


AI 모델(음성/이미지) 분석과 Colab(GPU) 환경에서 딥페이크 탐지 모델 훈련 이론(전처리, F1-Score)을 배우고, '미비한' 훈련(5 Epochs)과 '충분한' 훈련(50 Epochs)의 성능을 비교 분석한 뒤, 6일차에 사용할 최종 모델(.h5)을 저장합니다.
Table of Content

5일차: 딥페이크 탐지 앱 개발(1) 프로젝트

(슬라이드 1: 표지)
"안녕하십니까. 5일차 강의를 시작하겠습니다. 오늘은 '프로젝트를 통한 AI 역량강화 과정' 중 **'딥페이크 탐지 앱 개발(2) 프로젝트'**에 대해 다루겠습니다. 어제까지 만든 웹 애플리케이션의 뼈대에, 실제 지능을 불어넣는 AI 모델 파트를 집중적으로 학습하겠습니다."
부제: 데이터 전처리, 딥보이스 및 딥페이크 이미지 모델 분석과 훈련
Agenda: 5일차 학습 목표 및 일정
•
데이터 전처리: 개념 이해 및 딥페이크 탐지를 위한 기초 데이터 확보.
•
딥보이스 모델 분석: 음성 특징 학습 및 진위 판별 메커니즘 이해.
•
딥페이크 이미지 모델 탐색: 이미지 모델 아키텍처 비교 및 프로젝트 적용 모델 선정.
•
실습: Colab 환경에서 전처리, 모델 구축, 훈련 및 성능 평가 수행.
(슬라이드 2: 5일차 주요 학습 목표)
"오늘의 주요 학습 목표는 세 가지입니다.
첫째, **'데이터 전처리 개념'**을 익힙니다. 딥페이크 탐지의 기초 작업으로, 신뢰할 수 있는 모델을 만들기 위해 데이터를 어떻게 확보하고 가공하는지 배웁니다.
둘째, **'딥보이스 모델 분석'**입니다. 음성 데이터의 특징을 학습하고 진위를 판별하는 메커니즘을 이해하여 효율적인 탐지 방안을 모색합니다.
셋째, **'딥페이크 이미지 모델 탐색'**입니다. 다양한 이미지 탐지 모델 아키텍처를 비교하고, 우리 프로젝트에 적용 가능한 효율적인 모델을 선정하는 방법을 배웁니다."
(슬라이드 3: 주요 학습 내용)
"오늘 8시간 동안 다룰 주요 내용은 데이터 전처리, 딥보이스 모델 분석, 딥페이크 이미지 모델 탐색입니다.
실습과 이론을 균형 있게 제공하여 학습 효과를 극대화할 예정입니다. 여러분은 실습을 통해 이론적 지식을 직접 적용해 보고, 다양한 도구와 기술을 활용하여 딥페이크 탐지의 기초를 확립하게 될 것입니다."
모듈 1: 데이터 전처리 및 개요
(슬라이드 4: 데이터 전처리)
"먼저 **'데이터 전처리'**입니다.
데이터 전처리란, 데이터 분석이나 머신러닝 모델 학습과 같은 특정 작업을 수행하기 전에, 데이터를 다루기 쉬운 형태로 가공하는 과정을 말합니다. AI 성능의 8할은 이 전처리에서 결정된다고 해도 과언이 아닙니다."
1. 데이터 전처리
•
개념: 데이터 분석이나 머신러닝 모델 학습 전, 데이터를 다루기 쉬운 형태로 가공하는 과정.
•
도구:
◦
EDA (탐색적 데이터 분석): 통계적 기법으로 데이터 구조와 패턴 이해.
◦
Librosa: 음성 데이터 처리 및 분석 (MFCC 추출 등).
◦
OpenCV: 이미지 처리, 컴퓨터 비전, 증강 등에 사용.
(슬라이드 5: 데이터 분석 및 전처리 개요)
"구체적인 도구와 개념을 살펴보겠습니다.
먼저 **'EDA(탐색적 데이터 분석)'**입니다. 통계적 기법으로 데이터의 구조와 패턴을 이해하고 깊은 통찰력을 얻는 과정입니다.
음성 데이터 처리에는 'librosa' 라이브러리를 사용합니다. 다양한 오디오 분석 기능을 제공하며, 특히 음성의 특징인 MFCC 추출에 유용합니다.
이미지 처리에는 'OpenCV'를 활용합니다. 컴퓨터 비전 분야에서 널리 쓰이며, 이미지 전처리 및 증강을 위한 필수적인 도구입니다."
2. 손실 함수 (Loss Function)
•
모델 학습 시 예측 오차를 계산하여 가중치 업데이트에 사용.
•
Binary Crossentropy: 이진 분류 문제(진짜 vs 가짜)에 적합한 손실 함수. 잘못된 예측에 높은 손실 값을 부여하여 학습 방향 제시.
(슬라이드 6: 손실 함수와 성능 평가 지표)
"다음은 모델 학습의 핵심인 **'손실 함수'**와 **'성능 평가 지표'**입니다.
분류 모델의 성능을 평가하는 지표로는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1-score 등이 있습니다.
**손실 함수(Loss Function)**는 모델 학습 과정에서 사용됩니다. 모델의 예측 오차를 계산하여 가중치(매개변수)를 업데이트하는 데 쓰입니다. 이 값이 작을수록 모델 성능이 좋다는 뜻이며, 학습은 이 값을 줄이는 방향으로 진행됩니다."
