


새롭게 구축한 PostgreSQL(pgvector) 벡터 데이터베이스에 Spring Boot 백엔드를 연동하고, 기존 MySQL의 데이터를 안전하게 이관하여 기존 서비스와 100% 동일하게 동작하도록 검증하는 과정입니다.
Table of Content

1. 마이그레이션 전략 (Migration Strategy)

안전한 데이터 이관을 위한 순서: "스키마 먼저, 데이터는 나중에”
•
MySQL과 PostgreSQL 간 데이터 타입(DATETIME vs TIMESTAMP, TINYINT vs BOOLEAN 등) 차이로 인한 직접 마이그레이션 시 오류 발생 위험 존재.
•
단계별 전략:
1.
JPA 연동: Spring Boot 접속 정보를 PostgreSQL로 변경.
2.
스키마 자동 생성: 애플리케이션 실행을 통해 JPA(Hibernate)가 엔티티(@Entity)를 분석, PostgreSQL용 빈 테이블(스키마) 자동 생성 유도.
3.
데이터 적재: 완성된 빈 테이블에 기존 MySQL 데이터를 Export/Import 방식으로 이관.
해당 세션의 목표
•
OS 환경에 구애받지 않는 Docker 기반의 PostgreSQL 및 pgvector 환경 구축
•
기존 MySQL에 적재된 전시관(Exhibition) 및 작품(Production) 데이터의 손실 없는 이전
•
Spring Boot 백엔드와 새로운 DB의 JPA 연동 및 기존 API 정상 동작 검증
