



대량의 도서 데이터 준비
약 710만건의 도서 데이터가 CSV파일로 정리되어있습니다. 문화데이터 포털의 도서 정보 데이터를 활용하고 있습니다.
이전 MySQL을 활용했던 기본 검색 기준에서도 동일한 데이터를 MySQL의 LOAD FILE을 통해서 입력해서 사용했었기 때문에 동일한 데이터를 Elasticsearch에 넣어서 검색 성능의 차이를 살펴보고자합니다.

Elasticsearch에 데이터를 넣는 방법
기본적으로 Elasticsearch에 직접 데이터를 넣는 방법과 Logstash를 활용하는 방법이 있습니다. 우선 직접 데이터를 넣는 방법으로 간단한 테스트부터 진행해보고자 합니다.
Elasticsearch에 데이터를 직접 넣기
준비된 데이터를 Elasticsearch에 직접 넣기 위해서는 각 데이터를 JSON 형식으로 변환하고 적절한 인덱스에 색인해야 합니다.
MySQL로 넣을때 엔티티 이름과의 통일을 위해서 원본 csv의 파일의 내용을 변환하여 저장했습니다. 카테고리 또한 분류법을 단순화시킨 DB 기준으로 원본의 카테고리 번호를 변환했었습니다.
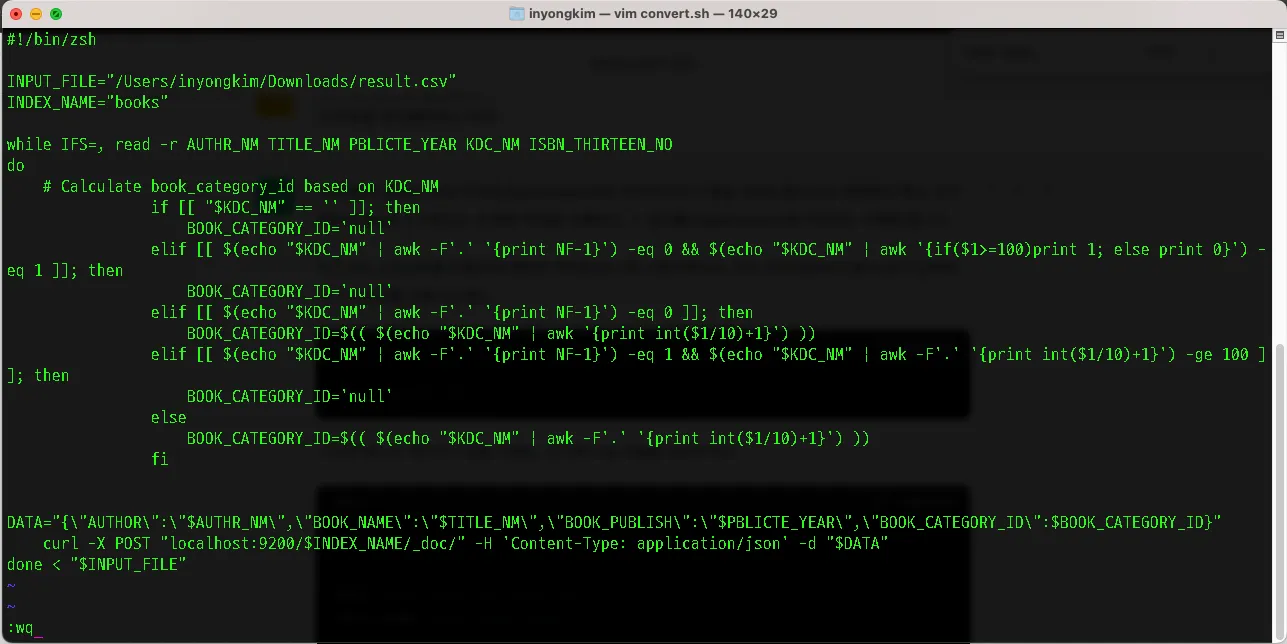
통일성을 주기 위해서 MySQL의 "컬럼(column)" 개념과 유사한 역할을 하는 것이 Elasticsearch에서의 "필드(field)"입니다. 따라서 필드의 이름을 Entity 기준으로 변경, 카테고리 또한 DB를 기준으로 연산되어 필드값으로 들어 갈 수 있도록 데이터 전처리 스크립트인 아래 쉘 스크립트를 수정했습니다.