(슬라이드 7: 손실 함수 설명)
"딥보이스 모델 훈련에서 손실 함수는 예측값과 실제값 간의 차이를 측정하는 중요한 역할을 합니다.
특히 'binary_crossentropy'는 우리가 다룰 이진 분류 문제(진짜 vs 가짜)에 적합합니다. 모델이 잘못된 예측을 하면 높은 손실 값을 발생시켜 학습 방향을 올바르게 잡아줍니다. 최적화 알고리즘은 이 손실 함수를 통해 파라미터를 조정하고 성능을 개선합니다."
3. 성능 평가 지표
•
정확도 (Accuracy): 전체 중 맞춘 비율. (불균형 데이터 시 주의 필요)
•
정밀도 (Precision): '가짜'로 예측한 것 중 실제 '가짜' 비율.
•
재현율 (Recall): 실제 '가짜' 중 놓치지 않고 맞춘 비율.
•
F1-Score: 정밀도와 재현율의 조화 평균. 모델의 종합적인 진단 능력 평가. (classification_report 활용) 속도, 비율 등 평균적인 변화율을 구할 때 사용되는 지표
(슬라이드 8: 주요 성능 평가 지표 설명)
"평가 지표를 하나씩 정의해 보겠습니다.
**'정확도(Accuracy)'**는 전체 중 모델이 맞춘 비율로, 성능을 간단히 측정할 때 씁니다.
**'정밀도(Precision)'**는 모델이 '양성(가짜)'이라고 예측한 것 중 실제 '양성'의 비율로, 모델의 신뢰도를 보여줍니다.
**'재현율(Recall)'**은 실제 '양성' 중에서 모델이 놓치지 않고 맞춘 비율로, 탐지 성능을 강화하는 데 필수적입니다."
(슬라이드 9: 성능 평가 지표 - 상세)
"성능 평가는 모델의 효과성을 판단하는 중요한 과정입니다. 정확도, 정밀도, 재현율, F1-Score 같은 지표들이 모델의 진단 능력을 평가합니다.
F1-Score: 정밀도와 재현율의 조화 평균. 모델의 종합적인 진단 능력 평가. (classification_report 활용) 속도, 비율 등 평균적인 변화율을 구할 때 사용되는 지표로 비율이 섞인 값의 평균이 조화평균이다.
Precision (정밀도):내가 ‘정답’이라고 판단한 것 중 실제 정답인 비율
Recall (재현율):실제 정답 중에서 내가 정답이라고 맞춘 비율
둘은 다른 차원의 정확도입니다.
•
Precision은 내가 한 선택의 질
•
Recall은 전체 중에서 내가 잘 포착했는지의 정도
•
두 값 중 하나라도 작으면 전체 성능이 나빠지는 구조
•
둘 다 크지 않으면 의미 없는 성능
•
Precision이 1이고 Recall이 0이면? → 전체 성능도 0이어야 한다
이런 상황에서는 산술평균은 적절하지 않습니다.
정밀도와 재현율이 둘 다 높아야 모델이 진짜 잘 작동하는 것
→ 어느 하나라도 낮으면 의미가 없고,
→ 둘 사이의 균형이 가장 중요하다
이 원리를 만족시키는 유일한 평균이 조화평균입니다. 수학적 의미: “동시적 기여”의 평균
이건 다음과 같은 상황에 딱 맞습니다:
•
"우리는 잘 맞춘 것도 중요하지만, 놓친 것도 중요하다"
•
"하나라도 못하면 전체는 무의미하다"
•
"균형이 중요하다"
1.
조화평균은 그런 구조를 정확히 반영하는 유일한 평균 방식입니다.작은 값에 민감하고, 균형이 중요하다는 원칙을 수학적으로 표현합니다.
2.
철학적으로, F1은 **‘성능은 두 능력의 동시 작용으로 구성된다’**는 생각에 기반하며,조화평균은 이런 ‘동시 기여의 구조’를 수학적으로 반영하는 방식입니다.
우리는 'scikit-learn' 라이브러리의 **classification_report**를 활용할 것입니다. 이 도구를 쓰면 이러한 지표들을 한 번에 쉽게 계산하고 해석할 수 있습니다. 이를 통해 모델의 성능을 시각적으로 파악하고 개선이 필요한 부분을 명확히 알 수 있습니다."
Part 1: 딥보이스(음성) 학습 (이론 & 실습)
(슬라이드 10: Part 1. 딥 보이스(음성) 학습)
"자, 이제 본격적인 첫 번째 파트, **'딥보이스(음성) 학습'**입니다. 딥보이스 음성 파일의 진위 여부를 학습하는 과정입니다."
1. 음성 데이터 전처리
•
Librosa: 음향 신호 분석 및 전처리 도구.
•
Waveform: 시간-진폭 그래프 (기본 형태).
•
Spectrogram: 시간-주파수 그래프 (주파수 성분 이해).
(슬라이드 11: 음성 데이터 전처리의 중요성 및 방법)
"음성 전처리의 핵심 도구와 이론입니다.
**'librosa'**는 음향 신호 분석과 전처리에 유용한 강력한 도구입니다.
**'Waveform'**은 시간에 따른 신호 변화를 보여주며 음성의 기본 형태를 분석합니다.
**'Spectrogram'**은 시간과 주파수의 관계를 시각적으로 표현하여, 음성 신호의 주파수 성분을 이해하는 데 도움을 줍니다. 우리는 이 Spectrogram을 통해 가짜 음성의 특징을 찾아낼 것입니다."
2. 딥보이스 모델 아키텍처
•
CNN (1D/2D): 음성 데이터의 특징 학습 및 패턴 인식.