2. Spring Boot 백엔드 설정 변경 (Backend Configuration)
2.1 데이터베이스 의존성 교체
build.gradle 의존성(Dependency) 변경
•
기존 MySQL 드라이버 제거 및 PostgreSQL 드라이버 주입
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
compileOnly 'org.projectlombok:lombok'
// runtimeOnly 'com.mysql:mysql-connector-j'
runtimeOnly 'org.postgresql:postgresql'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
implementation 'io.awspring.cloud:spring-cloud-aws-starter-s3:3.1.1'
implementation 'org.apache.commons:commons-imaging:1.0-alpha3'
}
Java
복사
2.2 접속 정보 수정
application.properties접속 정보 수정
•
로컬/개발 환경 DB 접속 정보 변경 및 JPA PostgreSQL Dialect 설정.
# Database Settings (Local)
spring.datasource.url=jdbc:postgresql://localhost:5432/vexhibition
spring.datasource.username=root
spring.datasource.password=1234
spring.datasource.driver-class-name=org.postgresql.Driver
# JPA Settings
spring.jpa.hibernate.ddl-auto=update
spring.jpa.database-platform=org.hibernate.dialect.PostgreSQLDialect
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.properties.hibernate.use_sql_comments=true
Java
복사
3. JPA 스키마 자동 생성 및 검증 (Auto DDL)
3.1.1 콘솔 로그 확인
Spring Boot 기동 시 Hibernate: create table exhibition... 등의 DDL 쿼리 정상 실행 여부(에러 유무) 확인.
•
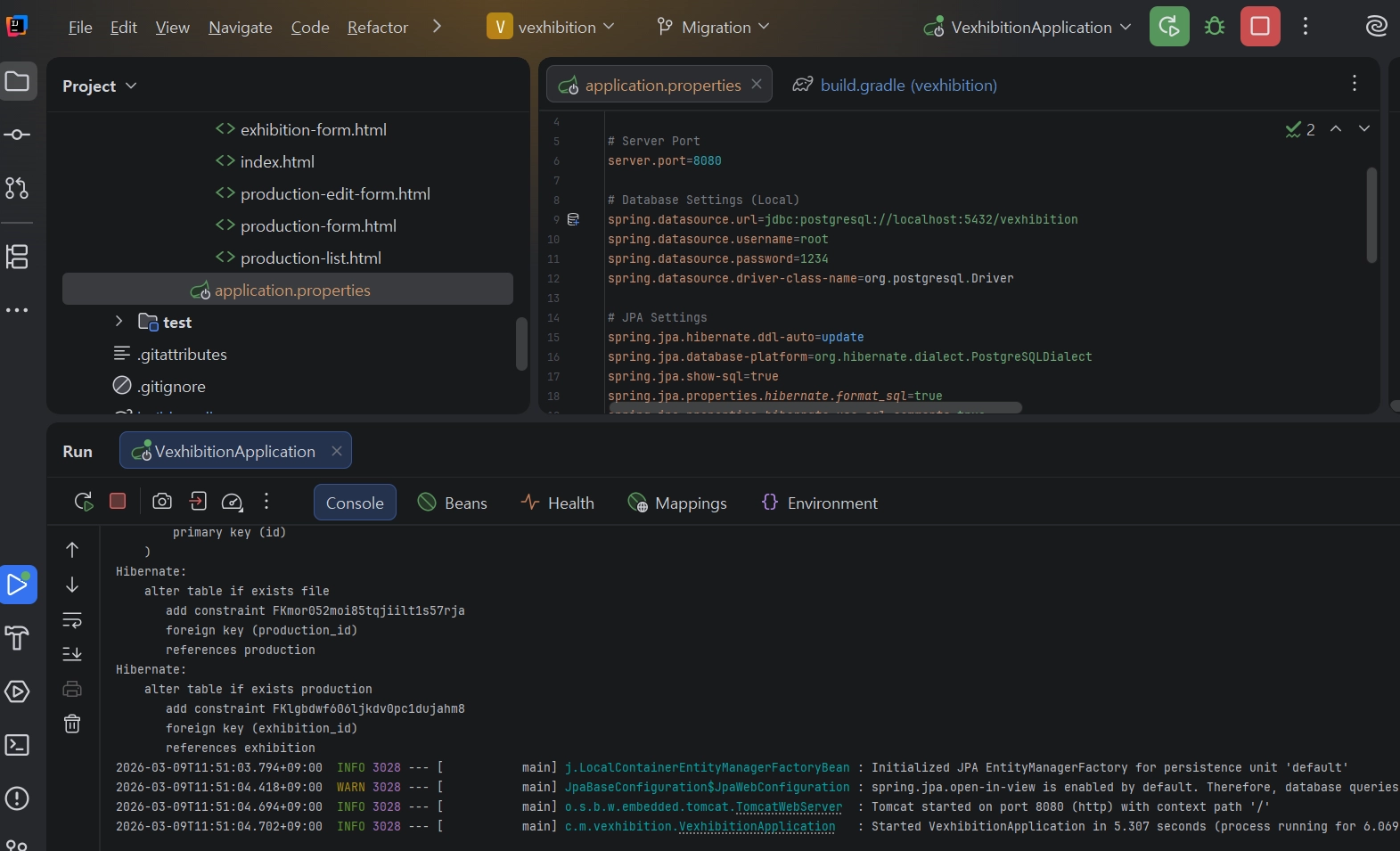
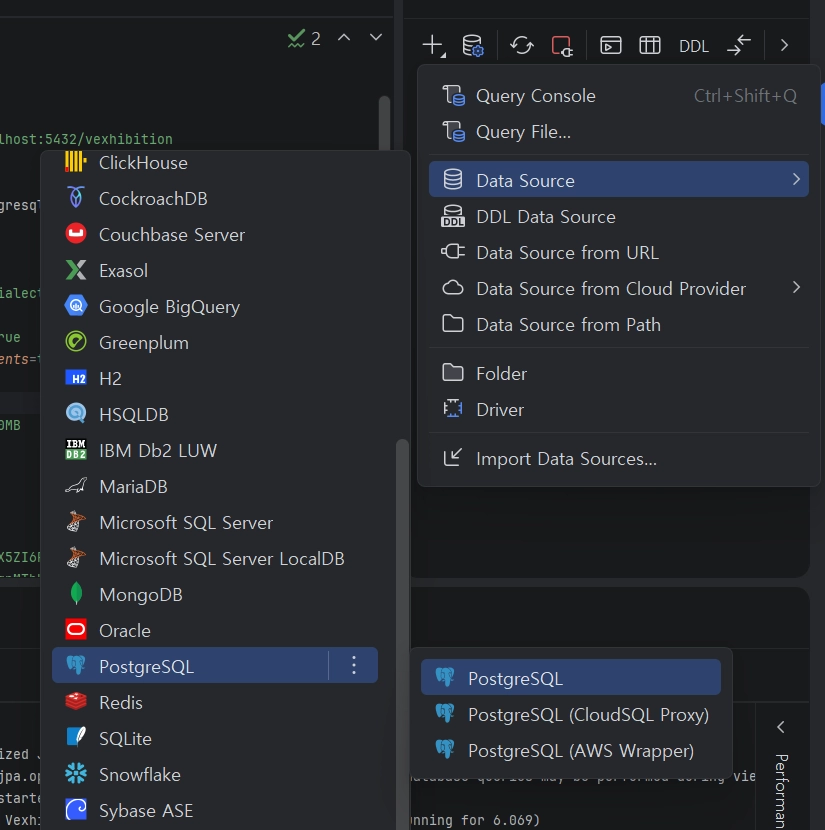
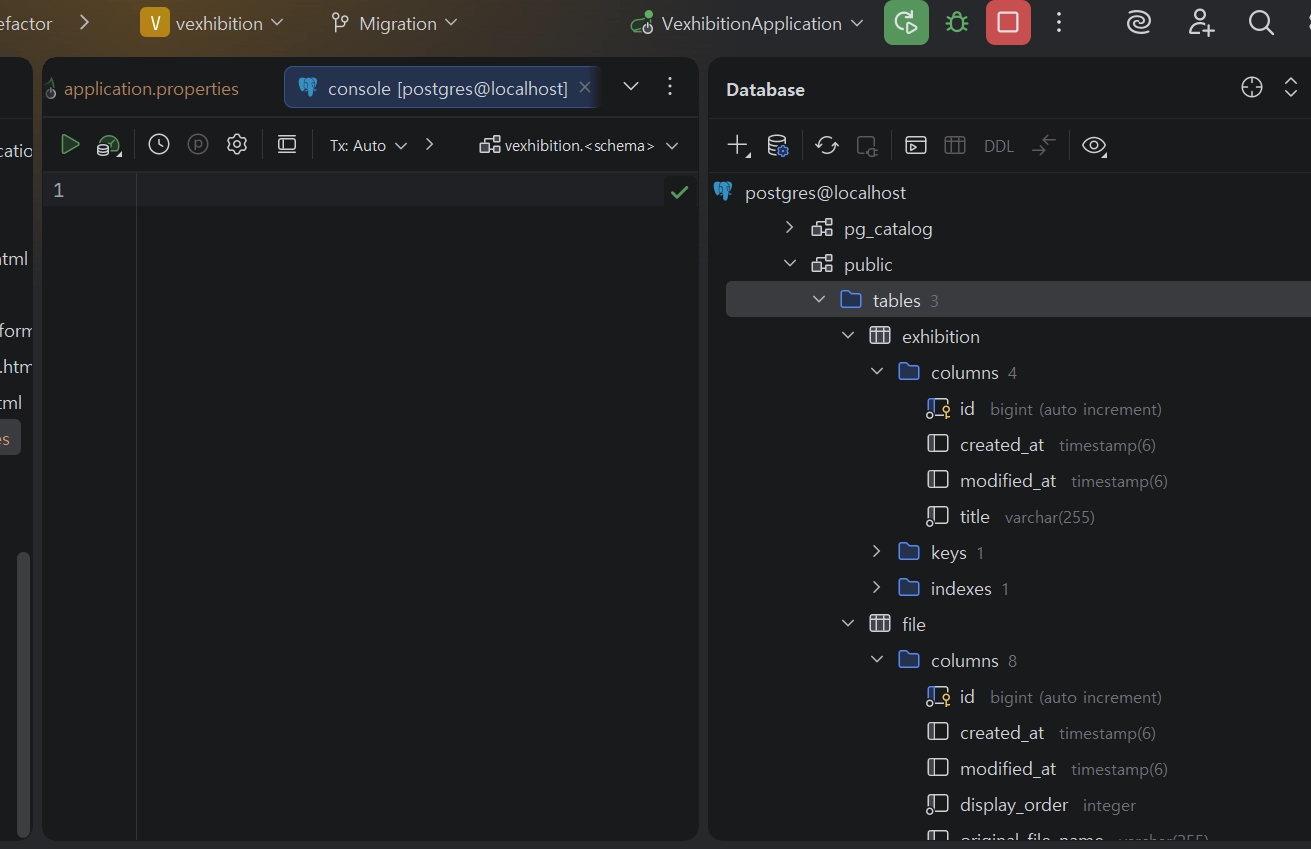
3.1.2 DB 툴(CLI 및 GUI 등) 최종 확인
PostgreSQL(localhost:5432) 접속 후 vexhibition 데이터베이스 내 exhibition, production 등 테이블 스키마 정상 생성 확인 (데이터 없는 빈 테이블 상태).