#!/bin/zsh
INPUT_FILE="/Users/inyongkim/Downloads/result.csv"
INDEX_NAME="books"
while IFS=, read -r AUTHR_NM TITLE_NM PBLICTE_YEAR KDC_NM ISBN_THIRTEEN_NO
do
# Calculate book_category_id based on KDC_NM
if [[ "$KDC_NM" == '' ]]; then
BOOK_CATEGORY_ID='null'
elif [[ $(echo "$KDC_NM" | awk -F'.' '{print NF-1}') -eq 0 && $(echo "$KDC_NM" | awk '{if($1>=100)print 1; else print 0}') -eq 1 ]]; then
BOOK_CATEGORY_ID='null'
elif [[ $(echo "$KDC_NM" | awk -F'.' '{print NF-1}') -eq 0 ]]; then
BOOK_CATEGORY_ID=$(( $(echo "$KDC_NM" | awk '{print int($1/10)+1}') ))
elif [[ $(echo "$KDC_NM" | awk -F'.' '{print NF-1}') -eq 1 && $(echo "$KDC_NM" | awk -F'.' '{print int($1/10)+1}') -ge 100 ]]; then
BOOK_CATEGORY_ID='null'
else
BOOK_CATEGORY_ID=$(( $(echo "$KDC_NM" | awk -F'.' '{print int($1/10)+1}') ))
fi
