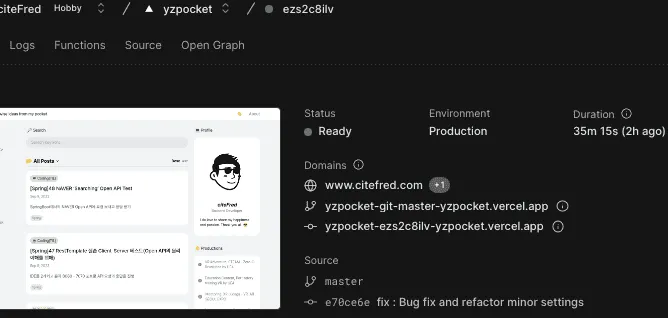
Vercel은 나의 글들을 감당하지 못하고있다.
Github-NotionDB-Vercel의 배포 방식으로 블로그가 돌아간다.
현재 이미지최적화와 모든 수단을 동원했지만, 결국엔 배포 한계점이 나타나고 있었고, 언젠가는 글을 추가하지 못한다는 압박이 오고있다.
[12:14:28.284] missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
[12:14:30.692] missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
[12:14:56.078] missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
[12:14:56.088] info - Generating static pages (105/245)
Java
복사
이미 과거 글들을 새로운 DB로 옮기면서 보존하고 있지만 언제까지 이렇게 살순없다.
Vercel의 특성상 config로도 배포 제한 시간을 늘릴 수 없었고, 오히려 그 부분을 직접 건들이면 위반으로 바로 배포 취소가 되고있다.
결국 Notion DB를 활용할 수 있는 최적화된 서비스가 필요하다.
Tistory로 돌아가기엔 너무 먼길을 왔다.
ChatGPT와 얼마없는 레퍼런스들을 찾아다니면서, 이것저것 시도를 했지만 결국 배포 플랫폼의 한계를 벗어나지 못하고 있다. CDN 솔루션을 사용하더라도 결국 문제는 게시글이 이 블로그에 박히려면(임베디드) 페이지로딩이 필요하고, 글이 많아지면 결국 오버플로우되는것이 무한 반복될 예정이다. 결론적으로 가장 좋은것은 Notion DB 자체를 배포하는 방식이다.

현재 Hugo라는 서비스, 한국의 Woopi 등을 알아보고있다. Github.io로 할 수 있는 jykll 블로그를 생각하고 있지만, 내가 하고있는 방식의 서비스와 비슷하게 빌드타임이 크게 소모된다고한다. 그럼 결국에 수백개의 글을 앞으로도 계속 써나가야 하는데 문제가 발생할 것 같다. 우선 타이틀들만 알아뒀기 때문에 시간 여유가 생길때 이전해봐야겠다. 결국 Github page를 이용하게 될 것 같기도 하다.. 내가 프로그래밍을 처음 배울때 하고싶었지만 어려워보여서 도전못했었지만, 지금 Github page-NotionDB-Vercel의 배포 연관관계를 이해해 나가면서 해당 과정 또한 크게 다를바 없을 것 같다는 자신감이 생겼다. 세달전의 나와 다르고, 두달전의 나와 다르다.
우선 과거의 글들은 아직도 tistory에 남아있고,


NotionDB로 변환한 버전들은 내 비공개DB에 그대로 옮기면서 이 블로그의 새 공간을 만들고 있다. 마치 Java의 배열을 쓰는것처럼, 정해진 메모리로 초기화된 공간에서 글들을 비우고 새로운 글을 채워나가고 있다 ㅋㅋㅋ 빠르게 다음 배포 방식에서 블로그를 정착하고 싶다.. 이미 큰결심으로 블로그 플랫폼을 떠나 여기까지온거 어디까지 가나 해보자. 근대 생각보다 유목민처럼 블로그를 옮겨다니면서 뭔가 주섬주섬 배우는것들이 많다. 원래 이 목적 아니었는가?
이전 글을 정리 중에 Redeploy에서 빌드 타임이 갑자기 줄었다?
