 핵심 라이브러리(Numpy, Pandas, Matplotlib) 기능 실습.
2. Google Colab 시작하기
•
Colab: 클라우드 기반 Python 실행 환경 (무료 GPU 지원).
•
주요 사용법:
◦
새 노트북 생성.
◦
셀(Cell) 유형: 코드(Code), 텍스트(Markdown).
◦
코드 실행: Shift + Enter.
지금까지 AI, 딥러닝, CNN, RNN 같은 '이론'을 다뤘다면, 이제부터는 이걸 '어떻게' 다루는지, 즉 '환경 구축'과 '코드'를 직접 만져볼 시간입니다.
이번 실습의 목표는 크게 두 가지입니다.
첫째, Google Colab 환경에 익숙해지는 것입니다. Colab은 우리 과정 전반에 걸쳐 AI 모델을 훈련할 핵심 도구입니다. 로컬 PC 사양과 관계없이 GPU도 무료로 제공하죠.
둘째, Python 데이터 분석의 '삼대장'이죠. Numpy, Pandas, Matplotlib의 핵심 기능을 직접 코딩해 볼 것입니다. 이미 현업에서 Python을 쓰고 계신 분들도 많겠지만, 특히 AI 데이터 전처리 관점에서 이 라이브러리들이 어떻게 쓰이는지 다시 한번 짚고 넘어가겠습니다.
자, 그럼 다 같이 브라우저에서 colab.research.google.com 으로 접속해 보겠습니다.
Colab은 구글이 제공하는 클라우드 기반의 Jupyter Notebook 환경입니다. 로컬에 무겁게 Anaconda를 설치할 필요 없이, 웹에서 바로 파이썬 코드를 실행할 수 있죠.
이제 [파일] - [새 노트]를 클릭해서 실습 노트를 하나 만들겠습니다.
가장 중요한 기능부터 확인해 볼까요?
상단 메뉴에서 [런타임] - [런타임 유형 변경]을 클릭해 보시겠습니까?
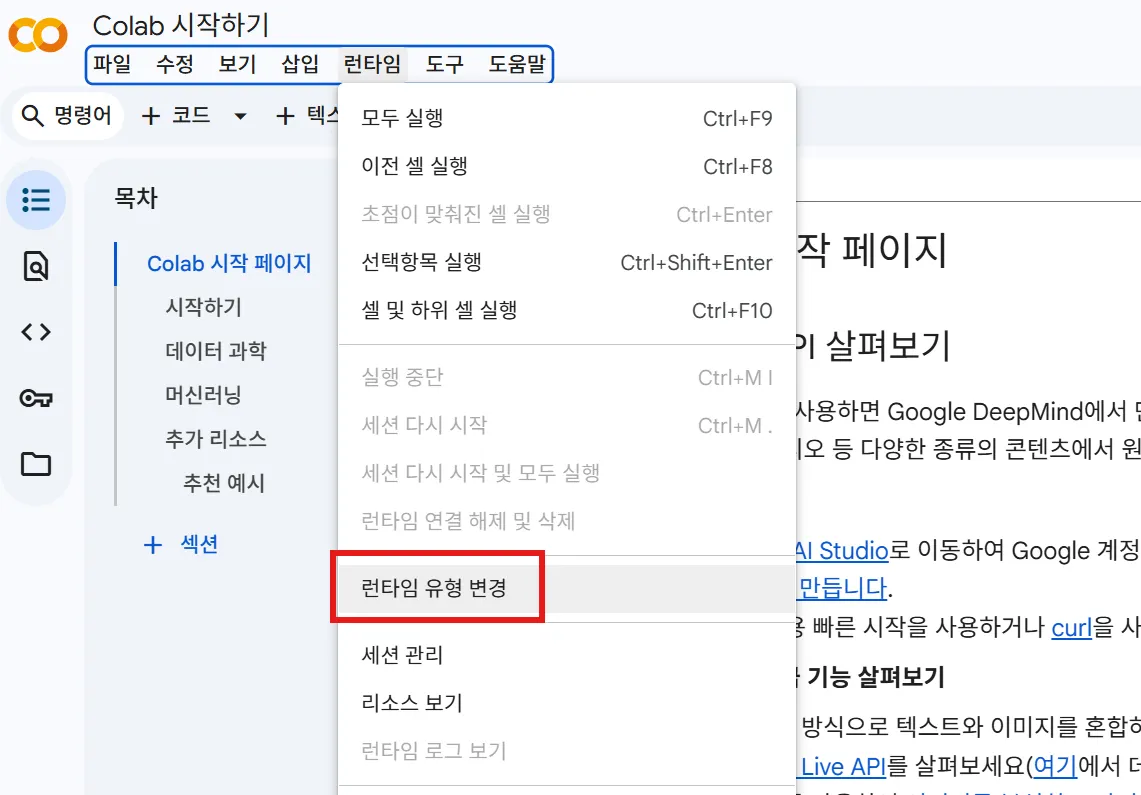
보시면 '하드웨어 가속기'가 'None'으로 되어있을 겁니다. 이걸 클릭해서 'T4 GPU'로 변경해 주세요. 이게 바로 Colab을 쓰는 이유입니다. 우리는 딥러닝 모델 훈련을 위해 이 무료 GPU를 활용할 겁니다.
보시면 이렇게 회색 영역의 '셀'들이 보입니다. Colab은 두 가지 종류의 셀이 있습니다.
하나는 지금처럼 코드를 입력하는 ‘코드 셀'이고,
다른 하나는 문서를 작성하는 '텍스트 셀'입니다. (시연: +텍스트 버튼 클릭) 텍스트 셀에는 마크다운으로 문서를 작성할 수 있습니다.
우리는 '코드 셀'에 집중하겠습니다.
실행은 간단합니다. 셀에 코드를 입력하고 Shift키와 Enter키를 동시에 누르면 됩니다.
다 같이 첫 번째 코드 셀에 print('Hello World') 라고 입력하고 실행해 볼까요?
(실행은 재생버튼 또는 Ctrl + Enter 입니다)
네, 이렇게 실행되고 결과가 나타나는 것을 코드(개발환경)를 컴퓨터가 번역하여 실행했다(런타임 환경)라고 합니다.
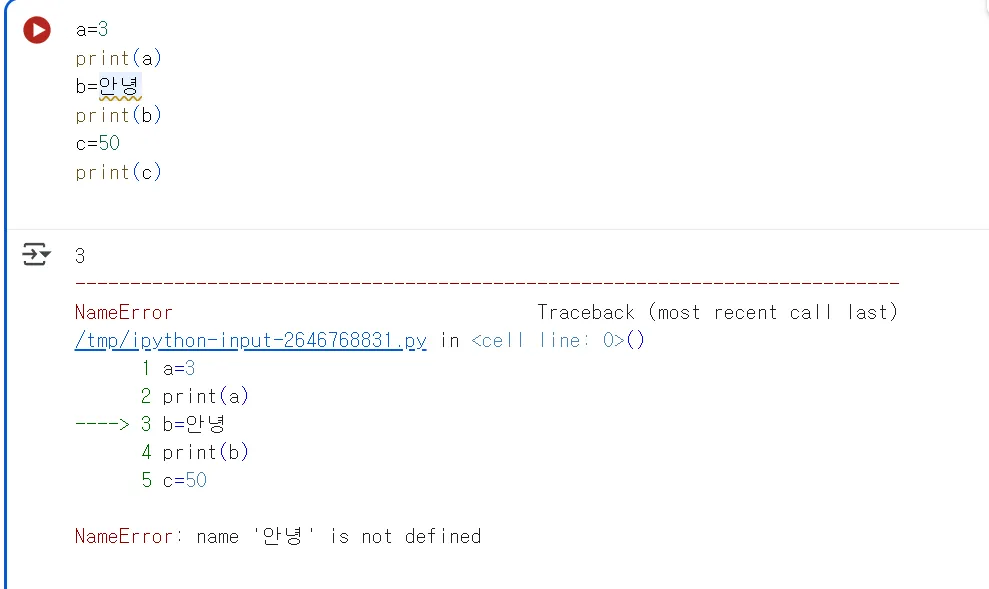
다음과 같은 코드를 작성해봅시다.
a=3
print(a)
b=안녕
print(b)
c=50
print(c)
Plain Text
복사
다음 처럼 아까와 다르게 오류가 나타날 것입니다. 예상했던것은 a, b, c로 3, 안녕, 50이 출력 될 것 같지만, 안녕이라는 문자는 문자열이라고하고 ‘’ 따옴표 또는 쌍따옴표로 감싸야 하는 문법적 규칙이 있습니다. ‘안녕’으로 수정하고 다시 실행해보면 정상적으로 작동 할 것입니다.
다시 한번 이번엔 3개를 더해봅시다.
print(a+b+c)
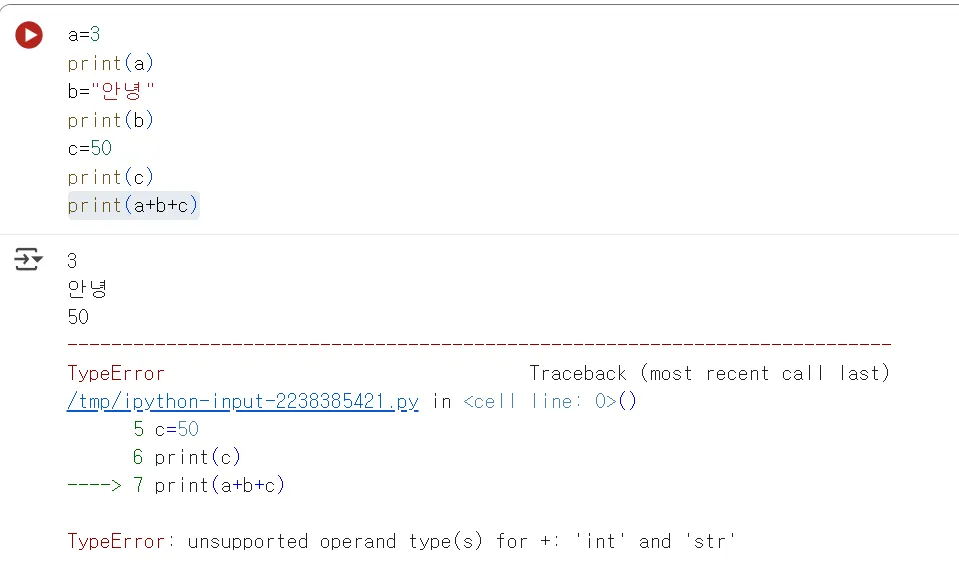
이번에도 오류가 나타날 것입니다. 아래 출력된 오류 문구를 잘 살펴보면 TypeError라고 나타나는 것을 볼 수 있습니다. 이러한 오류는 누가 어떻게 찾아내는 것일까요?