DATA="{\"AUTHOR\":\"$AUTHR_NM\",\"BOOK_NAME\":\"$TITLE_NM\",\"BOOK_PUBLISH\":\"$PBLICTE_YEAR\",\"BOOK_CATEGORY_ID\":$BOOK_CATEGORY_ID}"
curl -X POST "localhost:9200/$INDEX_NAME/_doc/" -H 'Content-Type: application/json' -d "$DATA"
done < "$INPUT_FILE"
Shell
복사
위 스크립트를 convert.sh라는 파일로 작성합니다. CLI환경에서는 nano 또는 vi 에디터를 사용 할 수 있습니다. GUI환경이 제공된다면 단순하게 메모장 또는 IDE들을 활용해서 해당 스크립트 파일을 작성해두면 됩니다.
nano convert.sh
Shell
복사
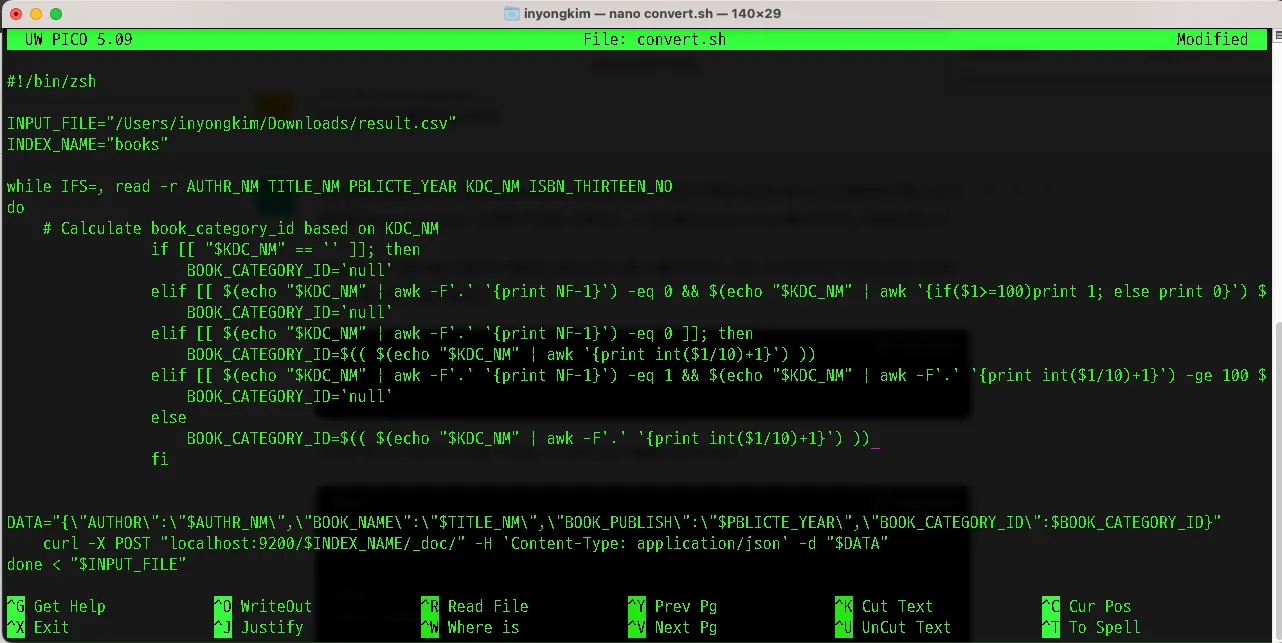
vim convert.sh
Shell
복사
brew services
Shell
복사

Elasticsearch가 실행중인것을 확인하고 해당 쉘 스크립트를 실행해줍니다. 스크립트 실행 권한이 필요한 경우 아래 명령어를 사용합니다.
chmod +x convert.sh
Shell
복사
스크립트 실행
./convert.sh
Shell
복사
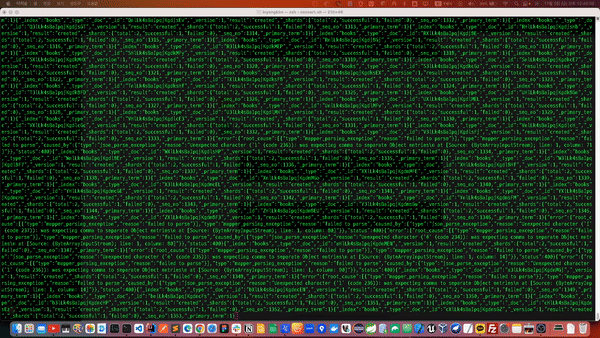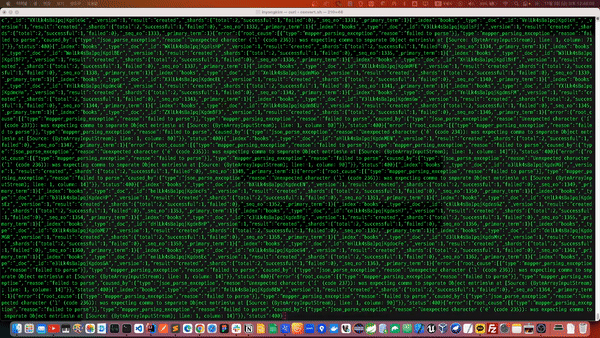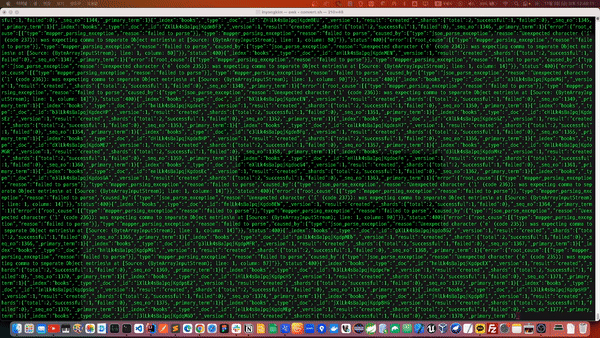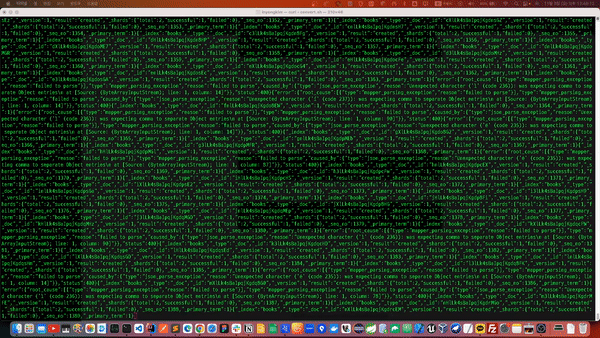
다음과 같이 CSV 텍스트 파일이 JSON으로 변환되면서 삽입되는 과정을 확인 할 수 있습니다. 710만건 가까이 되는 대량 데이터기 때문에 상당한 시간이 소요 될 수 있습니다.