◦
Conv2D: 입력 이미지(스펙트로그램)에서 특징 추출 (필터 사용).
◦
MaxPooling2D: 특징 맵 차원 축소, 연산량 감소, 과적합 방지.
◦
Dense: 학습된 특징을 종합하여 최종 예측 수행.
•
RNN/LSTM: 순차적 음성 데이터 처리, 시간 의존성 모델링 및 긴 시퀀스 정보 보존.
(슬라이드 12: 딥보이스 모델 아키텍처 설명)
"모델 아키텍처는 크게 CNN과 RNN/LSTM으로 나뉩니다.
**'CNN(1D/2D)'**은 음성 데이터에서 중요한 특징을 학습하여 패턴을 인식합니다. 1D는 시간적 특성을, 2D는 스펙트로그램(이미지) 처리에 효과적입니다.
**'RNN/LSTM'**은 순차적인 음성 데이터를 처리하는 데 특화되어 있습니다. 시간 의존성을 모델링하고 긴 시퀀스에서도 정보를 보존하는 강점이 있습니다.
간단히 비교하면 CNN은 공간적 특징에, RNN/LSTM은 시간적 정보 처리에 중점을 둡니다."
(슬라이드 13: 딥보이스 모델의 개념 및 구조)
"딥보이스 모델은 음성 데이터를 분석하여 특징을 학습하고 진위 여부를 판별하는 알고리즘입니다.
**'CNN'**은 1D 및 2D 데이터에서 특징을 추출하는 핵심 아키텍처 역할을 하며, **'RNN/LSTM'**은 시퀀스 데이터의 맥락을 유지하며 음성 인식 및 생성 작업에서 중요한 역할을 수행합니다."
(슬라이드 14: 딥보이스 모델 주요 레이어 기능 설명)
"모델을 구성하는 주요 레이어들입니다.
**'Conv2D 레이어'**는 입력 이미지(스펙트로그램)에서 특징을 추출하며, 여러 필터로 다양한 패턴을 인식합니다.
**'MaxPooling2D 레이어'**는 특징 맵의 차원을 줄여 연산량을 감소시키고 과적합을 방지합니다.
**'Dense 레이어'**는 마지막 단계에서 학습된 모든 특징을 종합하여 최종 예측을 수행합니다."
3. 딥보이스 학습 랩 (Colab 실습)
•
실습 목표:
◦
'미비한 학습(Epoch 5)' vs '충분한 학습(Epoch 50)' 성능(F1-Score) 비교.
◦
6일차 추론 서버용 model_audio.h5 파일 저장.
•
과정:
◦
AI Hub '음성' 데이터셋 업로드.
◦
Librosa로 MFCC 특징 추출.
◦
Train/Validation/Test 셋 분리 후 학습 진행.
(슬라이드 15: 딥보이스(음성) 학습 랩 (Colab 실습))
"이제 이론을 바탕으로 Colab 실습을 진행하겠습니다.
1.
실습 목표는 딥보이스 모델을 '미비하게(Epoch 5)' 훈련할 때와 '충분히(Epoch 50)' 훈련할 때의 성능(F1-Score) 차이를 비교하는 것입니다. 그리고 6일차 추론 서버에서 사용할 model_audio.h5 파일을 저장합니다.
2.
데이터 준비 단계에서는 AI Hub '음성' 데이터셋을 업로드하고, librosa로 MFCC 특징을 추출한 뒤, Train/Validation/Test 셋으로 분리합니다."
•
MFCC는 음성 신호의 중요한 특징을 추출하는 알고리즘으로, 오디오의 고유한 특성을 나타내는 수치입니다. 음성을 짧은 구간으로 나누어 각 구간의 멜 스펙트럼을 구한 뒤, 켑스트럴(Cepstral) 분석을 통해 최종적으로 얻어지는 계수(coefficient)입니다. 이는 음성 인식, 화자 인식, 음악 장르 분류 등 다양한 분야에서 활용됩니다.
1단계: Colab 환경 설정 및 라이브러리 설치
"먼저 Google Colab 노트북을 열어주세요. [런타임] 메뉴에서 **'런타임 유형 변경'**을 클릭하고 **'T4 GPU'**로 설정합니다. 저희가 50 Epoch까지 훈련시키려면 GPU가 필수입니다."
"새 코드 셀에 다음 코드를 입력하여 딥러닝과 음성 처리에 필요한 라이브러리들을 설치하고 임포트합니다."
먼저 다음 코드를 통해 후에 발생 할 수 있는 호환성 문제를 해결합니다
# [중요] Colab의 최신 TensorFlow가 구버전 방식(Keras 2)으로 작동하도록 강제 설정
# 이 셀을 실행한 후에는 반드시 [런타임] -> [세션 다시 시작]을 해야 적용됩니다.
# 1. 호환성 패키지 설치
!pip install tf_keras
# 2. 환경변수 설정 (TensorFlow 임포트 전에 해야 함)
import os
os.environ["TF_USE_LEGACY_KERAS"] = "1"
import tensorflow as tf
print("현재 설정된 버전:", tf.__version__)
Python
복사
# DeepVoice 모델 훈련을 위한 필수 라이브러리 설치
!pip install tensorflow keras librosa numpy scikit-learn pandas
import os
import librosa
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, classification_report, accuracy_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Dropout, BatchNormalization
# GPU 사용 확인 및 TensorFlow 로깅 레벨 설정
print("TensorFlow Version:", tf.__version__)
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
# 딥러닝 모델 저장 경로
MODEL_PATH = 'model_audio.h5'
TypeScript
복사
"Shift + Enter로 실행해 주세요. 설치가 완료되고 TensorFlow 버전이 출력되면 됩니다."