번역기 역할을 하는 것은 프로그래밍 언어(예로 파이썬, 자바 등)에 포함되어있습니다. 보통 개발환경구축을 할때(언어를 컴퓨터에 설치 할 때) 내부에 컴파일러(또는 인터프리터(언어마다 다름, 파이썬은 인터프리터/자바는 컴파일러)라는 것과 실행환경이 포함되어 개발자들이 실행하여 테스트 할 수 있도록 합니다. 또한 이것도 컴퓨터가 언어적으로 받아들이기 때문에(이 컴파일링 과정의 결과물은 기계어라하여 컴퓨터가 실행 시킬 수 있는 상태를 말합니다), 언어에서 지켜야 하는 문법이란 것이 존재하고, 그 기준이 되는 것이 각 프로그래밍 언어들입니다.
번역되는 과정을 통상적으로 컴파일 과정이라고 합니다. 번역에 오류가 발생하는 것을 컴파일 오류라고 하게됩니다. 이것은 개발자가 어떤 프로그래밍 언어로 개발하는데 실수하거나 문법과 맞지 않을때 컴파일(번역)전에 스캔을 하며 오류가 있는지 찾아주게 되는데 이를 통해 시스템을 안정적으로 개발하는데 도움을 주게 됩니다. 이러한 것을 컴파일 오류가 발생했다라고 합니다. 우리는 앞서 a,b,c가 서로 형식(타입)이 다르다는 컴파일 오류 메시지를 받았습니다. 이렇게 번역기가 자체적으로 오류를 발견하여 개발자가 쉽게 고칠 수 있도록 합니다. 어떻게 바꿀 수 있을까요?
a="3"
print(a)
b="안녕"
print(b)
c="50"
print(c)
print(a+b+c)
Plain Text
복사
숫자들을 따옴표로 감싸봅시다.
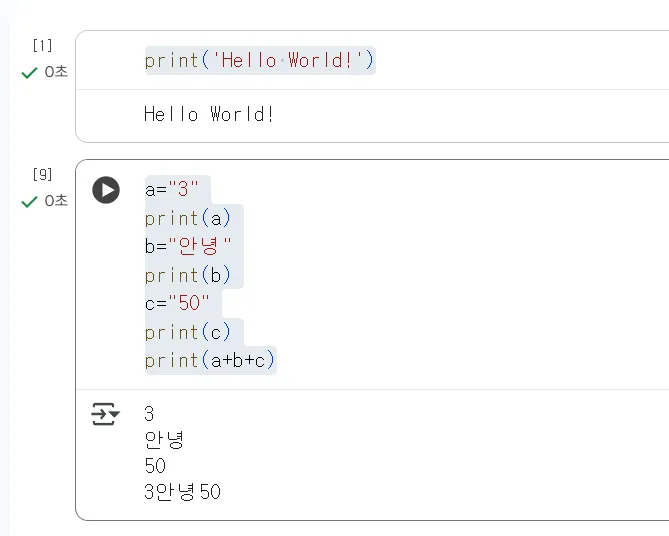
그럼 마지막줄에 3안녕50 처럼 a,b,c로 지정했던 것들이 “합쳐져” 나타납니다. 숫자로 보이지만, 숫자 자체를 “3”, “50”이라는 문자열로 바꾸어 타입을 통일 시켰기 때문에 컴퓨터는 간단하게 3개를 합치게 되었습니다. 이처럼 우리가 아는 “3”이란 문자를 컴퓨터는 3이라는 숫자로, 또는 문자로 개발자가 직접 구분을 해주어야 정확하게 인식 할 수 있습니다.
파이썬은 이런 언어적 규칙이 비교적 유연한(쉬운) 편입니다. 자바, C와 같은 타입언어라고 불리는 것들은 정확하게 그 형태를 먼저 지정해줘야하는 등 까다로운 작업이 들어가기도 합니다. 하지만 그만큼 명확한 메모리 공간을 만들기 위한 작업이기 때문에 좀 더 안정적인 시스템을 갖추는데 효과적이지요. 그리고 지정된 값들만 들어올 수 있기 때문에 메모리도 효율적으로 사용 할 수 있지요. 하지만 그만큼 개발 시간이 오래 걸릴 수 있고, 하드웨어 성능이 뒷받침 되는 경우 불필요한 복잡성을 띌 수 있습니다. 이러한 배경으로 파이썬은 보다 언어적으로 쉽게 다가갈수 있어 큰 인기를 얻게 된 언어이기도 합니다. 이와 같이 언어적으로 유연한 언어로는 파이썬과 함께 대표적으로 자바스크립트가 있습니다. 자바와는 다릅니다. 자바스크립트 또한 유연한 타입 등 자유도가 높은 것이 특징입니다. 이렇듯 언어마다 조금씩의 차이들이 있으나 결국 개발자의 코드를 실행 가능한 상태로 번역해주는 것들이 포함된 것이 프로그래밍 언어의 기본적인 공통점이라 생각하시면 좋을 것 같습니다.
다시한번 코드를 조금 수정해보겠습니다.
d라는 값을 이렇게 추가해봅시다.
그리고 숫자나 문자 아무것이나 입력해봅니다.
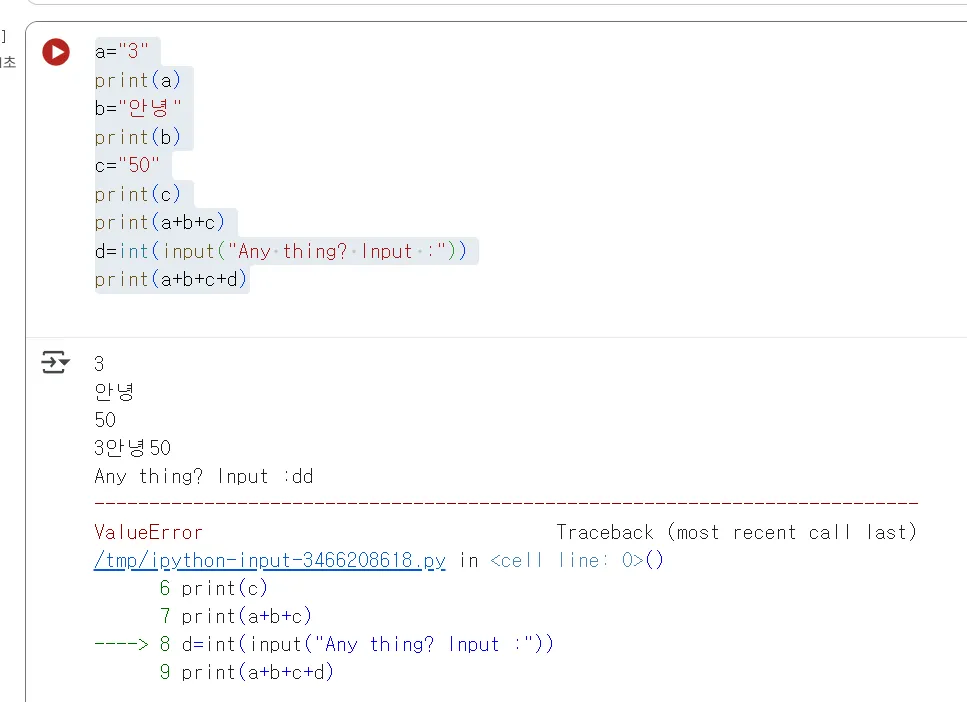
이 또한 오류가 발생 할 것입니다. 하지만 전과 다르게 실행하자마자 오류가 발생한 것이 아니라, 우리가 값을 입력 했을 때, 오류가 발생합니다.
프로그램이 번역과정에서는 오류가 없었으나 실행 중에 예상치못한 값들이 입력될 수도 있기 때문에(예로 문자를 기대했지만, 숫자가 입력될 수도 있지요) 이러한 오류는 실행중에 발생된 것이기 때문에 런타임 오류라고 합니다.
이 코드에서 앞에 int라 되어 있는 부분을 str로 바꿔봅시다.
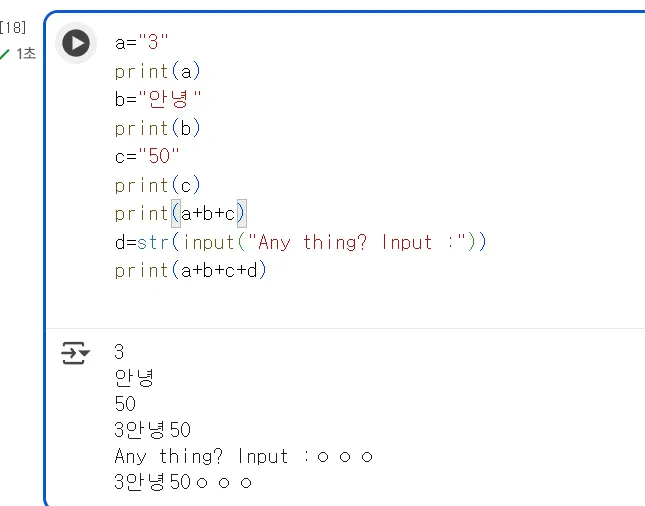
이제 정상적으로 원하는 문자열이 마지막 프린트문으로 잘 출력되는 것을 볼 수 있습니다. 물론 문자열들의 합쳐진 형태이지요. 여기서 int, str 같은 것들을 아까 말씀드렸던 데이터의 타입 이라고 합니다. int는 integer인 숫자형, str은 string의 문자열을 가리킵니다. 언어마다 조금씩 차이는 있지만 대표적으로 그 외에도 참,거짓인 0,1을 구분하는 boolean, 객체, 배열 등 타입이 대표적입니다.
그런데 처음 a=3일떄와 a=”3”일때는 이런 타입을 쓰지 않았는데도, 문자와 숫자를 컴퓨터가 구분했습니다. 네, 이러한 자유도가 높은 언어들은 따옴표 또는 기호, 생략된 표현에서 실제로 기계어로 번역할 때 기호라던지 규칙에 따라서 3이란 것을 숫자로 할지, 문자로 할지 언어가 스스로 결정하게 됩니다. 이것을 동적 타입, Dynamic Type Binding이라고 합니다. 말 그대로 값에 따라 유동적으로 타입이 바뀐다는 것이죠. 이러한 대표적인 언어가 파이썬, 자바스크립트와 같은 언어들이고, 반대로 정적 타입 언어가 바로 자바, C와 같이 타입을 지정하는 특징을 가지고 있습니다.
여기까지 아주 빠르게 파이썬의 언어적 특성과 실행을 통해 다양한 기본기 부분을 알려드렸습니다. 언어적 기본기를 모두 강의 할 수 없으나 이러한 특징들은 모든 언어들이 일정 부분 공통적으로 가지고 있기 때문에 언어를 학습 하실 때 이러한 특징을 이해하고 학습하시면 더욱 빠르게 성장 하실 수 있을 것이라 생각합니다.
개발자는 코드를 유심히 작성하면서 컴파일 오류없이 문법에 맞게 잘 기록해야하며, 또한 실행중에 예외적인 값들이 들어오면 어떻게 처리할지에 대한 부분들도 고려하면서 런타임 오류의 예외처리 등을 유심히 설계하며 개발하는 것이 프로그래머들의 역할이라고 볼 수 있습니다.
3. 실습: 핵심 라이브러리 활용
•
import pandas as pd, import numpy as np, import matplotlib.pyplot as plt.