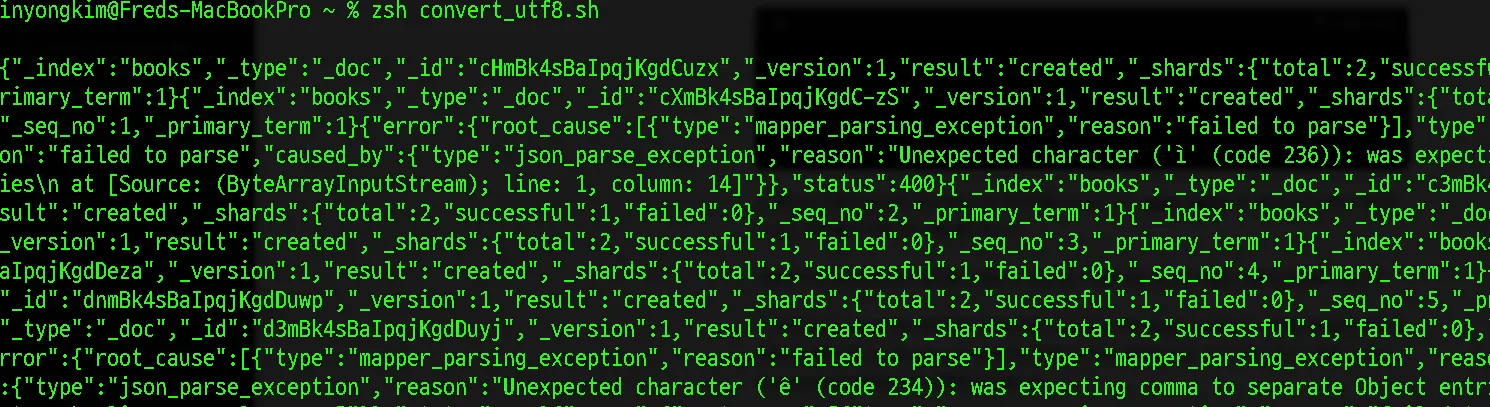
JSON 변환 중 오류 발생
데이터가 변환되는 로그를 살펴보던중 일부 예외가 발생하고 있는 것이 나타났습니다.
[{"type":"mapper_parsing_exception","reason":"failed to parse"}],"type":"mapper_parsing_exception","reason":"failed to parse","caused_by":{"type":"json_parse_exception","reason":"Unexpected character ('ê' (code 234)): was expecting comma to separate Object entries\n at [Source: (ByteArrayInputStream); line: 1, column: 14]"}},"status":400}{"_index":"books","_type":"_doc","_id":"THlPk4sBaIpqjKgdLc3L","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":3627,"_primary_term":1}
Shell
복사
CSV로 정리된 도서 데이터 자체가 일부 통일성이 없는 부분이 있어서 그 부분에 대한 처리가 부족했던것으로 보여집니다.