2단계: 데이터셋 준비 및 전처리 (MFCC 추출)
"다음으로 AI Hub에서 다운로드받은 딥보이스 학습 데이터를 Colab에 업로드합니다. (데이터는 train 폴더 안에 음성 파일들이 있으며, train.csv 파일에 파일명과 레이블이 정리되어 있는 형태로 가정합니다.)"
"CSV 파일을 로드하기 위해 Pandas를 사용합니다. 데이터프레임에서 파일 경로와 레이블을 읽어와 MFCC 특징으로 변환하고, 레이블을 **fake=1, real=0**으로 지정하는 작업을 진행하겠습니다."
# MFCC 특징 추출 함수 정의 (변동 없음)
def extract_mfcc(file_path, n_mfcc=40, max_len=100):
# 음성 파일에서 MFCC 특징을 추출하고 패딩을 적용함.
# :param file_path: 음성 파일 경로
# :param n_mfcc: 추출할 MFCC 개수
# :param max_len: 시퀀스 최대 길이 (패딩/절단 기준)
# :return: 패딩된 MFCC 배열
try:
# 1. Librosa를 사용해 음성 파일 로드
# NOTE: 음성 파일의 샘플링 레이트(sr)는 None으로 설정하여 원본 sr을 사용합니다.
y, sr = librosa.load(file_path, sr=None)
# 2. MFCC 특징 추출
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)
mfccs = mfccs.T
# 3. 패딩/절단 (최대 길이에 맞춤)
if mfccs.shape[0] > max_len:
mfccs = mfccs[:max_len, :] # 절단
elif mfccs.shape[0] < max_len:
# 패딩: 부족한 부분을 0으로 채움
pad_width = max_len - mfccs.shape[0]
# MFCCs는 (time, n_mfcc) 형태이므로, time 축에만 패딩을 적용
mfccs = np.pad(mfccs, ((0, pad_width), (0, 0)), mode='constant')
return mfccs
except Exception as e:
# 에러 발생 시 None 반환
print(f"Error processing {file_path}: {e}")
return None
# 데이터셋 로드 및 레이블 지정 (CSV 기반)
# Colab 환경에서 '딥보이스 학습데이터'가 마운트되었다고 가정하고 경로 설정
# train.csv와 train 폴더가 같은 경로에 있다고 가정합니다.
base_data_dir = './drive/MyDrive/딥보이스 학습데이터'
csv_path = os.path.join(base_data_dir, 'train.csv')
# 1. Pandas를 사용하여 CSV 파일 로드
print(f"CSV 파일 로드 경로: {csv_path}")
try:
df = pd.read_csv(csv_path)
except FileNotFoundError:
print("오류: train.csv 파일을 찾을 수 없음. 경로를 확인하십시오.")
df = pd.DataFrame()
# --- [수정된 핵심 부분: 데이터 샘플링] ---
# 전체 5만 개 데이터를 처리하는 것은 시간이 오래 걸리므로, 100개만 실습함.
SAMPLE_SIZE = 100
if len(df) > SAMPLE_SIZE:
# stratify=y를 적용하기 위해, 샘플링 전 레이블을 먼저 이진화
df['is_fake'] = df['label'].apply(lambda x: 1 if x == 'fake' else 0)
# 레이블(real/fake) 분포를 유지하며 2000개 샘플 추출 (stratified sampling)
df_sampled = df.groupby('is_fake').apply(lambda x: x.sample(n=SAMPLE_SIZE // 2, random_state=42)).reset_index(drop=True)
else:
df_sampled = df
print(f"데이터셋 전체 크기: {len(df)}")
print(f"실습을 위해 추출된 샘플 크기: {len(df_sampled)}")
# ---------------------------------------------
# 'path' 컬럼이 상대 경로('./train/...')를 가지고 있다고 가정
audio_folder_path = os.path.join(base_data_dir, 'train')
features = []
labels = []
max_len = 100 # 모든 시퀀스의 길이를 100으로 통일함
n_mfcc = 40
# 2. 샘플링된 데이터프레임을 순회하며 MFCC 특징 추출
print("MFCC 특징 추출 및 데이터 로딩을 시작함...")
for index, row in df_sampled.iterrows():
relative_path = row['path'] # 예: ./train/AAACWK.ogg
label_text = row['label'] # 예: real 또는 fake
# 실제 파일 경로 조합 (파일 이름만 추출하여 실제 폴더 경로와 조합)
filename = os.path.basename(relative_path)
file_path = os.path.join(audio_folder_path, filename)
# 레이블을 숫자로 변환: fake=1, real=0
label = 1 if label_text == 'fake' else 0
mfcc = extract_mfcc(file_path, n_mfcc=n_mfcc, max_len=max_len)
if mfcc is not None:
features.append(mfcc)
labels.append(label)
# NumPy 배열로 변환 및 데이터셋 분리
X = np.array(features)
y = np.array(labels)
# Train, Validation, Test 셋 분리
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42, stratify=y_temp)
print(f"총 데이터셋 크기: {len(X)}")
print(f"훈련 셋 크기: {len(X_train)}")
print(f"검증 셋 크기: {len(X_val)}")
print(f"테스트 셋 크기: {len(X_test)}")
print(f"MFCC 특징 모양 (Shape): {X_train.shape[1:]}")
TypeScript
복사

"MFCC 특징이 추출되고 데이터셋이 분리되면, 다음 단계로 넘어가겠습니다."