"좋습니다. 여기까지 우리는 Colab 환경과 Python이라는 언어 자체의 특성을 빠르게 훑어봤습니다.
이제부터가 진짜입니다. 우리가 딥러닝을 하기 위해 Python을 쓰는 이유는, 방금까지 배운 기본 문법 때문이 아니라, 지금부터 배울 강력한 데이터 분석 라이브러리 생태계 때문입니다.
AI 모델을 훈련시킨다는 것은 결국 '데이터'를 다루는 일입니다. 특히 '숫자'로 이루어진 거대한 데이터 덩어리를 다뤄야 하죠.
새 코드 셀을 하나 추가하시고, 데이터 분석의 '삼대장'이라고 불리는 세 개의 라이브러리를 임포트(import)하겠습니다. 앞으로 거의 모든 AI 실습에서 이 코드는 시작처럼 사용될 겁니다."
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Markdown
복사

이처럼 import라는 명령어를 통해서 라이브러리를 이 실행환경에 로드 할 수 있습니다. 이런 것을 의존성 주입이라고도 합니다. 해당 라이브러리를 사용 할 수 있도록 준비하는 것이라 이해하시면 되겠습니다.
(Shift + Enter로 실행)
실행해보면 아무것도 안나타나겠지만, numpy, pandas, matplotlib라는 외부 의존성에 이미 다른 개발자들이 작성한 코드들을 사용 할 수 있게 됩니다.
네, 오류 없이 임포트되었습니다. as np, as pd, as plt는 이 라이브러리들을 앞으로 이 '별명(alias)'으로 부르겠다고 약속하는 개발자들 끼리 자주 사용하는 관례적인 표현입니다. 앞으로 maplotlib 처럼 긴 단어보다 plt라는 단어만으로도 저것을 지칭해서 사용 할 수 있게 됩니다.
•
NumPy:
◦
np.array(): 다차원 배열 생성.
◦
벡터/행렬 연산 (데이터의 수치적 처리).
"먼저 Numpy입니다. Numpy는 'Numerical Python'의 약자로, 파이썬에서 다차원 배열과 행렬 연산을 빠르고 효율적으로 처리하게 해주는 라이브.
딥러닝에서 모든 데이터, 특히 5일차에 다룰 이미지나 음성 데이터는 결국 이 Numpy 배열, 즉 '텐서(Tensor)'로 변환되어 처리됩니다.
파이썬 기본 리스트와 뭐가 다른지 한번 보죠. 새 코드 셀에 다음 코드를 입력해 보세요."
# 파이썬 기본 리스트
py_list = [1, 2, 3, 4, 5]
# 파이썬 리스트에 2를 곱하면?
print(f"파이썬 리스트: {py_list * 2}")
# 넘파이 배열로 변환
np_arr = np.array(py_list)
# 넘파이 배열에 2를 곱하면?
print(f"넘파이 배열: {np_arr * 2}")
Markdown
복사
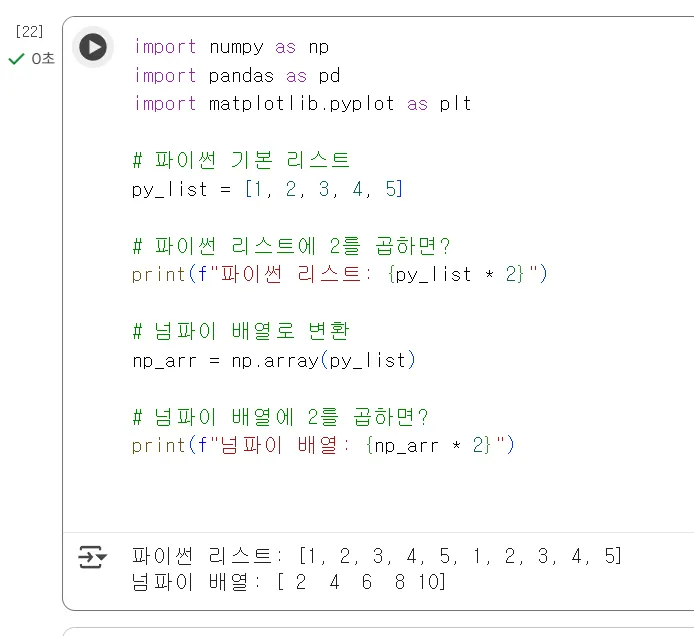
실행해보면 조금 차이가 있는 것을 알 수 있습니다.
파이썬의 기본적인 list라는 배열타입의 결과는 말그대로 배열을 두번 넣은 결과를 나타내지만
numpy의 배열을 통해서 나타난 것은 배열의 값들에 각 2를 곱한 형태를 보여줍니다. Numpy 배열은 제가 의도한 대로 '모든 요소(element)에 2를 곱하는' 수학적 연산, 이것을 벡터화 연산(Vectorized Operation)이라 하며 이 부분을 수행합니다. 이 것이 필요한 이유는 수백만 개의 데이터도 이처럼 한 번에 연산할 수 있기 때문에 딥러닝에서 필수적입니다."
"이번엔 2차원 배열, 즉 행렬을 만들어 보겠습니다.
8비트 흑백 이미지 한 장이 바로 이런 2차원 Numpy 배열입니다. 컬러 이미지는 이게 3장 겹친(3차원) 배열이 되겠죠."
# (2, 3) 형태의 2차원 배열(행렬) 생성
matrix = np.array([[1, 2, 3],
[4, 5, 6]])
print(f"2차원 배열:\n {matrix}")
# 배열의 '형태(차원)' 확인
print(f"배열의 Shape: {matrix.shape}")
Markdown
복사

(실행)
이렇게 배열안에 배열이 있는 것을 2차원 배열이라 합니다.
"결과를 보시면 (2, 3) 형태의 행렬이 출력되고, matrix.shape를 찍어보니 (2, 3)이라고 나옵니다. 2행 3열이라는 뜻이죠.
앞으로 딥러닝 모델을 다룰 때 이 shape라는 속성을 정말 수없이 확인하게 될 겁니다. 모델이 기대하는 데이터의 차원과 우리가 넣을 데이터의 차원이 정확히 일치해야 런타임 오류가 발생하지 않기 때문입니다."
•
Pandas:
◦
pd.DataFrame(): 2차원 데이터 테이블 생성.
◦
데이터 선택 (loc, iloc), 필터링 ([]), 통계 (describe()).
"다음은 Pandas입니다. Numpy가 순수한 숫자 배열 자체를 다룬다면, Pandas는 엑셀 시트 같은 2차원 테이블(표) 형태의 데이터를 다룰 때 사용합니다. 우리는 이걸 DataFrame(데이터프레임)이라고 부릅니다.
딥페이크 탐지 프로젝트를 한다고 가정하고 가상의 메타데이터(데이터를 설명하는 정보 데이터)를 만들어 보겠습니다."
# 딕셔너리(dict)로 데이터 생성
data = {
'filename': ['img_001.jpg', 'img_002.png', 'vid_001.mp4', 'aud_001.wav'],
'type': ['image', 'image', 'video', 'audio'],
'label': ['real', 'fake', 'fake', 'real'],
'file_size_mb': [1.2, 2.5, 15.3, 0.8]
}
# 딕셔너리를 DataFrame으로 변환
df = pd.DataFrame(data)
# DataFrame 출력 (Colab에서는 print() 없이 변수명만 입력해도 예쁘게 출력됩니다)
df
Markdown
복사
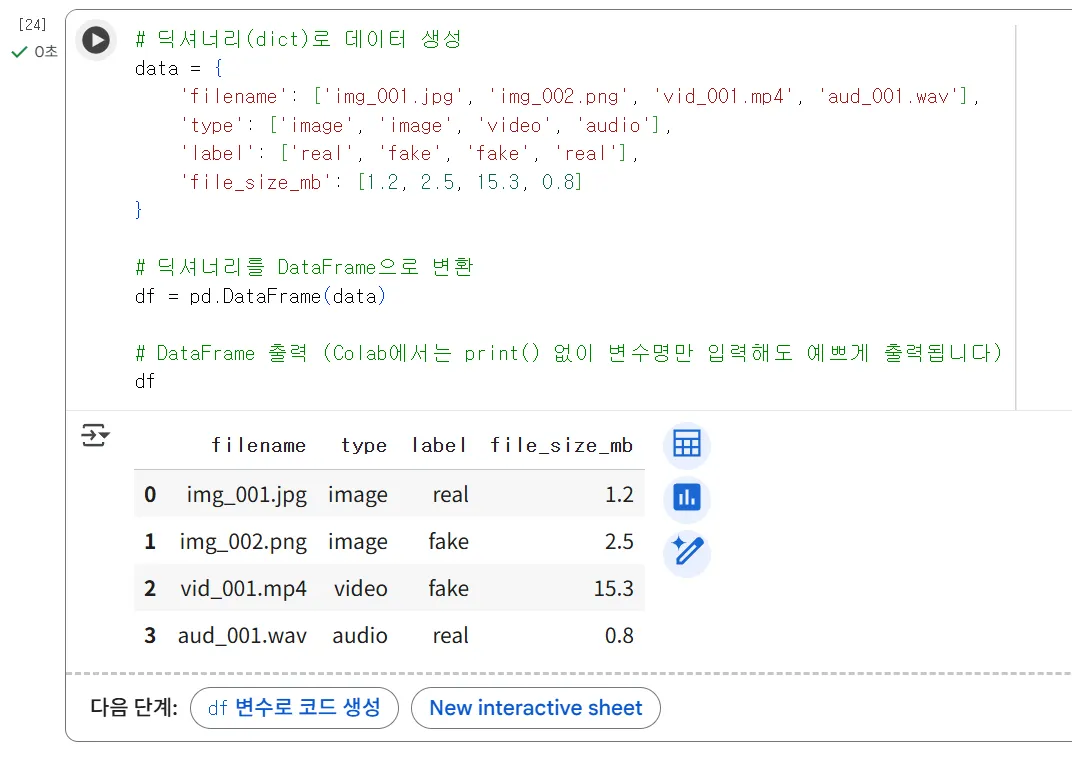
(실행) "Colab에서 실행하면 아주 깔끔한 표 형태로 출력됩니다. 이게 바로 DataFrame입니다.
여기서 잠시 딕셔너리란 데이터의 타입 중 하나인데 특이하게도 “Key”:”Value”로 구성된 특이한 구조를 가지고 있습니다. 말그대로 사전에서 어떤 단어의 뜻을 찾기 위해 목차나 단어 이름을 먼저 보는 것 처럼, Key를 통해서 Value를 찾을 수 있는 특이한 데이터 구조중 하나입니다. 웹개발을 조금이라도 경험해보신 분들은 JSON이란 데이터 형식에 대해서 보셨을 수 있는데, 이것 또한 Key:Value 형태로 구성된 모습입니다. 사실 용어로써는 어렵지만, 일상적으로 우리가 주소 : 서울시 동작구 … 처럼 쓰는 것 또한 주소라는 Key의 값이 서울시 동작구… 처럼 표현하는 것처럼 오히려 우리가 일상적으로 쓰는 것들에서 자주 볼 수 있는 데이터의 형태입니다.