특히, 작은따옴표와 큰따옴표를 처리가 필요했습니다. 데이터 임포트를 위한 쉘 스크립트가 점점 복잡해지는데, 그렇다고해서 정확한 구분을 할 수 있을지에 대한 신뢰도가 낮습니다.
#!/bin/zsh
INPUT_FILE="/Users/inyongkim/Downloads/result.csv"
INDEX_NAME="books"
while IFS=, read -r AUTHR_NM TITLE_NM PBLICTE_YEAR KDC_NM ISBN_THIRTEEN_NO
do
# Calculate book_category_id based on KDC_NM
if [[ "$KDC_NM" == '' ]]; then
BOOK_CATEGORY_ID='null'
elif [[ $(echo "$KDC_NM" | awk -F'.' '{print NF-1}') -eq 0 && $(echo "$KDC_NM" | awk '{if($1>=100)print 1; else print 0}') -eq 1 ]]; then
BOOK_CATEGORY_ID='null'
elif [[ $(echo "$KDC_NM" | awk -F'.' '{print NF-1}') -eq 0 ]]; then
BOOK_CATEGORY_ID=$(( $(echo "$KDC_NM" | awk '{print int($1/10)+1}') ))
elif [[ $(echo "$KDC_NM" | awk -F'.' '{print NF-1}') -eq 1 && $(echo "$KDC_NM" | awk -F'.' '{print int($1/10)+1}') -ge 100 ]]; then
BOOK_CATEGORY_ID='null'
else
BOOK_CATEGORY_ID=$(( $(echo "$KDC_NM" | awk -F'.' '{print int($1/10)+1}') ))
fi
# Escape double quotes in data
AUTHR_NM=$(echo "$AUTHR_NM" | sed 's/"/\\"/g')
TITLE_NM=$(echo "$TITLE_NM" | sed 's/"/\\"/g')
DATA="{\"AUTHOR\":\"$AUTHR_NM\",\"BOOK_NAME\":\"$TITLE_NM\",\"BOOK_PUBLISH\":\"$PBLICTE_YEAR\",\"BOOK_CATEGORY_ID\":$BOOK_CATEGORY_ID}"
curl -X POST "localhost:9200/$INDEX_NAME/_doc/" -H 'Content-Type: application/json' -d "$DATA"
done < "$INPUT_FILE"
Shell
복사
그리고 Unexpected character ('ê')와 같이 이상한 문자에 대한 문제가 나타나고있습니다. 스크립트와 CSV 파일의 인코딩이 일치하지 않을 경우 문제가 발생할 수 있습니다. 파일의 인코딩을 확인합니다.
file -I convert.sh
Shell
복사
file -I /Users/inyongkim/Downloads/result.csv
Shell
복사

인코딩 캐릭터타입이 다른것을 확인했습니다. 쉘 스크립트를 UTF8로 변환하여 새로 저장합니다.
iconv -f us-ascii -t UTF-8 convert.sh -o convert_utf8.sh
Shell
복사
이에 따라 UTF8로 인코딩을 변경했지만 file 커맨드를 통해서는 변경된 것을 확인하기 어려웠습니다.

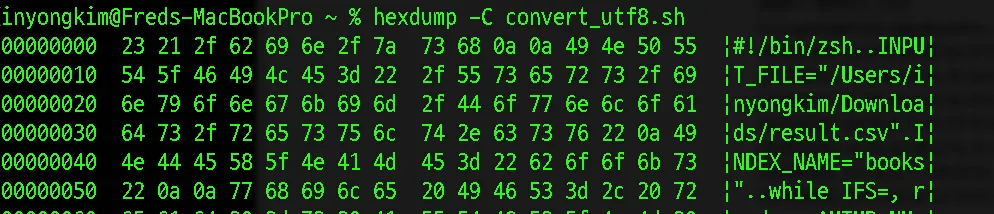
VSCODE로 열어서 확인한 결과 UTF8로 인코딩된것을 알 수 있었지만 CLI에서의 확인을 위해 hexdump -C convert_utf8.sh 를 통해서 확인해보았습니다.