•
IntelliJ의 기본 플러그인 Database를 통해 Connection 추가
•
테이블 생성 상태 확인
4. 기존 데이터 이전 (MySQL -> PostgreSQL)
4.1 MySQL 데이터 추출 (Export)
데이터 추출
•
기존 MySQL GUI를 통한 접속, Tables 우클릭 선택
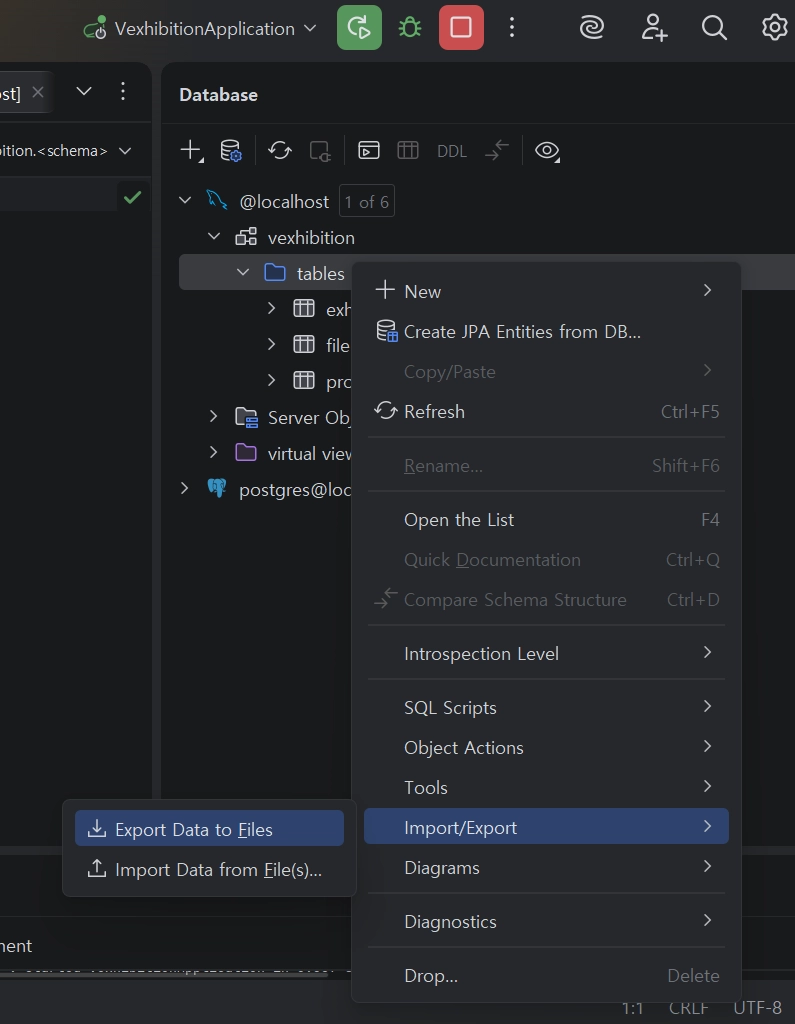
•
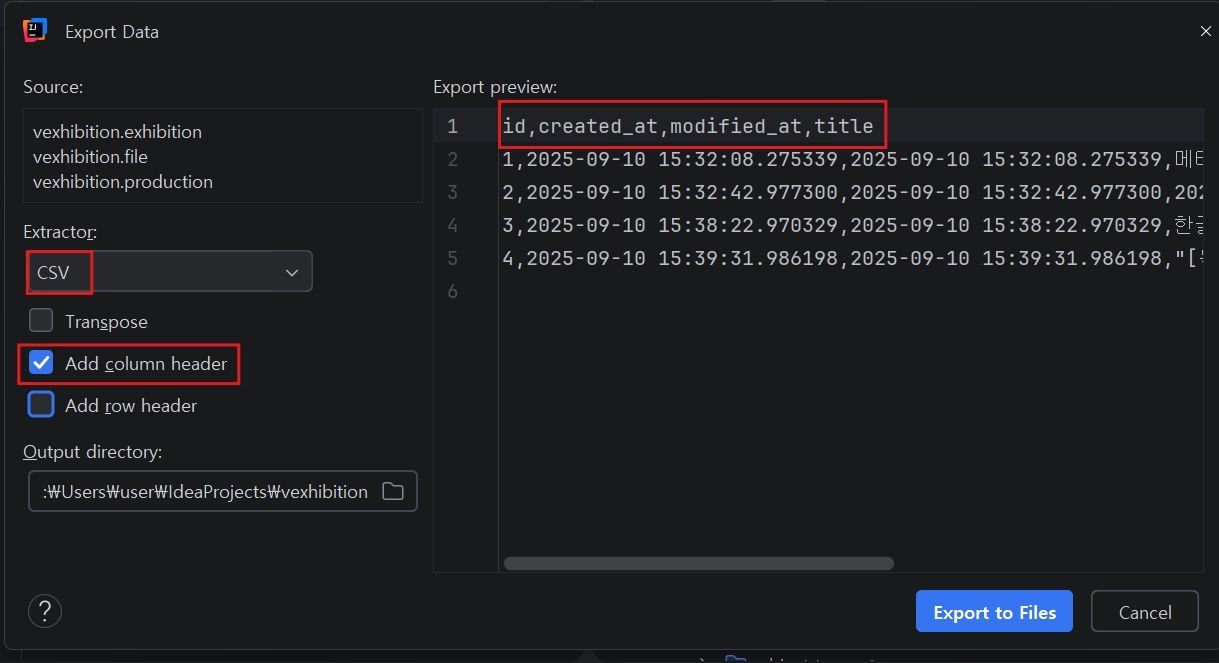
CSV 형식 선택 → 데이터 내보내기(Export Data) 선택.