AI 모델에 이미지나 음성 원본 파일을 직접 넣기 전에, 이런 Key:Value로 구성된 메타데이터를 Pandas로 관리하며 전처리를 진행합니다.
가장 많이 쓰는 기능 두 가지만 보죠. **'열(Column) 선택'**과 **'행(Row) 조건 필터링'**입니다."
# 1. 'label' 열(Column)만 선택
print("--- 레이블 열 선택 ---")
print(df['label'])
print("\n") # 줄바꿈
# 2. 'type'이 'image'인 행(Row)만 필터링 (Boolean Indexing)
print("--- type이 image인 행만 필터링 ---")
image_files_df = df[df['type'] == 'image']
print(image_files_df)
Markdown
복사

레이블이라는 열(컬럼)만 선택해보는 결과로 해당 열만 데이터가 나타납니다. 뭔가 특정 컬럼을 선택조회하는 것 같은 모습을 볼 수 있습니다.
그 다음 image인 데이터 (행(로우)만 볼 수 있도록 합니다. 타입이 == 이미지만 보려고합니다. ==는 값이 이와 같다라는 연산자 기호로 수학에서의 =과는 조금 다른것 인지 할 필요있습니다. 오히려 = 하나는 대입연산자라 하여 아까 a=10 처럼 10을 a에 넣는다(대입한다)로 이해하시면 좋을 것 같습니다. 이것은 많은 프로그래밍 언어가 공통적으로 사용하는 연산자 기호니 기억하시면 좋겠습니다.
이렇게 image인 데이터들만 출력 해 볼 수 있습니다.
(실행)
"보시는 것처럼, 'type'이 'image'인 두 개의 행만 정확히 필터링해서 가져옵니다. 결국 어떠한 데이터를 분석 할 때 데이터의 모든 정보가 아닌, 특정 부분들에 대해서 각각 분석이 필요한 경우가 많은데 이렇게 배열을 테이블화 시켜서 기능을 수행 할 수 있도록 해주는 라이브러리 입니다.
나중에 5일차에 데이터 분석(EDA)할 때, df[df['label'] == 'fake'] 같은 코드로 가짜 데이터만, 혹은 진짜 데이터만 골라내서 그 특징을 비교 분석하게 됩니다. AI 모델에 넣기 전 데이터를 정제(Cleaning)하고 탐색(EDA)할 때 Pandas는 필수입니다."
•
Matplotlib:
◦
plt.hist(): 히스토그램 (데이터 분포).
◦
plt.scatter(): 산점도 (데이터 관계).
"마지막으로 Matplotlib입니다.
'천 개의 행을 보는 것보다 한 장의 그래프가 낫다'는 말이 있죠. Matplotlib는 데이터를 시각화, 즉 그래프로 그려주는 도구입니다.
모델을 학습시키기 전에 내 데이터가 어떤 상태인지 아는 것은 매우 중요합니다.
방금 만든 DataFrame의 file_size_mb 데이터가 어떻게 분포되어 있는지 히스토그램(histogram)으로 그려보겠습니다."
# 파일 크기 분포 시각화 (히스토그램)
plt.hist(df['file_size_mb'], bins=5) # bins=5는 5개 구간으로 나눠서 보여달라는 의미
plt.title('File Size Distribution (MB)')
plt.xlabel('File Size (MB)')
plt.ylabel('Count (Frequency)')
plt.show() # 그래프를 화면에 표시
Markdown
복사
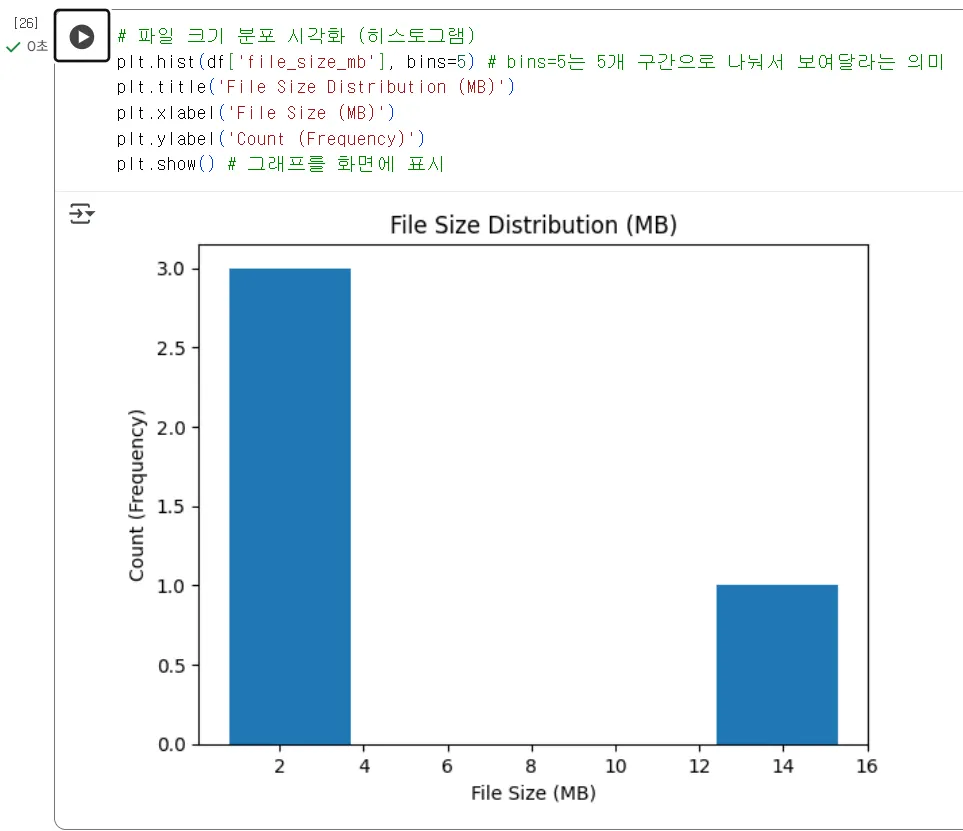
(실행) "그래프가 바로 노트에 그려집니다. 대부분의 파일이 5MB 미만에 몰려있고, 15MB가 넘는 아웃라이어(이상치)가 하나 있네요."
이처럼 손쉽게 데이터를 시각적 차트로 만드는데 효과적인 라이브러리 입니다.
"이번엔 더 중요한 것을 해보죠. 우리가 가진 데이터의 **'레이블 분포'**를 확인해 보겠습니다. 모델이 편향되지 않으려면 'real'과 'fake' 데이터의 비율이 비슷해야 합니다."
# 레이블(real/fake) 분포 확인 (Bar Plot)
label_counts = df['label'].value_counts()
print("--- 레이블 카운트 ---")
print(label_counts)
print("\n")
# Bar Plot 그리기
plt.bar(label_counts.index, label_counts.values, color=['blue', 'red'])
plt.title('Label Distribution (Real vs Fake)')
plt.ylabel('Count')
plt.show()
Markdown
복사
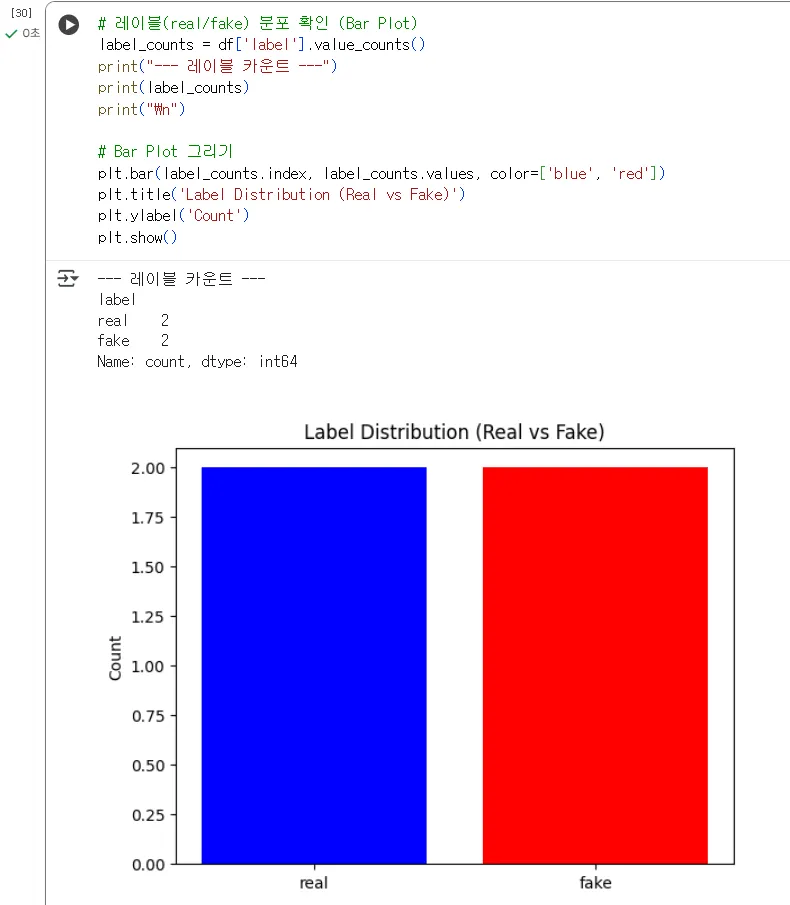
(실행)
"결과를 보니 'real'이 2개, 'fake'가 2개. 완벽하게 1:1 비율입니다. 지금은 데이터를 저희가 직접 테이블에 넣었지만 4개중 2개 곧 50% 이상 가짜인 것으로 나타납니다.
만약 'real'이 1000개인데 'fake'가 10개라면, AI 모델은 대부분 'real'이라고 찍도록 학습될 겁니다.
이런 '데이터 불균형(Imbalance)' 문제를 사전에 파악하는 것이 Matplotlib 시각화의 핵심 목적입니다."
"좋습니다. 여기까지가 모듈 2의 실습입니다.
정리하자면, 우리는
1.
Colab 환경을 세팅하고 GPU를 할당받는 법을 배웠고,
2.
Numpy로 AI 데이터의 기본 단위인 배열(추후 텐서)을 다루는 법을,
3.
Pandas로 데이터의 메타정보(표)를 다루고 필터링하는 법을,
4.
Matplotlib으로 이 데이터의 분포를 시각화하여 문제를 사전에 파악하는 법을 실습했습니다.
모듈 3: 스마트시티와 딥페이크 (이론)
1. 스마트시티의 이해
•
개념: 도시 자원을 효율적으로 활용하기 위해 ICT 기술(정보통신기술)을 도시 공간에 적용하는 것.
•
주요 기술: IoT (사물인터넷), 빅데이터, 클라우드, 5G, 디지털 트윈 (현실의 쌍둥이).
•
스마트시티 3대 주요 기술: IoT (수집), 빅데이터 (저장/처리), AI (분석/예측).
첫 번째로 스마트시티의 이해입니다.