hexdump의 결과를 확인해봤는데, 파일은 UTF-8로 인코딩되어 있는 것으로 보입니다. 특히 파일의 맨 앞에 나타나는 23 21은 ASCII로 #!를 나타내고 있습니다. 이는 셸 스크립트 파일의 시작을 나타내며, 여기서 UTF-8로 인코딩된 파일임을 확인할 수 있습니다.
데이터 삽입 재실행
데이터 삽입 중 오류를 발견해서 중지했기 때문에, 이전 내용들이 삽입 되어있을 수 있습니다.
curl -X GET "localhost:9200/books/_search"
Shell
복사
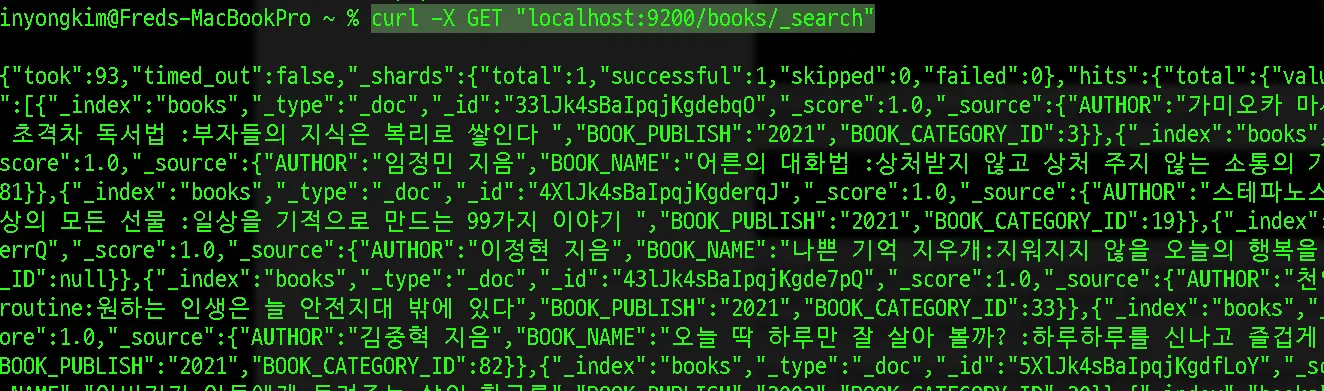
이 내용들을 삭제하고 다시 진행합니다.
curl -X DELETE "localhost:9200/books"
Shell
복사
계속된 삽입 문제 발생, 원인과 다른 방안은?
계속해서 문제가 발생합니다. 원인은 결국 CSV파일 자체의 통일성이 부족하여 세밀한 조건을 설정하기가 어려운점에서 첫 데이터 가공의 중요성을 느끼게 되었습니다.