3단계: 모델 구축 및 컴파일 (1D CNN)
"이제 분리된 데이터를 학습할 모델을 Keras로 구축하겠습니다. 음성 데이터는 시계열이므로, 1D CNN 모델을 사용하겠습니다. 모듈 3에서 배웠던 Conv1D, MaxPooling1D, Dense 레이어들이 사용됩니다."
# 1D CNN 모델 구축
def build_1d_cnn_model(input_shape):
model = Sequential([
# 첫 번째 Conv1D 레이어: 32 필터, 커널 사이즈 5
Conv1D(filters=32, kernel_size=5, activation='relu', input_shape=input_shape),
BatchNormalization(),
MaxPooling1D(pool_size=2),
Dropout(0.3),
# 두 번째 Conv1D 레이어: 64 필터, 커널 사이즈 3
Conv1D(filters=64, kernel_size=3, activation='relu'),
BatchNormalization(),
MaxPooling1D(pool_size=2),
Dropout(0.3),
# 특징 평탄화
Flatten(),
# Dense 레이어
Dense(128, activation='relu'),
Dropout(0.5),
# 출력 레이어: 이진 분류이므로 1개 뉴런, Sigmoid 사용
Dense(1, activation='sigmoid')
])
# 모델 컴파일
model.compile(
optimizer='adam',
# 이진 분류이므로 binary_crossentropy 손실 함수 사용
loss='binary_crossentropy',
metrics=['accuracy']
)
return model
# 모델 생성
# NOTE: X_train.shape[1:]는 2단계 실행 후 정의되므로, 2단계 실행이 필수임.
mfcc_input_shape = X_train.shape[1:]
audio_model = build_1d_cnn_model(mfcc_input_shape)
audio_model.summary()
TypeScript
복사
"모델의 구조(summary())를 확인하시고,

레이어 (Layer Type) | Output Shape | 파라미터 수 (Param #) | 설명 (강의 포인트) |
conv1d | (None, 96, 32) | 6,432 | 입력 시퀀스 길이(100)가 필터 크기(5)를 통과하여 96으로 줄어들고, 32개의 특징(Filters)을 추출함. 음성 특징 학습의 시작점입니다. |
max_pooling1d | (None, 48, 32) | 0 | 시퀀스 길이가 절반(96 → 48)으로 줄어듭니다. 연산량 감소 및 과적합 방지 역할입니다. |
conv1d_1 | (None, 46, 64) | 6,208 | 더 깊은 특징(64개)을 추출합니다. |
flatten | (None, 1472) | 0 | 23 x 64 = 1472. 이후 Dense 레이어에 넣기 위해 모든 특징을 1차원으로 평탄화합니다. |
dense | (None, 128) | 188,544 | 추출된 특징을 기반으로 분류를 수행하는 심층 신경망(DNN) 역할을 합니다. 파라미터의 대부분이 이 레이어에 집중되어 있습니다. |
dense_1 | (None, 1) | 129 | 최종 **이진 분류(real vs. fake)**를 위한 출력 레이어입니다. Sigmoid 활성화 함수를 사용하여 0 또는 1에 가까운 확률을 출력합니다. |
Total params | 201,697 | 100개의 작은 샘플로 테스트하지만, 실제 모델은 20만 개 이상의 파라미터를 학습합니다. |
이제 **'미비한 학습'**부터 시작하여 성능을 비교해 보겠습니다."
4단계: 성능 비교 실습 (미비 vs 충분)
"모듈 4 실습의 핵심입니다. 학습량에 따른 F1-Score 변화를 확인하겠습니다. 우리는 5 Epoch와 50 Epoch를 비교할 것입니다."
# 성능 평가 함수
def evaluate_model(model, X, y):
"""모델을 평가하고 정확도와 F1-Score를 출력함."""
y_pred_proba = model.predict(X)
# Sigmoid 출력(0~1)을 이진 값(0 또는 1)으로 변환 (임계값 0.5)
y_pred = (y_pred_proba > 0.5).astype(int)
# F1-Score 계산
f1 = f1_score(y, y_pred)
acc = accuracy_score(y, y_pred)
# Classification Report 출력 (정밀도, 재현율, F1-Score 포함)
report = classification_report(y, y_pred, target_names=['Real (0)', 'Fake (1)'], output_dict=True)
print(f"\n--- 성능 평가 결과 ---")
print(f"테스트 셋 정확도: {acc:.4f}")
print(f"테스트 셋 F1-Score: {f1:.4f}")
print(classification_report(y, y_pred, target_names=['Real (0)', 'Fake (1)']))
return f1
# 1. 미비한 학습 (Epoch 5) 진행
print("--- 1. 미비한 학습 시작 (Epoch 5) ---")
# 주의: build_1d_cnn_model 함수는 3단계에서 정의됨
audio_model_5 = build_1d_cnn_model(X_train.shape[1:]) # 새 모델 생성
history_5 = audio_model_5.fit(
X_train, y_train,
epochs=5,
batch_size=32,
validation_data=(X_val, y_val),
verbose=1
)
f1_5 = evaluate_model(audio_model_5, X_test, y_test)
print(f"최종 (Epoch 5) F1-Score: {f1_5:.4f}")
# 2. 충분한 학습 (Epoch 50) 진행
print("\n--- 2. 충분한 학습 시작 (Epoch 50) ---")
# 주의: build_1d_cnn_model 함수는 3단계에서 정의됨
audio_model_50 = build_1d_cnn_model(X_train.shape[1:]) # 새 모델 생성
history_50 = audio_model_50.fit(
X_train, y_train,
epochs=50,
batch_size=32,
validation_data=(X_val, y_val),
verbose=0 # 출력 간소화
)
f1_50 = evaluate_model(audio_model_50, X_test, y_test)
print(f"최종 (Epoch 50) F1-Score: {f1_50:.4f}")
TypeScript
복사

"콘솔에서 출력되는 **'F1-score'**를 비교해 보세요. 학습량이 늘어남에 따라 F1-score가 크게 향상되는 것을 확인할 수 있습니다."