개념 자체는 교안에 보시는 것처럼 간단합니다. '도시 자원을 효율적으로 활용하기 위해 ICT 기술, 즉 정보통신기술을 도시 공간에 적용하는 것' [cite: 170-171]입니다.
여기 계신 개발자분들의 시각으로 이 문장을 다시 해석해 볼까요?
과거의 도시가 도로, 건물, 항만 같은 '하드웨어' 중심이었다면, 스마트시티는 그 하드웨어 위에 '소프트웨어'와 '데이터'가 핵심이 되는 도시를 의미합니다.
이 ICT 기술이 구체적으로 무엇인지 보겠습니다. 이미 익숙한 용어들이 많으실 겁니다.
•
IoT (사물인터넷): 도시의 모든 '사물'입니다. CCTV, 가로등, 버스, 수도계량기에 모두 센서를 달아서 데이터를 수집하는 '눈'과 '귀' 역할을 합니다.
•
빅데이터: 이 수많은 IoT 장치에서 1초에도 수백만 건씩 쏟아지는 정형, 비정형 데이터를 저장하고 처리하는 '거대한 창고'입니다.
•
클라우드: 이 모든 인프라를 구동하기 위한 유연하고 확장 가능한 '가상 서버' 환경이죠.
•
5G: 이 모든 대용량 데이터를 '끊김 없이' 실시간으로 전송하는 초고속 통신망, 즉 '혈관'입니다.
•
디지털 트윈: 그리고 이 모든 것을 가상 공간에 '쌍둥이'처럼 복제해서 시뮬레이션하는 '가상 모델'입니다.
이 많은 기술 중에, 우리가 만들 시스템 아키텍처와 가장 밀접한 3대 핵심 기술을 꼽으라면 바로 이 세 가지입니다.
•
*IoT가 '수집'하고, 빅데이터가 '저장/처리'하며, AI가 '분석/예측'**합니다.
이건 우리가 흔히 아는 완벽한 **데이터 파이프라인(Data Pipeline)**입니다.
1.
도시의 CCTV(IoT)가 영상을 수집합니다.
2.
이 영상 데이터가 데이터 레이크(Big Data)에 저장됩니다.
3.
바로 이 지점에서 AI가 분석을 시작합니다. '이 영상에 사고가 났는가?', '이 교통 흐름을 보니 30분 뒤 정체가 예상된다.'
그리고 우리 과정의 핵심이죠. '이 비대면 인증 영상의 인물이 딥페이크인가?'
우리가 3일차, 4일차에 배울 React와 NestJS는, 이 거대한 파이프라인의 '최종 결과물'을 사용자와 관리자에게 보여주는 애플리케이션 레이어(Application Layer)를 구축하는 작업입니다.
결국 스마트시티의 핵심 자원은 '데이터'이며, 이 데이터를 '지능적'으로 처리하여 가치를 만드는 것이 바로 AI의 역할입니다.
그럼, 이 AI가 스마트시티에서 구체적으로 어떻게 더 활용되는지, 다음 장에서 '스마트시티와 AI의 연관성'을 좀 더 자세히 살펴보겠습니다.
2. 스마트시티와 AI의 연관성
•
스마트 모빌리티: 교통량 예측, 자율주행, 스마트 파킹.
•
스마트 에너지: AMI 기반 수요 예측, 에너지 관리.
•
스마트 안전: 지능형 CCTV, 재난 예측, 사고 감지.
"앞서 우리는 스마트시티를 '데이터 파이프라인'으로 정의하고, AI가 바로 이 데이터의 '분석과 예측'을 담당하는 핵심 두뇌라고 말씀드렸습니다.
그럼 이 두뇌가 구체적으로 어떤 '서비스'를 만들어내는지, 대표적인 세 가지 분야를 통해 AI와의 연관성을 살펴보겠습니다."
"첫 번째는 스마트 모빌리티입니다.
가장 직관적인 분야죠. AI는 도시의 이동을 더 빠르고, 안전하고, 효율적으로 만듭니다."
•
교통량 예측: 이건 어떻게 할까요? 도시 전역의 CCTV와 바닥 센서(IoT)에서 실시간 교통 데이터를 수집합니다. 그리고 이 데이터를 과거의 교통 패턴, 날씨, 행사 정보와 결합하죠. 이건 전형적인 '시계열 예측' 문제입니다. 우리가 앞서 배운 RNN(순환 신경망) 계열의 모델이 바로 이 예측을 수행합니다. '30분 뒤 A지점은 80% 확률로 정체됩니다.'라고 알려주는 것이죠.
•
자율주행: 자율주행차 한 대는 그 자체가 움직이는 소형 스마트시티입니다. 전방 카메라와 라이다(LiDAR) 센서로 주변 환경 데이터를 수집하죠. 그리고 우리가 배운 **CNN(합성곱 신경망)**을 이용해 이 카메라 영상에서 차선, 보행자, 신호등을 실시간으로 '인식'하고 '탐지'합니다.
•
스마트 파킹: 주차장의 CCTV가 비어있는 주차 공간을 실시간으로 분석합니다. 이것 역시 CNN이 영상 속 '빈 공간'과 '차가 있는 공간'이라는 객체를 탐지하는 것입니다.
"두 번째는 스마트 에너지입니다.
이건 '효율성'에 대한 문제입니다."
•
AMI (Advanced Metering Infrastructure): 용어는 어렵지만, 쉽게 말해 '스마트 계량기'입니다. 각 가정의 전력 사용량을 실시간으로 수집하는 IoT 장치죠.
•
수요 예측: 이 AMI 데이터와 날씨 데이터를 결합하면, AI가 '내일 오후 2시, A 구역의 전력 수요는 이만큼 급증할 것이다'라고 예측할 수 있습니다. 이것도 '시간'에 따른 예측이니 RNN 계열 모델의 주특기입니다. 도시 전체의 전력망을 효율적으로 관리하고 정전을 예방하는 핵심 기술입니다.
"마지막으로, 우리 과정과 가장 밀접한 스마트 안전 분야입니다."
"이 분야가 바로 우리가 딥페이크 탐지 프로젝트를 하는 이유와 직결됩니다."
•
지능형 CCTV: 기존 CCTV는 그저 '녹화'만 합니다. 하지만 '지능형' CCTV는 AI, 즉 CNN 모델을 통해 영상을 실시간으로 '이해'합니다. 영상 속에서 '쓰러진 사람', '화재', '무단 침입자' 같은 특정 '이벤트'를 스스로 탐지하고 즉시 관제 센터에 알람을 보냅니다.
•
재난 예측 및 사고 감지: 하천의 수위 센서 데이터나 교량의 진동 데이터를 RNN으로 분석하여 홍수나 붕괴 징후를 예측하거나, CNN이 사고 현장을 즉시 탐지합니다.
"자, 그럼 생각해 보죠. 이 모든 '스마트 안전' 시스템은 **'AI가 보고 듣는 것을 신뢰한다'**는 전제 위에 구축되어 있습니다.
그런데 만약, 누군가가 스마트 홈의 CCTV 영상 자체를 '딥페이크 영상'으로 바꿔치기해서 침입한다면 어떨까요?
혹은, 우리가 2일차에 기획하고 5-6일차에 만들 시스템처럼, 비대면 민원 서비스나 보안 시스템에 '딥보이스', 즉 합성된 음성으로 인증을 시도한다면 어떻게 될까요?
스마트시티의 '안전'과 '신뢰'가 한순간에 무너질 것입니다.
이것이 바로 우리가 딥페이크 '탐지' 기술을 배우는 이유입니다. 딥페이크 탐지는 단순한 AI 응용 기술 중 하나가 아니라, 미래 스마트시티의 핵심 보안 인프라 중 하나입니다.
"여기까지 AI가 스마트시티의 3대 핵심 분야에서 어떻게 활용되는지 알아봤습니다.
하지만 이렇게 편리한 AI 기술에는 명확한 '위협'이 존재합니다.
다음 장에서는 우리 과정의 핵심 주제인 '딥페이크 기술의 원리'와 이것이 왜 '사회적 문제'가 되는지 자세히 알아보겠습니다."
3. 딥페이크 기술과 사회적 문제
•
딥페이크(Deepfake)란?
◦
딥러닝(DL) + 페이크(Fake).
◦
AI를 활용해 특정 인물의 얼굴, 음성을 합성하는 기술.
◦
주요 기술: GANs (생성적 적대 신경망) - 생성기와 판별기의 경쟁 학습 [cite: 1721-1724].
"앞서 스마트시티의 안전을 위협하는 존재로 '딥페이크'를 언급했습니다. 그럼 이 딥페이크가 정확히 무엇이고, 어떤 원리로 동작하며, 왜 그렇게 심각한 사회적 문제가 되는지 짚어보겠습니다."
"먼저 딥페이크(Deepfake)란 무엇인가?
용어 자체는 매우 직관적입니다. '딥러닝(Deep Learning)'과 '페이크(Fake)'의 합성어죠.
즉, AI를 활용해 특정 인물의 얼굴이나 음성을 매우 정교하게 합성하는 기술을 말합니다."
"그렇다면 AI는 어떻게 이렇게 감쪽같은 가짜를 만들어내는 걸까요?
물론 딥페이크를 만드는 모델은 다양하지만, 그 기술의 핵심에는 'GANs', 즉 '생성적 적대 신경망(Generative Adversarial Networks)'이라는 모델이 있습니다."
"이 GAN이라는 이름이 좀 어렵게 들릴 수 있는데, 아주 간단한 비유로 설명할 수 있습니다.
GAN은 두 명의 플레이어가 경쟁하며 서로를 성장시키는 구조입니다."
"
바로 **'생성기(Generator)'**와 **'판별기(Discriminator)'**입니다."
•
"**생성기(Generator)**는 **'위조지폐범'**이라고 생각하시면 됩니다. 이 모델의 목표는 '진짜 같은 가짜 돈(딥페이크 이미지)'을 만들어내는 것입니다."
•
"**판별기(Discriminator)**는 '경찰' 또는 '은행 감별사'입니다. 이 모델의 목표는 '진짜 돈(원본 이미지)'과 생성기가 만든 '가짜 돈(딥페이크)'을 구별해내는 것입니다."
"학습은 이 둘의 **'경쟁'**을 통해 이루어집니다."
"1. 처음에 '위조지폐범(생성기)'은 아주 조악한 가짜 돈을 만듭니다.
2. 그럼 '경찰(판별기)'은 너무 쉬워서 바로 '이건 가짜야!'라고 잡아냅니다. [cite: 1725]
3. '위조지폐범(생성기)'은 자신이 만든 가짜 돈이 왜 걸렸는지 피드백을 받고, 다음엔 더 정교한, 즉 경찰을 속일 수 있는 가짜 돈을 만듭니다.
4. '경찰(판별기)'도 가만히 있지 않죠. 더 정교해진 가짜를 구별해내기 위해 자신의 감별 능력(패턴 인식)을 더 고도화합니다.
5. 이 경쟁이 수백만 번 반복되면, 결국 '위조지폐범(생성기)'은 경찰이 거의 구별하기 힘든 '슈퍼노트' 수준의 딥페이크를 만들게 되고, '경찰(판별기)' 역시 아주 미세한 차이도 감지해내는 최고의 감별사가 됩니다."