AUTHR_NM,TITLE_NM,PBLICTE_YEAR,KDC_NM,ISBN_THIRTEEN_NO
앤 섹스턴 지음;신해경 옮김,저는 이곳에 있지 않을 거예요,2021,841,9791186372906
"윤성근 지음 ;남서연,황정하 그림",헌책방 기담 수집가 ,2021,818,9791189336462
켄 폴릿 지음 ;한기찬 옮김,끝없는 세상 :켄 폴릿 장편소설,2019,808.9,9788954655057
우즈훙 지음 ;박나영 옮김,내 영혼을 다독이는 관계 심리학 :나르시시즘과 외로움 :내 안의 나와 터놓고 대화하기 ,2022,189.2,9788972773566
정교영 지음,혼자 있어도 외롭지 않게 :내성적이고 예민한 사람들을 위한 심리 수업 ,2021,182.12,9788946473850
황시투안 지음 ;정영재 옮김,인생의 변화는 말투에서 시작된다 :소중한 내 인생과 관계를 위한 말하기 심리학 ,2022,189,9791158741334
미리암 융게 지음 ;장혜경 옮김,(소소한 루틴을 단단한 멘탈로 만드는) 딱 한 걸음의 힘 ,2021,189.1,9791191842104
"권일용,고나무 지음",악의 마음을 읽는 자들 :국내 최초 프로파일러의 연쇄살인 추적기 ,2018,364.45,9791159922251
"윤희솔,박은주 지음 ;헬로그 그림",아홉 살 말 습관 사전:슬기로운 어린이로 자라는 28가지 말 이야기,2021,802,9791130638478
...
Shell
복사
이러한 데이터 원본 csv에서 작가 부분은 어떤것은 “”로 감싸져있는 경우도있으며, ‘,’콤마처럼 여러 작가가 참여한 경우도 있습니다. 통일성이 없다보니 콤마로 컬럼(필드)를 구분하기에는 작가 부분에서 내부에서도 escape가 발생 할 수도 있고 세밀한 조건을 지정하기 어려움이 있었습니다. 그럼 어떻게 처리하면 좋을지 다시 생각해봅니다.
MySQL에 기 정리된 데이터를 재활용하는 방안 생각
MySQL에는 LOAD DATA를 통해서 이와 같은 규칙이 통일되지 않은 상황에서도 스크립트를 통해서 원하는데로 데이터가 입력되었었습니다. 그리고 Data Export 옵션에서 다양한 데이터 재가공 형식을 볼 수 있었습니다. 특히 , “과 같은 특수문자가 겹치기 때문에 이러한 방식보다는 Pipe-separated와 같이 특정 문자로만 구분하는 옵션이 눈에 띄었습니다.
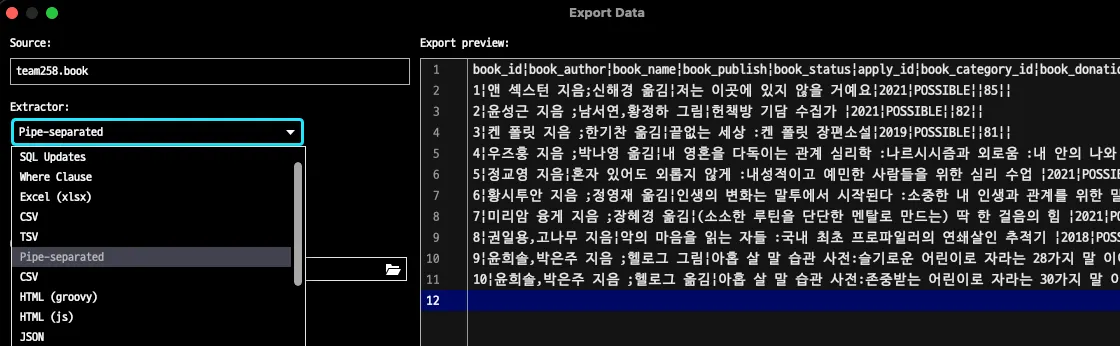
더 정확한 옵션을 확인했는데, json 파일 자체로 내보낼수 있는 기능이 있었습니다.