◦
Add Column Header를 체크해서 컬럼명을 가져갈 수 있음
•
포맷을 CSV로 지정하여 로컬 PC에 저장.
4.2 PostgreSQL 데이터 적재 (Import)
데이터 주입
•
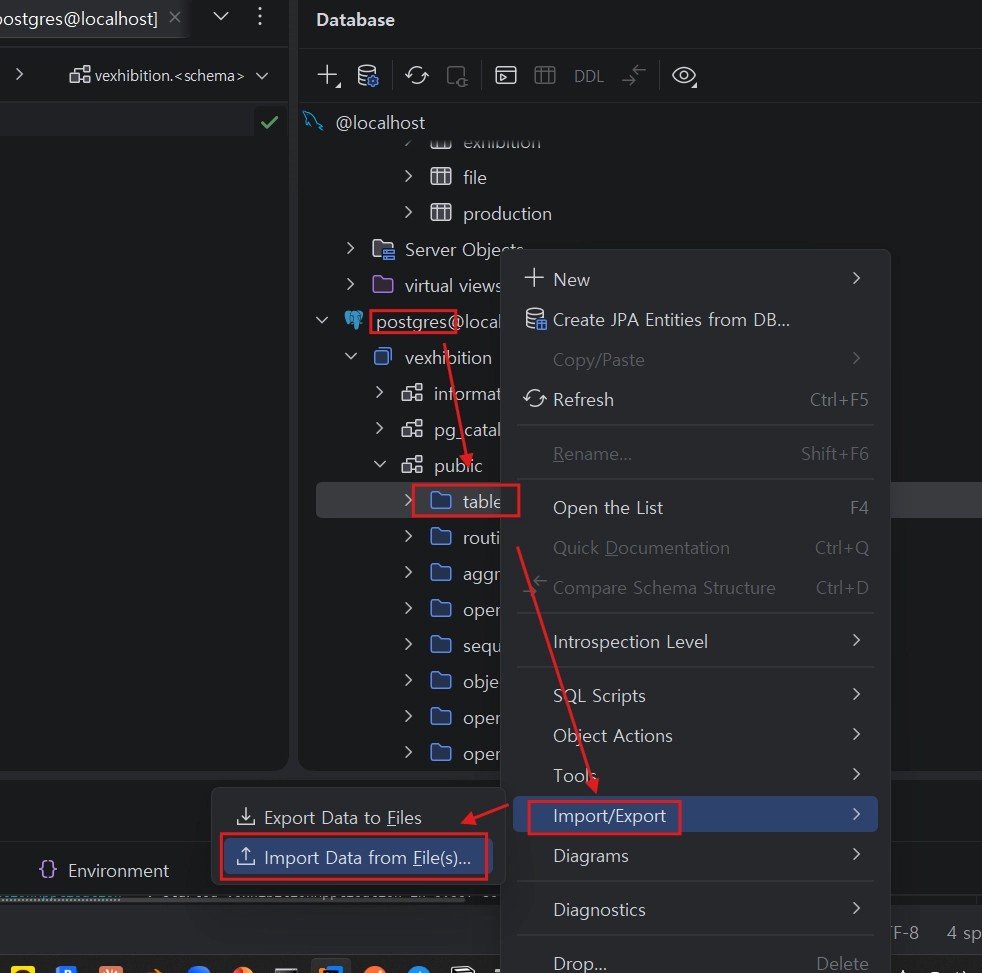
신규 구축한 PostgreSQL(Docker) 접속.
•
JPA가 생성한 빈 테이블 우클릭 → 데이터 가져오기(Import Data) 선택.
•
추출한 CSV 파일 선택 및 데이터 적재.