"우리가 5일차, 6일차에 만들 '탐지 모델'이 바로 이 '경찰(판별기)'의 역할을 수행하는 것입니다. 이미 고도로 훈련된 판별기 모델을 활용하거나, 우리 스스로 판별기를 훈련시키게 됩니다."
•
사회적 문제점
◦
가짜 뉴스, 여론 조작.
◦
명예 훼손, 디지털 성범죄.
◦
보이스피싱, 금융 사기 (신원 도용).
"문제는, 이 기술이 너무 정교해지면서 심각한 사회적 문제를 일으킨다는 점입니다."
•
가짜 뉴스 및 여론 조작: 특정 정치인이 하지도 않은 말을 하는 딥페이크 영상을 선거 직전에 유포한다면, 진실을 바로잡기 전에 이미 여론은 조작될 수 있습니다.
•
명예 훼손 및 디지털 성범죄: 특정 개인의 얼굴을 불법적인 영상물에 합성하여 유포하는 심각한 범죄에 악용되고 있습니다.
•
보이스피싱 및 금융 사기 (신원 도용): 이것이 스마트시티 환경에서 가장 즉각적인 위협입니다. '딥보이스' 기술은 단 몇 초의 음성만 있으면 특정인의 목소리를 완벽하게 복제할 수 있습니다. 만약 AI가 부모님이나 회사 대표의 목소리로 '급히 돈이 필요하니 이체해달라'고 전화를 건다면, 속아 넘어갈 확률이 매우 높겠죠.
"이처럼 딥페이크는 스마트시티가 추구하는 '신뢰'와 '안전'이라는 가치를 근본적으로 위협합니다."
"그렇다면 스마트시티 환경에서 구체적으로 어떤 위협이 더 있을까요?
다음 장에서 '스마트시티에서의 딥페이크 위협'을 좀 더 구체적으로 살펴보겠습니다."
4. 스마트시티에서의 딥페이크 위협
"앞서 보이스피싱이나 가짜 뉴스 같은 일반적인 딥페이크 문제점들을 살펴봤습니다.
이번 장에서는 이 딥페이크가 우리가 구축하려는 '스마트시티' 환경에서 구체적으로 어떤 위협이 되는지, 두 가지 핵심 분야를 짚어보겠습니다."
"첫 번째는 보안 및 신원 확인 분야입니다.
스마트시티는 효율성을 위해 수많은 '비대면(Untact)' 서비스를 전제로 합니다. [cite: 3-5]
예를 들어, 우리가 2일차에 기획할 **'비대면 민원 상담'**이나 '온라인 행정 처리'가 있죠."
"바로 이 지점에서 딥페이크는 '신원 도용'의 완벽한 도구가 됩니다. [cite: 3-5]
누군가 악의를 가지고 특정인의 영상과 음성을 딥페이크로 합성해서, 비대면 인증 시스템에 접속을 시도한다고 상상해 보십시오. AI 인증 시스템이 이걸 잡아내지 못한다면, 개인정보 유출은 물론이고 공공 서비스 계정이 탈취될 수 있습니다."
"더 구체적인 예는 **'스마트 홈 출입 시스템'**입니다. [cite: 3-5]
얼굴 인식 카메라(CCTV)가 현관문의 잠금장치 역할을 합니다.
만약 누군가 집주인의 얼굴을 딥페이크로 합성한 영상을 카메라에 비춰서 이 시스템을 통과할 수 있다면, 이건 물리적인 '해킹'과 다름없습니다."
"두 번째는 의료 및 복지 분야입니다.
이것은 신원 도용을 넘어 생명과 안전에 직결될 수 있습니다."
•
비대면 의료: 팬데믹 이후 원격 진료가 활성화되고 있습니다. 딥페이크 기술로 환자 본인 확인 시스템을 통과하여 [cite: 3-5] 향정신성 의약품을 대리 처방받거나, 타인의 민감한 의료 정보를 유출시킬 수 있습니다.
•
AI 기반 약자 관리 시스템: 교수설계서(HWP)에도 언급된 '고독사 예방 시스템'을 예로 들어보죠. [cite: 3-5] AI가 독거 어르신의 방 안 카메라를 모니터링하며 응급 상황을 감지합니다. 만약 이 시스템이 딥페이크 영상(예: 평화롭게 잠자는 모습)에 교란되어 실제 응급 상황을 놓친다면, AI가 오히려 안전을 방해하는 꼴이 됩니다.
"이처럼 딥페이크는 스마트시티의 **'인증(Authentication)'**과 **'신뢰(Trust)'**라는 가장 밑단의 기반을 공격합니다."
"(결론 강조) 따라서, 스마트시티의 안전한 운영을 위해 '딥페이크 탐지' 기술은 선택이 아닌 필수입니다. [cite: 3-5]
우리가 만들 웹 애플리케이션은, 바로 이 스마트시티의 보안 인프라를 구축하는 파일럿 프로젝트입니다.
"좋습니다. 이론은 여기까지입니다. 1일차의 이론 파트가 모두 끝났습니다.
이제 마지막에는, 이 딥페이크를 탐지하기 위한 첫걸음이죠. 실제 **'딥페이크 데이터'**가 어떻게 생겼는지 Colab 환경에서 직접 우리 눈으로 보고, 코드로 분석해보는 두 번째 실습을 진행하겠습니다."
•
보안 및 신원 확인:
◦
비대면 민원 상담, 공공 서비스 이용 시 신원 도용.
◦
스마트 홈 출입 시스템 해킹.
•
의료 및 복지:
◦
비대면 의료 진단 시 환자 오인, 의료 정보 유출.
◦
AI 기반 약자 관리 시스템(고독사 예방 등) 교란.
•
결론: 스마트시티의 안전한 운영을 위해 딥페이크 '탐지' 기술이 필수적임.
모듈 4: 실습 2 - 딥페이크 데이터 분석 및 토론
1. 실습 목표
•
딥페이크 데이터(음성, 이미지)의 시각적/청각적 특징 이해.
•
데이터 특징 분석(EDA) 및 탐지 모델 개발 아이디어 도출.
"1일차의 마지막 모듈, '딥페이크 데이터 분석' 실습
지금까지 우리는 AI, 스마트시티, 딥페이크의 '이론'을 배웠고, Colab, Numpy, Pandas 같은 '도구'도 준비했습니다.
이제, **'우리의 적(Problem)'**인 딥페이크 데이터가 실제로 어떻게 생겼는지 직접 보고, 듣고, 코드로 분해해 보겠습니다."
"이번 실습의 목표는 명확합니다.
첫째, 우리(사람)의 눈과 귀로 딥페이크의 시각적, 청각적 특징(어색함)을 이해합니다.
둘째, AI(코드)의 눈으로 이 특징을 데이터 분석(EDA)하여, 탐지 모델의 아이디어를 도출합니다."
2. 딥페이크 샘플 식별 및 토론
•
시청 및 분석: 딥페이크 샘플 영상 시청.
◦
Check Point: 부자연스러운 눈 깜빡임, 입 모양 불일치, 피부 톤 경계, 미세한 깜빡임(artifact).
•
토론:
◦
딥페이크 기술의 긍정적/부정적 측면.
◦
스마트시티 적용 시 예상되는 가장 큰 위협은?
1. 딥페이크 샘플 식별 및 토론
"AI 모델을 훈련시키기 전에, 가장 좋은 탐지기는 바로 우리 자신입니다. 우리가 먼저 데이터의 특징을 알아야 AI에게 무엇을 학습시킬지 알 수 있겠죠.
(강사: 미리 준비한 딥페이크 샘플 영상 2~3개를 재생)"

"(영상 시청 후) 자, 어떠신가요? 방금 보신 영상이 진짜일까요, 가짜(딥페이크)일까요?
...
네, 맞습니다. 전부 딥페이크입니다.
그럼 **'어떤 부분'**을 보고 가짜라고 판단하셨나요?
(수강생 답변 유도: 눈을 잘 안 깜빡인다, 입 모양이 어색하다, 얼굴 경계가 흐릿하다 등)"
"정확합니다. 여러분이 지금 말씀해 주신 것들이 바로 딥페이크 탐지의 **핵심 체크포인트(Check Point)**입니다."
•
부자연스러운 눈 깜빡임: 초기 딥페이크 모델은 눈 깜빡이는 데이터를 제대로 학습하지 못했습니다.
•
입 모양 불일치(Lip Sync): 음성과 입 모양이 미세하게 맞지 않는 경우가 있습니다.
•
피부 톤 경계: 합성된 얼굴과 원래 목의 피부 톤이 미세하게 다릅니다.
•
미세한 깜빡임(Artifact): 화면 전환이나 얼굴이 빠르게 움직일 때, 픽셀이 깨지거나 '지글거리는' 현상이 나타납니다.
"우리는 이런 시각적 오류를 통틀어 **'아티팩트(Artifact)'**라고 부릅니다.
딥페이크 탐지 모델(CNN)은 결국 이 '아티팩트'를 찾아내도록 훈련되는 것입니다."
"그럼 이 기술이 앞서 모듈 3에서 배운 스마트시티와 결합될 때, 어떤 위협이 있을지 다시 한번 토론해 볼까요?
(수강생 토론 유도: 비대면 인증, CCTV 해킹, AI 복지 시스템 교란 등)"
3. 실습: 데이터 특징 분석 (EDA)
•
음성 (DeepVoice) 분석
◦
라이브러리: librosa (음성 처리), matplotlib (시각화).
◦
librosa.load(): 음성 파일 로드.
◦
시각화 1: Waveform (파형)
▪
시간에 따른 소리의 진폭.
◦
시각화 2: Spectrogram (스펙트로그램)
▪
시간에 따른 주파수 에너지 분포 (음성의 '지문').
◦
분석: 정상 음성과 합성 음성의 주파수 대역 차이, 배경 노이즈 패턴 비교.
2. 실습: 데이터 특징 분석 (EDA) - 음성 (DeepVoice)
"좋습니다. 이제 우리 눈으로 본 아티팩트를, 코드로 확인해 보겠습니다.
다시 Colab으로 돌아가서 새 코드 셀을 준비해 주세요.
# librosa 설치 (Colab에 기본 설치되어 있으나, 최신 버전 확인차)
!pip install librosa
import librosa
import librosa.display # 시각화용
import matplotlib.pyplot as plt
import numpy as np
# (강사: 수강생에게 샘플 'sample_origin.mp3'와 'sample_changer.mp3' 파일 제공 또는 URL)
# 예시: librosa에 내장된 샘플 데이터 로드
real_path = '/sample_origin.mp3'
fake_path = '/sample_changer.mp3' # (가정) 이것이 딥페이크라고 가정
Markdown
복사
먼저 '딥보이스(음성)' 분석입니다.
음성 데이터를 다룰 때는 librosa라는 라이브러리를 사용합니다. 오디오계의 Pandas라고 생각하시면 됩니다."
우선 샘플 파일을 콜랍 실행 환경에 업로드합니다.
