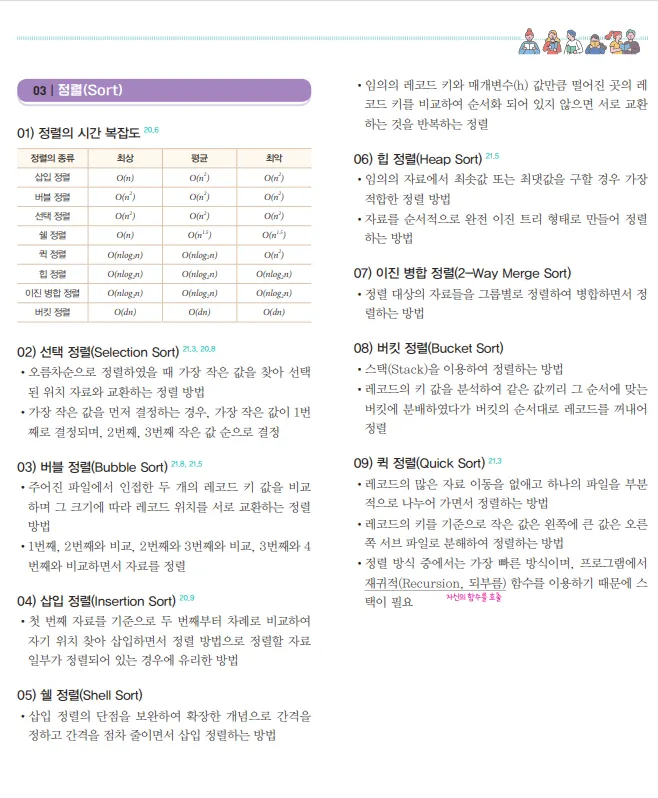
정렬 알고리즘에 대해서 아는대로 설명해주세요.
정렬 알고리즘이란
데이터들이 주어졌을 때 이를 정해진 순서대로 나열하는 것
얼마나 효과적으로 해결하는 지가 정렬 알고리즘의 핵심
데이터가 정렬되어 있으면 이진탐색이라는 강력한 알고리즘을 사용할 수 있습니다.
정렬 대상이 특정 크기 이하로 단편화될 때까지는 퀵 정렬을 쓰다가, 삽입 정렬을 쓴다던가, 특정 횟수 이상 재귀호출이 발생하면 O(nlgn)의 힙 정렬을 사용합니다.
버블 정렬 (Bubble Sort)
•
인접한 두 원소를 비교하며 큰 값을 뒤로 이동시키는 방식으로 정렬합니다.
•
전체 데이터를 순회하며 가장 큰 값이 맨 뒤에 위치하게 됩니다.
•
시간 복잡도는 최악 및 평균 경우에 O(n^2)이며, 간단하지만 비효율적인 정렬 알고리즘입니다.
삽입 정렬 (Insertion Sort)
•
배열을 정렬된 부분과 정렬되지 않은 부분으로 나누고, 정렬되지 않은 원소를 정렬된 부분에 삽입합니다.
•
삽입 정렬은 거의 정렬된 배열에 대해서는 효율적이며, 최선의 경우 시간 복잡도는 O(n)입니다. 하지만 최악 및 평균 경우에는 O(n^2)입니다.
선택 정렬 (Selection Sort)
•
주어진 배열에서 가장 작은 값을 선택하여 배열의 처음부터 차례대로 위치시키는 방식으로 정렬합니다.
•
시간 복잡도는 항상 O(n^2)이며, 버블 정렬과 유사한 성능을 가집니다.
퀵 정렬 (Quick Sort)
•
분할 정복(divide and conquer) 기법을 사용하여 배열을 분할하고 각 부분을 재귀적으로 정렬합니다.
•
평균적으로 매우 효율적인 알고리즘으로, 시간 복잡도는 평균적으로 O(n log n)입니다. 하지만 최악의 경우에는 O(n^2)이 될 수 있습니다.
병합 정렬 (Merge Sort)
•
분할 정복 기법을 사용하여 배열을 반으로 나눈 뒤, 각 부분을 정렬하면서 병합하는 방식으로 정렬합니다.
•
항상 O(n log n)의 시간 복잡도를 가지며, 안정적인 정렬 알고리즘 중 하나입니다.
힙 정렬 (Heap Sort)
•
최대 힙(또는 최소 힙) 자료구조를 사용하여 정렬하는 방식입니다.
•
시간 복잡도는 항상 O(n log n)이며, 대량의 데이터를 정렬하는 데 유용합니다.