◦
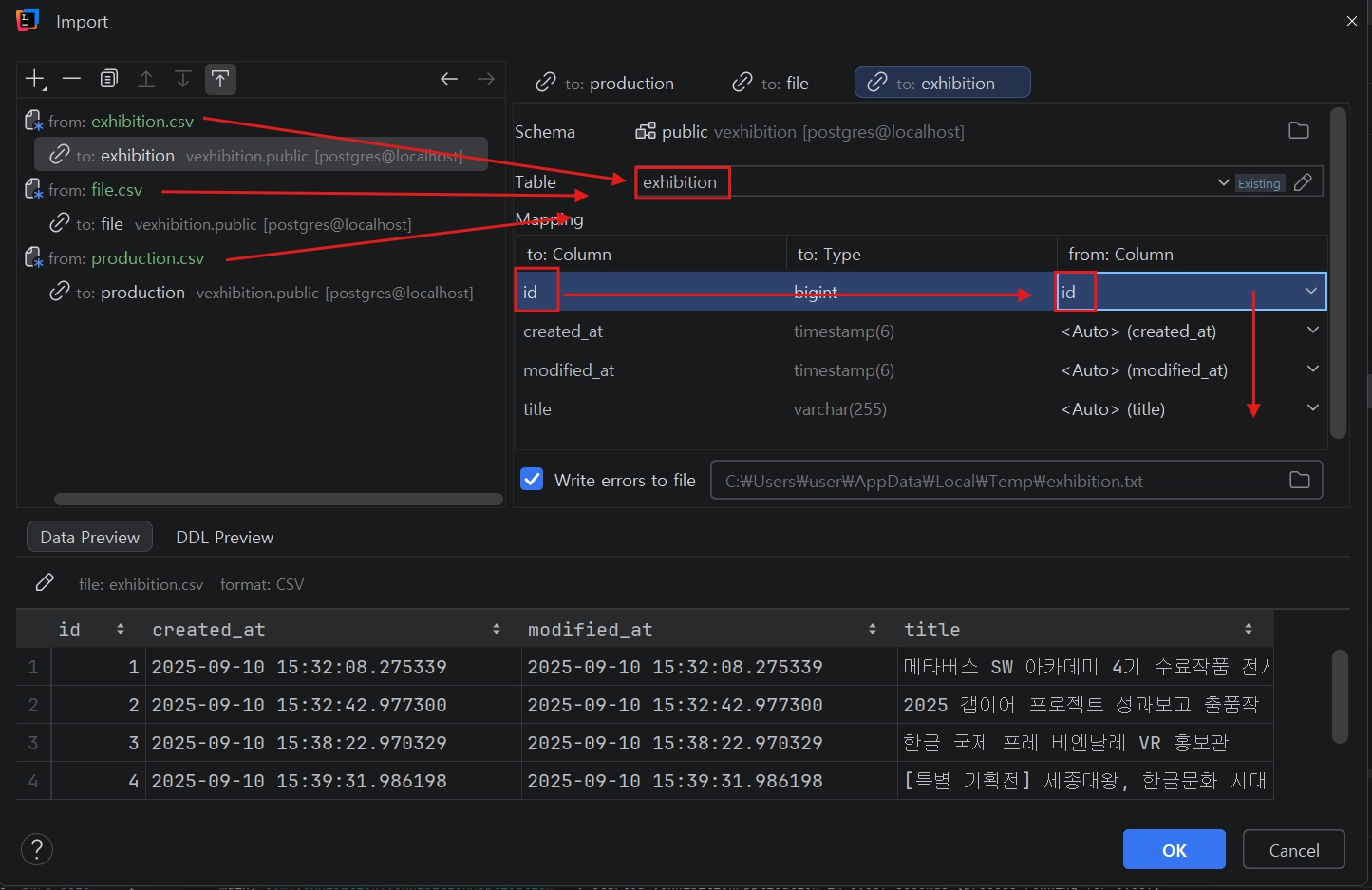
추출한 CSV 테이블이 각 PostgreSQL의 테이블에 맵핑 되도록 이름 변경(sample_2처럼 나타나므로 _2 제거하여 맵핑)
◦
컬럼 자동 인식에서 가끔 밀리는 경우가 있으니 아래 데이터 미리보기를 통해서 모든 컬럼에 각 데이터가 들어가도록 확인 필요
•
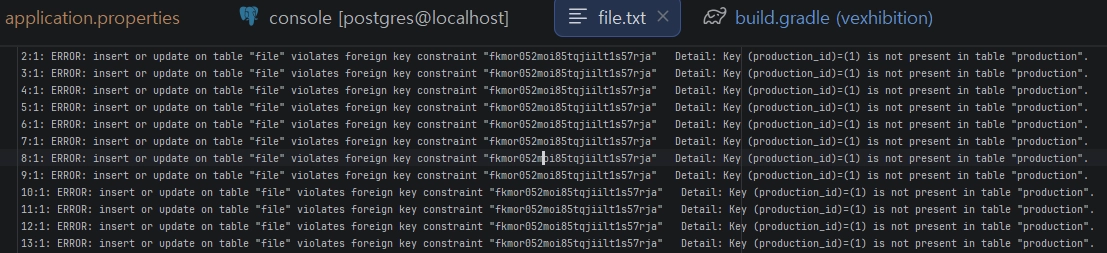
주의: 외래키(Foreign Key) 제약 조건 준수를 위해 부모 테이블(exhibition) 데이터 선 적재 후 자식 테이블(production) 적재 필수.•
다음처럼 일괄 임포트하면 문제가 발생 할 수 있다.(부모 FK 없을 수 있으므로) 부모부터 순서대로, 또는 다시 임포트하면 해결 됨
5. 시퀀스(Sequence) 동기화
•
MySQL의 AUTO_INCREMENT와 달리 PostgreSQL은 SEQUENCE 객체를 사용해 PK 증가시키는 차이점이 존재함(Oracle도 Sequence사용.)