"먼저, librosa.load() 함수로 음성 파일을 로드합니다.
이 함수는 두 가지를 반환합니다. 하나는 'y'라고 부르는 **음성 데이터 배열(Numpy array)**이고, 다른 하나는 'sr'이라고 부르는 **샘플 레이트(Sample Rate)**입니다."
# 음성 파일 로드
y_real, sr_real = librosa.load(real_path)
y_fake, sr_fake = librosa.load(fake_path)
print(f"Real 음성 Shape: {y_real.shape}, Sample Rate: {sr_real}")
print(f"Fake 음성 Shape: {y_fake.shape}, Sample Rate: {sr_fake}")
Markdown
복사
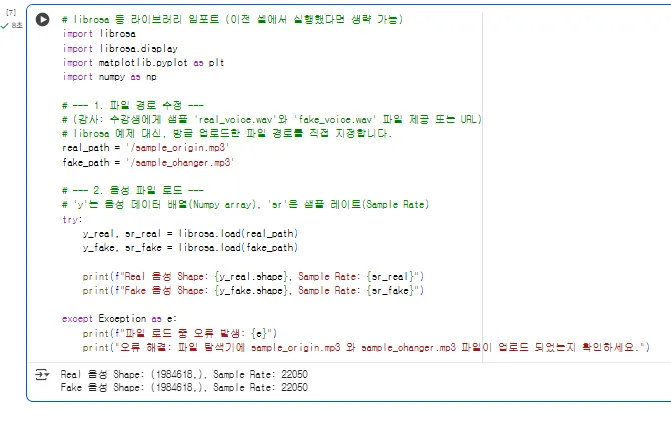
이것중 변조된 음성은 파일의 크기 정도로 구분 할 수 없게 됩니다.
"이제 이 데이터로 아까와 동일하게 **Waveform(파형)**과 **Spectrogram(스펙트로그램)**을 시각화해 보겠습니다. 아래 코드는 아까와 동일하지만, 이제 실제 '원본'과 '변조' 데이터로 그려집니다.”
# --- 3. 시각화 1: Waveform (파형) ---
# 시간에 따른 소리의 진폭 비교
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
librosa.display.waveshow(y_real, sr=sr_real)
plt.title('Real Voice (Origin) Waveform')
plt.subplot(1, 2, 2)
librosa.display.waveshow(y_fake, sr=sr_fake)
plt.title('Fake Voice (Changer) Waveform')
plt.tight_layout()
plt.show()
Markdown
복사
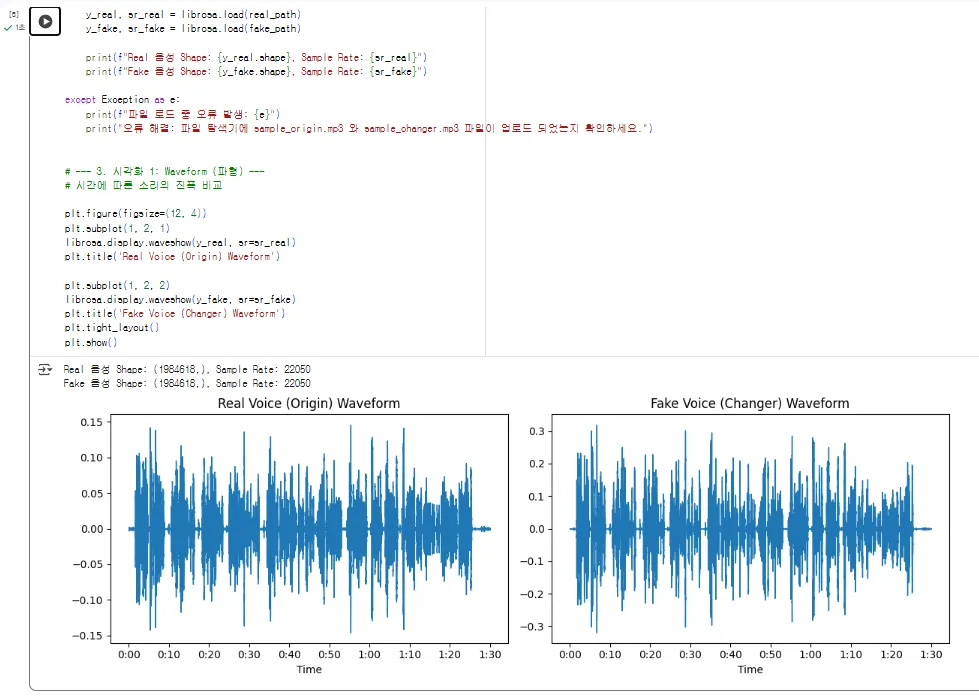
이제 실제 웨이브를 통해 살펴보니 무언가 조작된 미세한 차이들이 실제로 시각적으로 보여지게 됩니다.
(실행)
"Waveform을 보니... 어떤가요? sample_changer.mp3 파일이 아마 '전화 효과' 같은 변조라고 하셨는데, 원본(Origin)에 비해 진폭(소리 크기)이 일정하게 잘려나간(Clipping) 모습이 보일 수도 있습니다. 하지만 여전히 파형만으로는 구별이 쉽지 않죠."
"그래서 **'음성의 지문'**인 멜 스펙트로그램으로 다시 확인해 보겠습니다."
# --- 4. 시각화 2: Mel Spectrogram (음성의 지문) ---
# 멜 스펙트로그램 추출
S_real = librosa.feature.melspectrogram(y=y_real, sr=sr_real)
S_fake = librosa.feature.melspectrogram(y=y_fake, sr=sr_fake)
# 로그 스케일로 변환 (dB) - 시각화에 용이
S_real_db = librosa.power_to_db(S_real, ref=np.max)
S_fake_db = librosa.power_to_db(S_fake, ref=np.max)
# 멜 스펙트로그램 시각화
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
librosa.display.specshow(S_real_db, sr=sr_real, x_axis='time', y_axis='mel')
plt.title('Real Voice (Origin) - Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.subplot(1, 2, 2)
librosa.display.specshow(S_fake_db, sr=sr_fake, x_axis='time', y_axis='mel')
plt.title('Fake Voice (Changer) - Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.tight_layout()
plt.show()
Markdown
복사
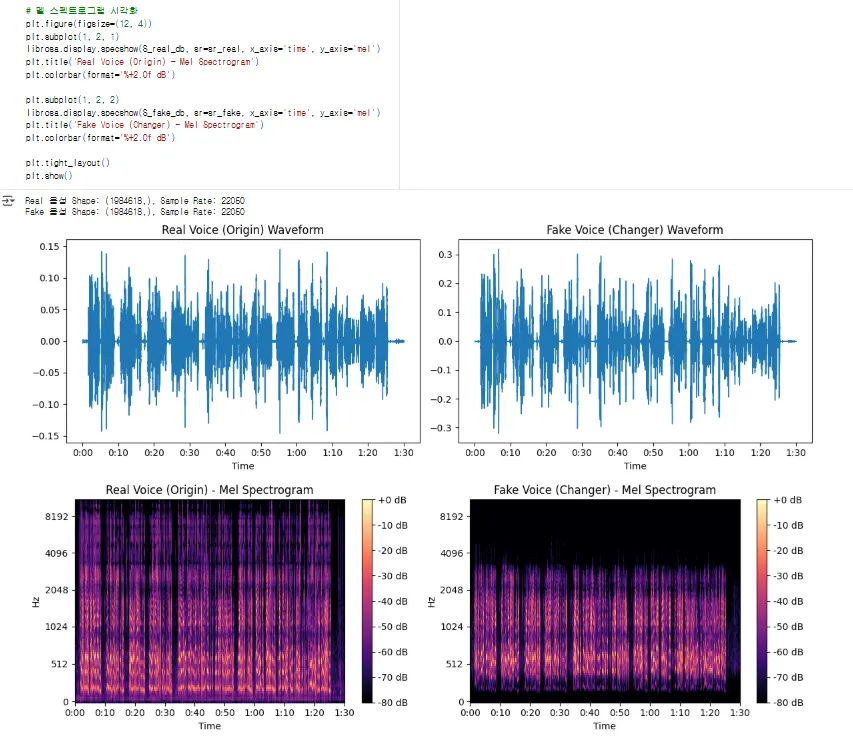
(실행)
"자, 이제 차이가 명확하게 보이실 겁니다.
원본(Origin) 음성은 저주파(아래쪽)부터 고주파(위쪽)까지 에너지(노란색)가 풍부하게 분포되어 있습니다.
하지만 '전화 효과(Changer)'가 적용된 가짜 음성을 보세요.
전화망은 음성 통화에 불필요한 고주파 대역과 저주파 대역을 의도적으로 잘라냅니다. 그래서 보시는 것처럼 상단(고주파)과 하단(저주파)의 에너지 밴드가 완전히 잘려나가고(cutoff), 음성이 존재하는 중간 대역만 남아있는 것을 볼 수 있습니다."
"딥보이스 탐지 모델(RNN/CNN)은 바로 이 **'주파수 대역의 인위적인 왜곡'**이나 **'잘려나간 패턴'**을 학습하여 '아, 이건 정상적인 마이크로 녹음된 소리가 아니라, 변조되었거나 합성된 음성이구나'라고 탐지하게 됩니다. "딥보이스 탐지 모델(RNN)은 바로 이 스펙트로그램의 시간적 패턴을 학습하여 이질감을 찾아냅니다."
이것이 EDA 실습의 핵심입니다."
•
이미지 (DeepFake) 분석
◦
라이브러리: OpenCV (cv2), matplotlib.
◦
cv2.imread(): 이미지 파일 로드.
◦
시각화: plt.imshow()로 이미지 출력.
◦
분석: 확대(Zoom-in)를 통한 얼굴 경계면, 눈/코/입 주변의 픽셀 깨짐(artifact) 확인.
3. 실습: 데이터 특징 분석 (EDA) - 이미지 (DeepFake)
"이번엔 **'딥페이크 이미지'**를 분석해 보겠습니다.
이미지 처리는 'OpenCV' (별칭 cv2)를 사용합니다. 이미지/영상 처리의 표준 라이브러리죠."
우선 아래 2개 이미지를 업로드합니다.


# OpenCV와 Matplotlib 라이브러리 임포트
# (이전 셀에서 실행했다면 생략 가능)
import cv2
import matplotlib.pyplot as plt
import numpy as np # 이미지도 결국 Numpy 배열입니다.
# --- 1. 파일 경로 설정 ---
# Colab에 업로드한 실제 파일명으로 지정합니다.
real_path = 'sample_origin.jpg'
fake_path = 'sample_changer.jpg'
# --- 2. 이미지 파일 로드 ---
img_real = cv2.imread(real_path)
img_fake = cv2.imread(fake_path)
# 파일이 정상적으로 로드되었는지 shape를 확인합니다.
# (만약 여기서 'NoneType' 오류가 나면, 파일명 오타나 업로드 누락입니다.)
try:
print(f"Real Image Shape: {img_real.shape}") # (높이, 너비, 3)
print(f"Fake Image Shape: {img_fake.shape}")
except AttributeError:
print("[오류] 파일명(real_path, fake_path)을 확인하거나 Colab에 파일이 업로드되었는지 확인하세요.")