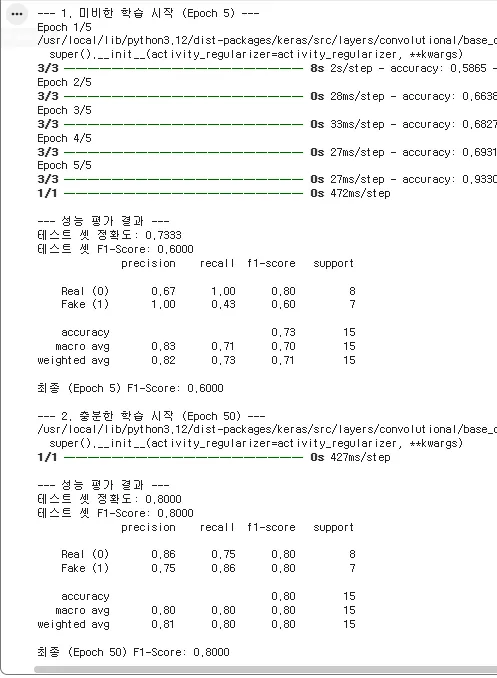
반대로 실행 시 마다 오히려 F1-Score가 충분한 학습이 낮은 경우도 발생 할 수 있습니다. 또한 실행 시 마다 F1-Score가 극도로 차이나는 경우도 있을 수 있습니다.

•
1. Epoch 5 > Epoch 50 성능 역전 현상 (과적합의 심화)
"이 현상은 **과적합(Overfitting)**이 매우 빠르게 진행되었음을 보여줍니다.
◦
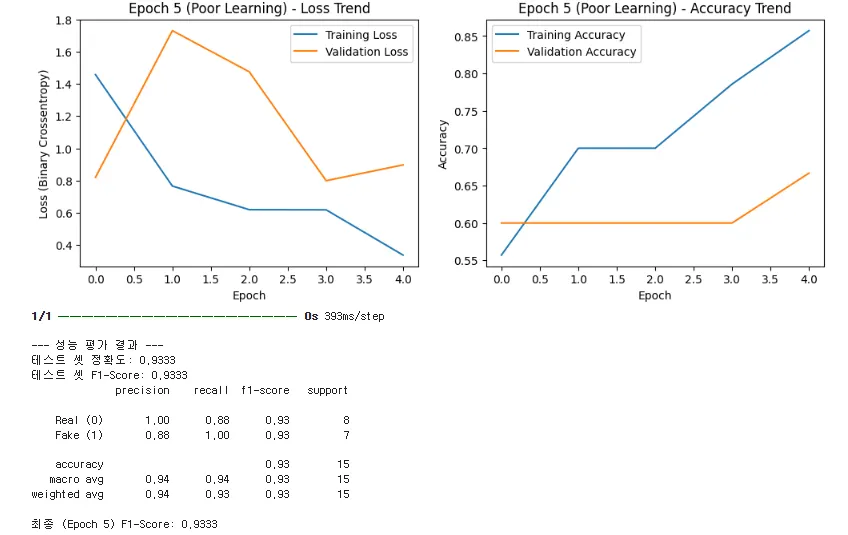
"먼저, 테스트 셋에서 F1-Score 0.9333이라는 높은 점수를 기록했던 Epoch 5 모델의 그래프를 보십시오.
▪
Loss Trend (손실 추이 - 왼쪽): 훈련 손실(파란색)은 꾸준히 떨어져 0.4 근처까지 갑니다. 하지만 **검증 손실(주황색)**은 Epoch 1 이후부터 Loss가 1.5에서 0.8 사이를 크게 요동치는(Fluctuation) 모습을 보입니다.
▪
Accuracy Trend (정확도 추이 - 오른쪽): 훈련 정확도(파란색)는 0.85까지 빠르게 오르지만, 검증 정확도(주황색)는 0.60 수준에서 거의 정체되어 있습니다.
▪
결론: F1-Score는 높지만, 훈련 셋과 검증 셋의 성능 차이가 Epoch 1부터 벌어지고 있습니다. 이는 모델이 **훈련 데이터의 특징만 빠르게 '편향 학습'**했거나, 15개라는 작은 테스트 셋에 우연히 잘 맞춰진 상태임을 의미합니다. 이 모델을 배포하면 다른 새로운 데이터에서는 성능이 급락할 수 있는 극도로 불안정한 초기 모델입니다."