•
CSV 강제 적재 시 PostgreSQL 시퀀스가 현재 최대 ID 값을 인지하지 못하여(아직 증가된적이 없기 때문에 1부터 시작될 수 있음) 신규 Insert 시 PK 중복 에러(PK Violation) 발생
기본키(PK) 충돌 방지를 위한 필수 작업
•
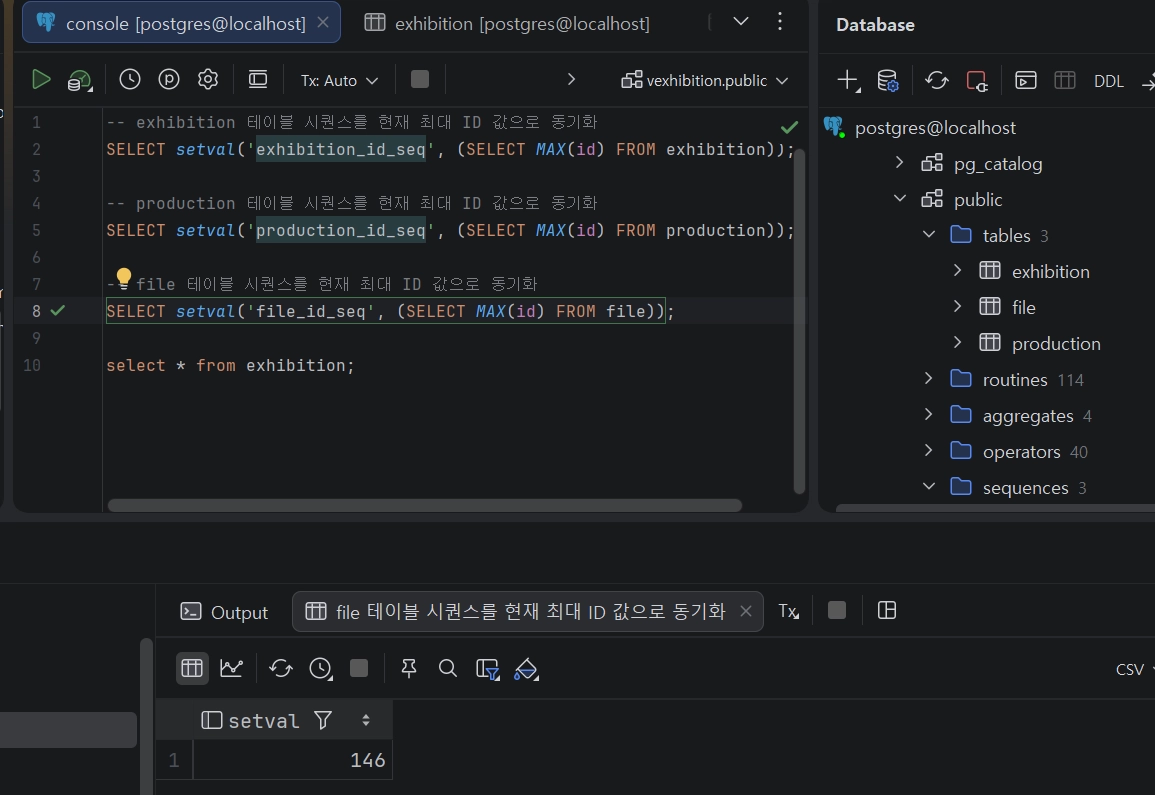
데이터 이관 완료 후 시퀀스 번호 강제 동기화 쿼리 실행.