Markdown
복사

(실행)
"네, 두 이미지의 shape가 (높이, 너비, 3)의 형태로 잘 출력되었습니다. 마지막 '3'은 빛의 3원색인 Red, Green, Blue 채널을 의미합니다."
"이제 plt.imshow()로 이미지를 Colab에 띄워보겠습니다.
그런데 OpenCV를 처음 쓸 때 99% 확률로 겪는 아주 유명한 함정이 하나 있습니다. 일단 보시죠."
# --- 3. BGR -> RGB 문제 확인 (OpenCV 함정) ---
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img_real)
plt.title('Real Image (BGR?)') # 색감이 이상하게 보일겁니다.
plt.subplot(1, 2, 2)
plt.imshow(img_fake)
plt.title('Fake Image (BGR?)')
plt.show()
Markdown
복사
(실행)
"자, 이미지가 뜨긴 떴는데... 혹시 사람 얼굴이 있다면 전부 파랗게 질린 것처럼 보일 겁니다.
(강사님 사진 예시: "제 사진도 파란색으로 이상하게 나왔네요.")"
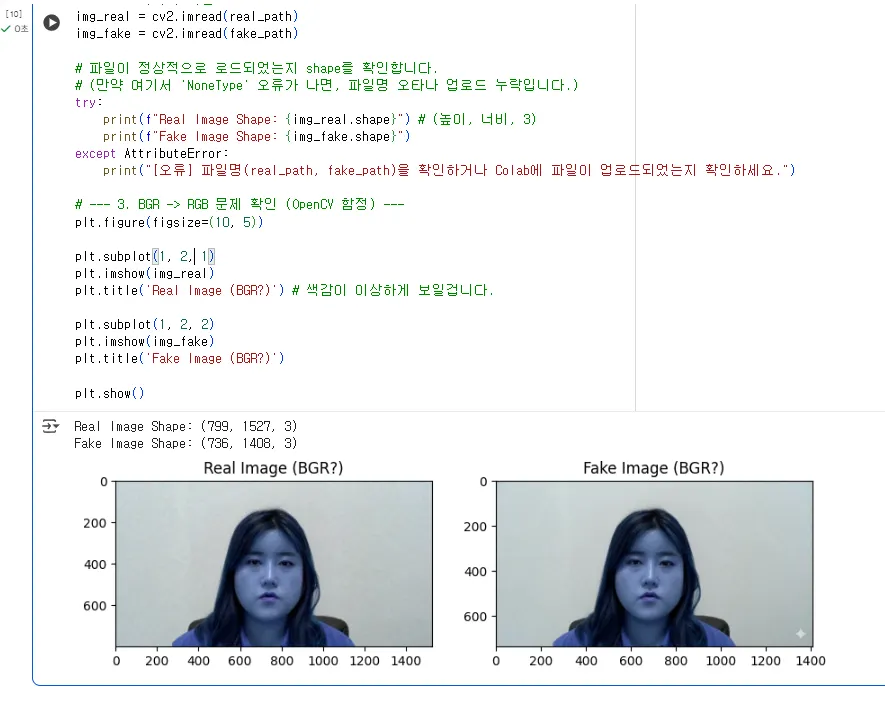
"이유는 간단합니다.
OpenCV는 이미지를 'BGR' (Blue-Green-Red) 순서로 읽어오는데,Matplotlib은 이미지를 'RGB' (Red-Green-Blue) 순서로 표시하기 때문입니다."
"R(빨간색) 자리에 B(파란색)가 들어가고, B 자리에 R이 들어가서 색이 뒤집혀 보인 거죠.
그래서 plt.imshow()로 보여주기 전에는, 반드시 cv2.cvtColor() 함수로 색상 채널을 BGR에서 RGB로 변환해줘야 합니다."
# --- 4. BGR -> RGB 변환 및 정상 출력 ---
img_real_rgb = cv2.cvtColor(img_real, cv2.COLOR_BGR2RGB)
img_fake_rgb = cv2.cvtColor(img_fake, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img_real_rgb)
plt.title('Real Photo (Origin)')
plt.subplot(1, 2, 2)
plt.imshow(img_fake_rgb)
plt.title('AI Generated (Changer)')
plt.show()
Markdown
복사
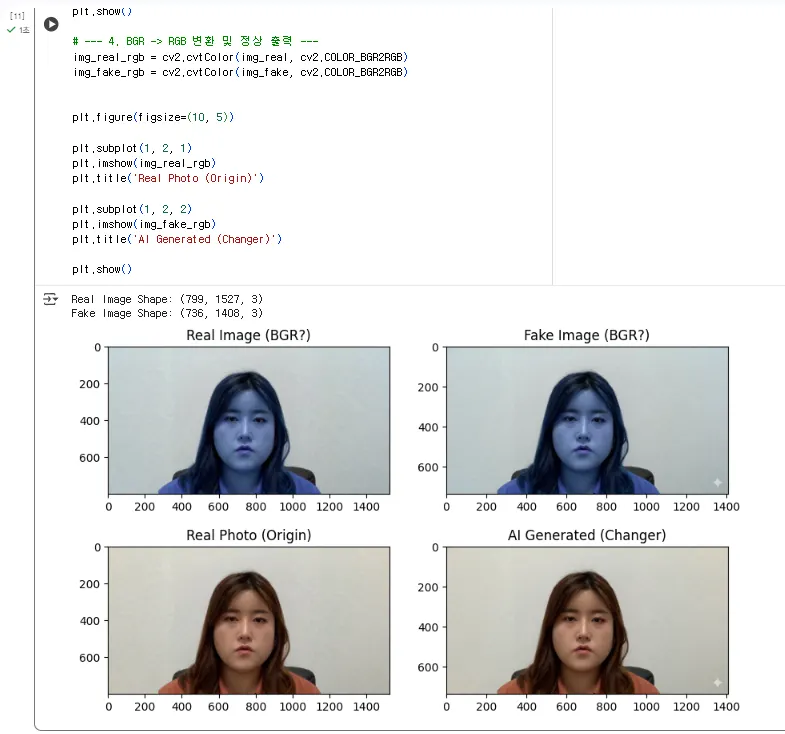
(실행)
"네, 이제야 두 이미지가 정상적인 색상으로 보입니다."
"(두 이미지 비교 분석)
어떠신가요? 왼쪽은 제가 방금 카메라로 찍은 '실제 사진'이고, 오른쪽은 AI가 생성한 '가짜 이미지'입니다.
GAN 기술이 워낙 발전해서, [cite: 1721-1724] 전체적으로 보면 구별이 거의 불가능합니다. 어떨 때는 AI가 만든 이미지가 '너무 완벽해서' 오히려 비현실적으로 보일 때도 있죠."
"하지만 아티팩트(Artifact), 즉 AI가 만들어낸 오류는 **'디테일'**에 숨어있습니다.
AI 모델은 사람의 눈, 코, 입의 '구조'는 잘 학습하지만, 머리카락 한 올 한 올의 물리법칙이나, 안경과 피부의 경계, 귀의 복잡한 구조를 일관성 있게 그려내는 데는 여전히 약점을 보입니다.
•
*이미지를 확대(Zoom-in)**해서 확인해 보겠습니다."
3. 실습: 이미지 확대(Zoom-in)로 아티팩트 분석
"Numpy 배열을 슬라이싱(slicing)해서 이미지의 특정 부분만 잘라내 보겠습니다.
(강사: img_real_rgb.shape를 보고 적절한 좌표(y, x)를 찾습니다. 예를 들어 눈, 머리카락 경계 등)"
"(예시: 이미지의 [y시작:y끝, x시작:x끝] 좌표로 자릅니다)"
# (좌표 예시: 수강생들은 각자 이미지에 맞게 좌표를 수정해야 합니다)
# (y, x) 좌표계입니다.
Y_START, Y_END = 400, 850
X_START, X_END = 400, 850
# Numpy Slicing으로 이미지 자르기
zoom_real = img_real_rgb[Y_START:Y_END, X_START:X_END]
zoom_fake = img_fake_rgb[Y_START:Y_END, X_START:X_END]
# 확대 이미지 비교
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(zoom_real)
plt.title('Real (Zoomed In)')
plt.subplot(1, 2, 2)
plt.imshow(zoom_fake)
plt.title('AI Generated (Zoomed In)')
plt.show()
Markdown
복사

(실행 및 확대된 이미지 분석)
"자, 이제 차이가 좀 보이시나요?"
"(예상되는 분석)
[실제 사진 (Real)]
•
카메라로 찍었기 때문에 '픽셀 노이즈'나 '그레인(grain)'이 균일하게 보입니다.
•
초점이 맞은 부분(예: 속눈썹)은 날카롭고(sharp), 초점이 맞지 않은 부분(배경)은 자연스럽게 흐릿합니다(bokeh).
•
피부의 질감(texture), 미세한 솜털 등이 살아있습니다.
[AI 생성 (Fake)]
•
피부 질감이 마치 '물감'이나 '왁스'로 칠한 것처럼 **비정상적으로 매끈(Oversmoothing)**합니다.
•
머리카락이나 속눈썹이 '뭉개져' 보이거나, 마치 스파게티 가닥처럼 비현실적으로 보일 수 있습니다.
•
가장 중요한 것: 배경과 인물의 경계면(예: 머리카락과 하늘)이 부자연스럽게 뭉개지거나 '지글거리는' 아티팩트가 보입니다."
"우리가 5일차에 분석할 CNN 모델은, 바로 이 픽셀 레벨의 '비정상적인 매끈함' 또는 **'경계면의 아티팩트'**를 학습하여 '이것은 실제 카메라로 찍은 사진의 통계적 특성과 다르다'고 판별하게 됩니다."
4. 정리 및 다음 단계
•
탐지 모델은 이러한 미세한 '차이(artifact)'를 학습해야 함.
•
Next: 2일차 - 이 데이터를 활용할 '딥페이크 탐지 웹 프로젝트' 설계.
"좋습니다. 오늘 1일차 과정을 모두 마쳤습니다.
정리해 보겠습니다.
오전에는 AI, 딥러닝(CNN/RNN), 스마트시티, 딥페이크라는 핵심 '이론'을 배웠습니다.
오후에는 두 번의 실습을 진행했습니다.
실습 1에서는 Colab 환경과 Python의 '도구'(Numpy, Pandas, Matplotlib)를 익혔고,
실습 2에서는 이 도구로 '문제'(딥페이크 데이터)를 직접 분석(EDA)해봤습니다.
•
*음성(librosa)**에서는 **스펙트로그램(지문)**을 통해 '주파수 밴드의 왜곡(잘림 또는 이동)' 패턴을 확인했고,
**이미지(cv2)**에서는 **확대(Zoom-in)**를 통해 **'픽셀 아티팩트'**와 **'비정상적인 매끈함'**을 확인했습니다.
이것으로 1일차 'AI 및 스마트시티' 과정이 모두 끝났습니다.
Related Posts
Search