예전 Tistory에서 백업으로 받은 글들(HTML형식)을 복사 붙여넣기 하는 과정에서 뭔가 쓸모없는 데이터들이 많이 들어왔을 것 같다는 생각이 들었다. 특히 백업본에서 Tistory는 생각보다 용량이 컸었는데, 이것을 HTML을 연 상태에서 복사 해버리니 문제가 발생한것은 아닐까?? 마치 그 안의 태그들까지도 Notion에 그대로 다붙어버린 것이다.. 그러면 빌드 타임 오버플로우 문제가 이유가 명확해지긴한다. 그리고 이전부터 계속해서 문제가 있었던 Missing User와 관련된 문제. 이것 지금 생각해보니까 Tistory 글에는 나의 Google Adsense가 붙어 있을 텐데 그 태그의 user가 붙어서 들어온 것 같은 기분이 든다. 이것 때문에 Next.js로 구성된 내 블로그 소스를 다뒤집어 봤지만
이 알수없는 id의 출처는 아직도 알수가 없다. 보통 Notion DB는 배포시 c18asdf84d3asdf06123aae03117a7?pvs=4 처럼 ?pvs를 기준으로 왼쪽의 문자열이 ‘나’의 ID로 인식된다. 하지만 나의 DB 아이디는 아래 오류와 같이 0f23fed0 와는 전혀 상관이 없다.
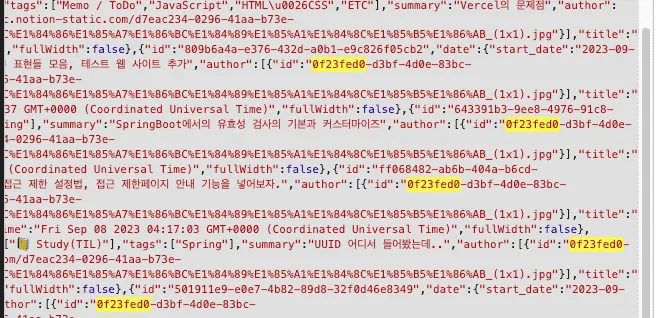
이는 빌딩 과정에서 내 글의 숫자만큼 오류까지는 아니지만 읽기를 실패하는 문제를 발생시키고 있고, 그 부분이 어디인지 페이지가 append되는 코드를 찾아내기도 했지만 거기 할당되는 값은 config파일로 내 아이디가 직접적으로 입력되지 않고, Vercel 에서 환경 변수처럼 수동 입력되도록 되어있다. 물론 올바른 값을 넣어두었다. 하지만 아직도 저값을 왜 찾는지 알수가 없다..
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
info - Generating static pages (160/217)
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
info - Generating static pages (162/217)
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
missing user 0f23fed0-d3bf-4d0e-83bc-1ecb8c4e0e9e
Java
복사
어쨋든 결과적으로 과거의 글(from Tistory)를 다른 DB로 옮기는 과정에서 빌드타임이 10분이나 단축되었다. 현재까지 이미지 최적화나 글을 정리해도 이정도 효과가 없었는데, 분명히 과거의 글을 붙여넣을때 쓸모없는 태그들이 함께 포함된 것이 분명하다. 왜냐하면 위 사진에서도 저 데이터들은 JSON 형태로 나타나고 있고, 만약에 태그들이 수도없이 많은 글을 복사했다면 그 내부 태그들 마저도 모두 String으로 변환되고 JSON으로 변환되는 등 필터링에만 엄청난 시간을 소요 했던 것으로 보여지고 있다.
내가 이것을 가장 쉽게 찾아내는 방법은 예전 글(이사오기 전 옮긴 글들)을 메모장 같은곳에 붙여넣어서 말그대로 텍스트만 뽑아서 재정렬 해보면 빌드 타임이 절반 이상 줄어들것 같은 느낌이 든다. 이게 효과적이라면 사실상 지금 글을 쓰는데 빌드타임이 크게 안늘어나는 것으로 봐서 거의 1000개 이상의 글을 쓸 수 있는 용량이 확보될 가능성이 보이고 있다.
아직도 정확한 원인은 모르지만, 결과적으로는 Next.js로 구성된 내 블로그 전체를 하나씩 뜯어 고치는데 익숙해져가고있다. 아직도 프레임워크를 사용하면서 내가 알지못하는 숨겨진 것들이 많다. 하지만 뭔가 키워드를 찾아내고 프로젝트 내에서 검색하고 대상 키워드들이 포함된 파일들을 필터링 해보면서 내가 지금 배우고있는 SpringBoot과 교차되면서 익숙해지는 부분들도 있는 것 같다.