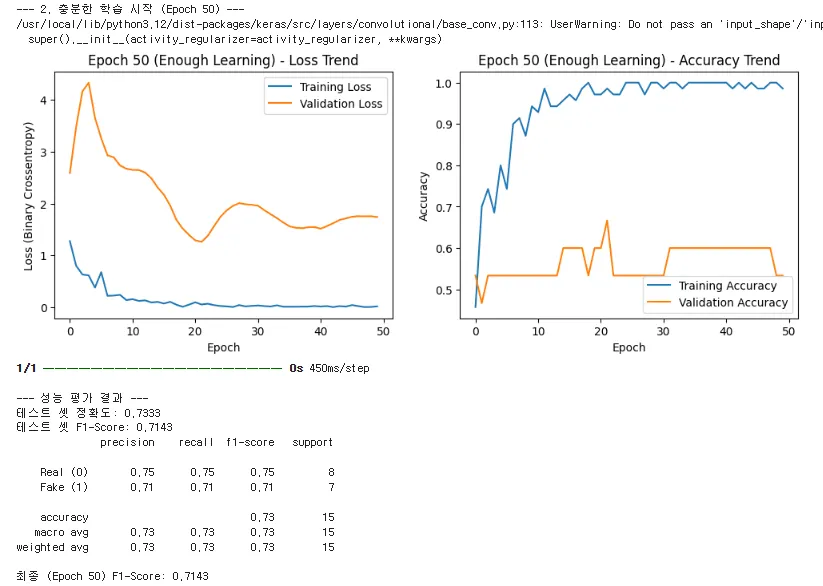
◦
"다음은 Epoch 50까지 지속적으로 훈련했을 때의 그래프입니다. 최종 F1-Score는 0.7143으로 오히려 낮아졌습니다.
▪
Loss Trend (손실 추이 - 왼쪽):
•
훈련 손실(파란색)은 Epoch 50까지 0에 가깝게 하락합니다. 이는 모델이 훈련 셋을 완벽하게 암기했다는 뜻입니다.
•
*검증 손실(주황색)**을 보십시오. Epoch 10~20 사이에서 잠깐 최저점을 찍은 후, 그 이후부터는 Loss가 다시 상승(Rebound)하거나 1.5~2.0 사이에서 정체하며 파란색 선과 크게 벌어집니다.
▪
기울기의 교육적 의미 (과적합 증명): 이 두 선의 기울기가 벌어지는 지점이 바로 모델이 일반적인 패턴을 놓치고 훈련 셋의 노이즈까지 암기하는(Overfitting) 단계로 넘어갔다는 명확한 시각적 증거입니다.
▪
결론: 이 모델은 학습량이 '충분'했음에도 불구하고 데이터가 적어 훈련 셋에 완전히 종속되었고, **범용성(Generalization)**을 상실하여 테스트 셋의 성능이 오히려 떨어진 것입니다.
•
2. 실행 시마다 F1-Score가 크게 차이 나는 이유 (무작위성)
"다음으로, 이 코드를 다시 실행할 때마다 성능(F1-Score)이 크게 차이 나는 경우가 발생할 수 있습니다. 그 이유는 두 가지 무작위성(Randomness) 때문입니다."
◦
가중치 초기화 (Weight Initialization):
▪
신경망을 만들 때, 초기 가중치(Weight)는 난수(Random Number)로 설정됩니다. 우리가 build_1d_cnn_model 함수를 Epoch 5와 Epoch 50에서 각각 호출했기 때문에, 두 모델은 서로 다른 출발점에서 학습을 시작했습니다.
▪
실행할 때마다 이 초기 가중치가 달라지므로, 학습 경로가 바뀌어 최종 성능에 큰 영향을 미칩니다.
◦
데이터 분할 및 샘플링 (Data Splitting & Sampling):
▪
우리는 100개의 작은 샘플을 무작위로 추출(df.sample())했고, 이를 다시 훈련(70), 검증(15), 테스트(15) 셋으로 무작위 분할했습니다.
▪
만약 이번 실행에서 **Fake 데이터의 '쉬운 샘플'**이 테스트 셋 15개에 포함되었다면 F1-Score가 높게 나오고, **'어려운 샘플'**이 포함되었다면 낮게 나옵니다. 테스트 셋이 15개로 너무 작기 때문에, 샘플 하나하나의 영향력이 극대화되어 성능 변동성이 매우 커집니다.
"이 실습은 모델이 훈련 데이터에 과의존하게 되는 위험성과, 데이터 양의 중요성을 명확하게 보여줍니다. 실제 프로젝트에서는 다음 조치를 취해야 합니다."
◦
데이터 확보: 100개가 아닌 최소 수천 개 이상의 균형 잡힌 데이터를 사용해야 합니다.
◦
조기 종료 (Early Stopping): 훈련 과정 중 검증 셋(validation_data)의 손실이 더 이상 개선되지 않으면 학습을 중단하는 '조기 종료' 기법을 적용하여 과적합을 방지해야 합니다.
•
3. 안정적인 모델 선택을 위한 최종 기준 (Golden Rule)
"이 두 그래프를 통해 얻을 수 있는 가장 중요한 교훈은 이것입니다.
1.
모델의 안정성은 테스트 셋 F1-Score 최고점이 아니라, 훈련 손실(파란색)과 검증 손실(주황색)이 가장 가깝게 붙어 함께 하락하는 Epoch 지점에서 결정됩니다.
2.