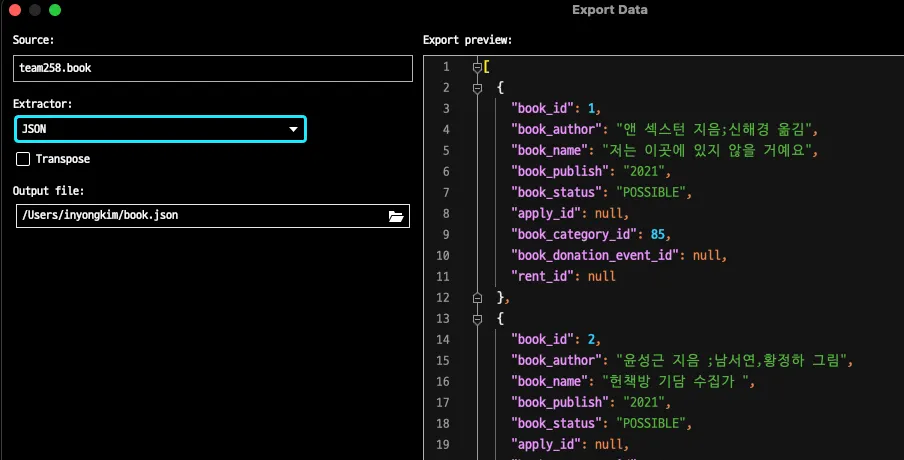
이러면 정확히 key, value로 구분되기 때문에 Elasticsearch가 가장 이해하기 편한 상태로 쉽게 입력될 것 같습니다.
IntelliJ의 export 기능을 활용하여 JSON 형식으로 데이터 재가공
JSON 형식으로 재가공되면 위 사진과 마찬가지로 텍스트 자체의 분량이 늘어나기 때문에 데이터 자체의 용량 상승은 무시 할 수 없었습니다.
기존 710만 도서 데이터의 CSV 텍스트 파일은 722.7MB지만
JSON 형태로 재가공된 데이터 파일은 2.25GB로 약 300%의 용량 상승이 나타났습니다.
하지만 오류와 안정적인 데이터 입력을 위해 선택을 해야 했고, JSON 형태의 파일을 임포트하는 방식으로 선회하게 되었습니다.
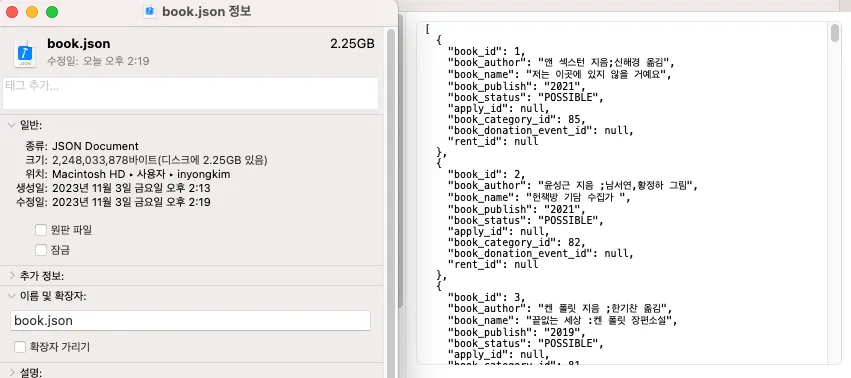
JSON 재가공 파일을 Elasticsearch에 적재
JSON 형태로 데이터를 가공하면 Elasticsearch가 이해하기 쉬울 것입니다. JSON은 Elasticsearch에서 널리 사용되는 형식이기 때문에 원하는 형태로 데이터를 가공했다면 Elasticsearch에 쉽게 적재할 수 있습니다.
이전 쉘 스크립트와 비교하여 매우 간단한 명령어들로 데이터를 넣을 수 있게 되었습니다.
새로 작성한 import_jsontoelastic.sh의 쉘 스크립트 내용입니다. 간단하게 라인별로 필드가 구분되는 방식입니다.
#!/bin/zsh
INPUT_FILE="/Users/inyongkim/book.json"
INDEX_NAME="books"
while IFS= read -r LINE
do
curl -X POST "localhost:9200/$INDEX_NAME/_doc/" -H 'Content-Type: application/json' -d "$LINE"
done < "$INPUT_FILE"
Shell
복사
zsh import_jsontoelastic.sh
Shell
복사