-- exhibition 테이블 시퀀스를 현재 최대 ID 값으로 동기화
SELECT setval('exhibition_id_seq', (SELECT MAX(id) FROM exhibition));
-- production 테이블 시퀀스를 현재 최대 ID 값으로 동기화
SELECT setval('production_id_seq', (SELECT MAX(id) FROM production));
-- file 테이블 시퀀스를 현재 최대 ID 값으로 동기화
SELECT setval('file_id_seq', (SELECT MAX(id) FROM file));
Java
복사
6. API 연동 테스트 및 최종 검증 (Verification)
기존 서비스와의 호환성 체크
•
Postman / 웹 브라우저 테스트
◦
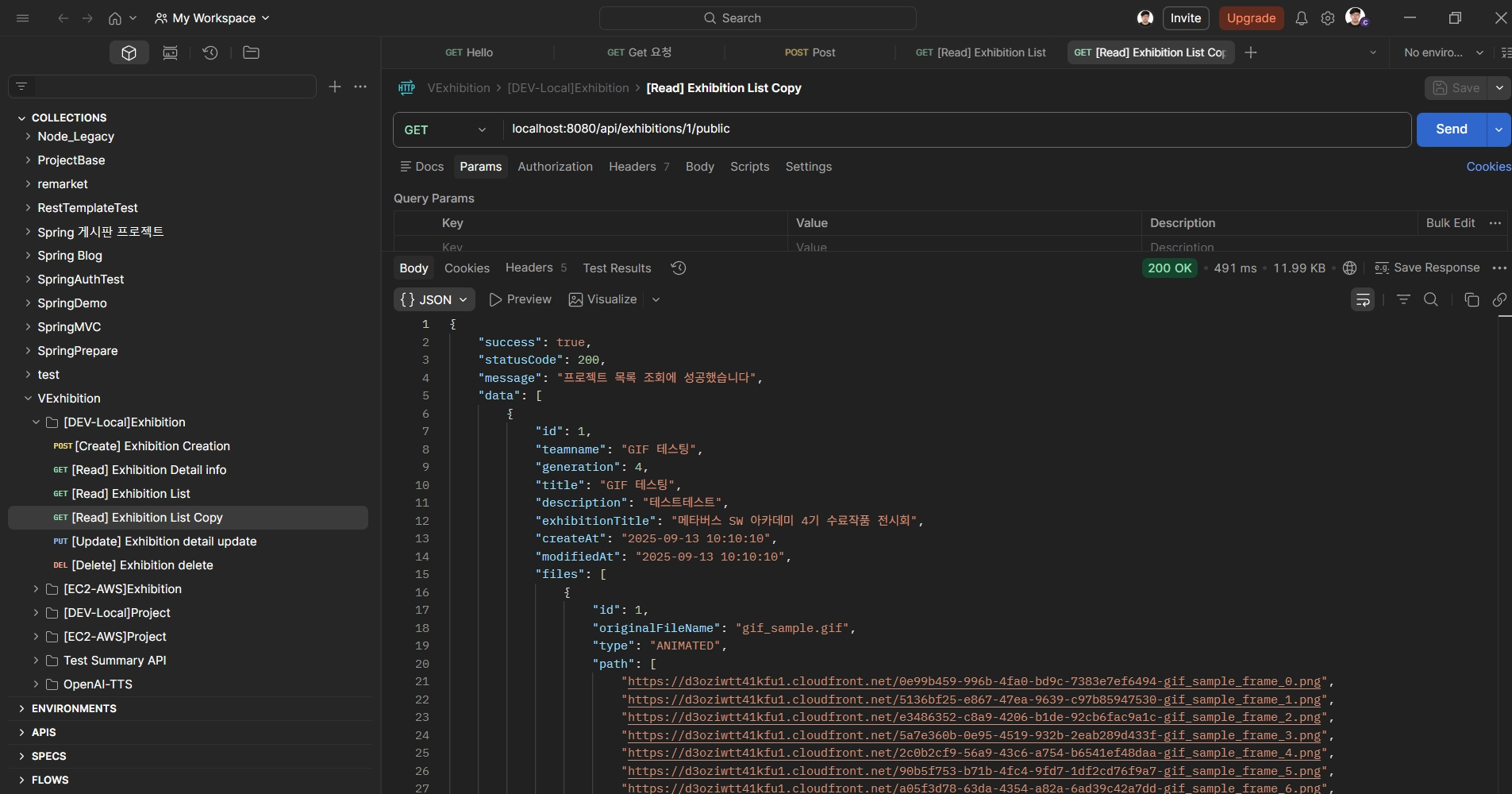
API Endpoint 호출: http://localhost:8080/api/exhibitions/1/public
◦
기존 MySQL 환경과 동일한 JSON 응답 포맷(ApiResponseDto) 및 데이터 반환 여부 확인.
•
클라이언트(언리얼 엔진) 테스트
◦
가상 전시관 게임 클라이언트 실행.

◦
전시관 로비 목록 및 작품 패널 데이터의 정상 렌더링(지연 및 크래시 여부) 검증.
Related Posts
Search