실제 현업에서는 Validation Loss가 상승하기 직전인, Epoch 10~20 사이의 모델을 **'가장 안정적인 모델'**로 선택해야 합니다. 이것이 바로 조기 종료(Early Stopping) 기법의 핵심 원리입니다."
•
테스트 샘플을 1000개로 늘려 그래프 추이등 모습도 살펴보고자합니다. 시간이 좀 소요되므로 해당 그래프를 살펴봐주세요

◦
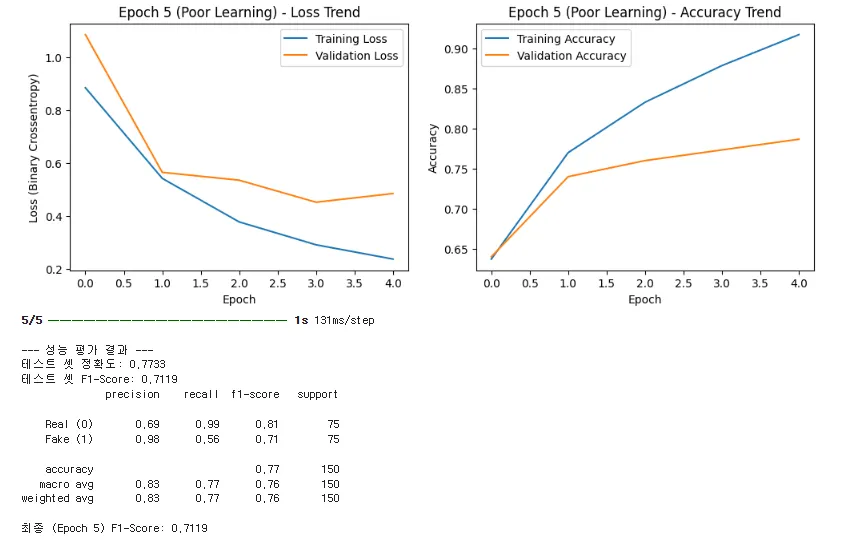
먼저 샘플은 10배로 늘렸지만 부족한 학습 그래프입니다.
▪
Loss Trend (손실 추이): 훈련 손실(파란색)과 검증 손실(주황색)이 Epoch 0부터 4까지 거의 붙어서 함께 하락합니다.
▪
안정성의 증거: 100개 샘플 때처럼 검증 손실이 1.0 이상으로 폭발하거나 크게 요동치지 않습니다. 이는 1,000개의 데이터가 모델의 초반 학습에 안정적인 가이드라인을 제공했음을 의미합니다. 모델이 훈련 셋의 노이즈만 따라가지 않고, 일반적인 특징을 배우고 있다는 뜻입니다.
▪
결론: Epoch 5만으로는 아직 학습이 부족하지만, 매우 안정적인 출발점을 확인했습니다.
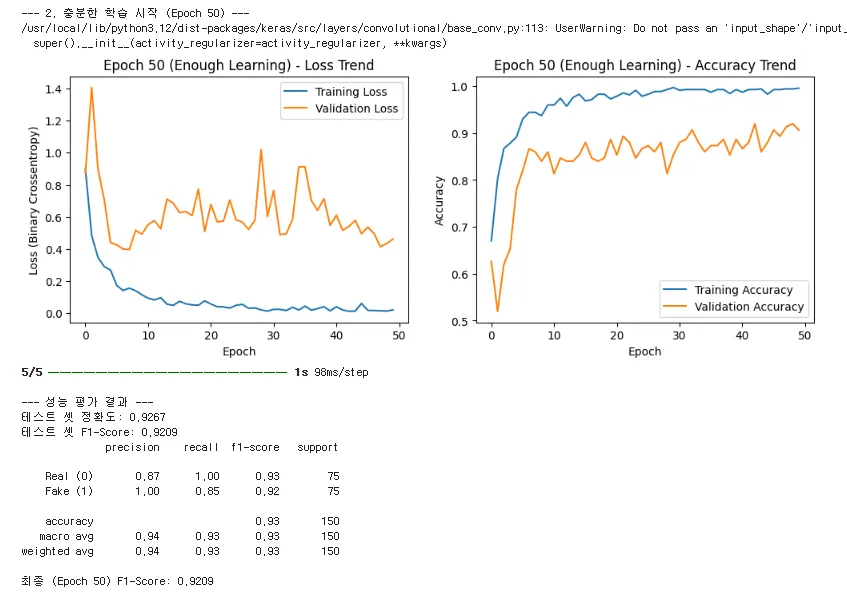
◦
두 번째 그래프: Epoch 50 (충분 학습, 1,000개 샘플) 분석
"이제 Epoch 50까지 훈련한 결과를 보겠습니다. 이 그래프가 바로 '안정적이고 잘 훈련된 모델'의 전형적인 모습입니다."
▪
최종 성능 확인: 테스트 셋 F1-Score가 0.9209로 매우 높게 나왔습니다. 이는 모델이 진짜와 가짜를 높은 신뢰도로 구분할 수 있음을 의미합니다.
▪
Loss Trend (손실 추이) 분석:
1.
초기 하락 (Epoch 0~10): 두 Loss 선이 급격히 하락하며 패턴을 빠르게 습득합니다.
2.
안정적인 격차 (Epoch 10 이후): 훈련 손실(파란색)은 0에 가까이 계속 하락하지만, 검증 손실(주황색)은 0.5 수준에서 비교적 안정적인 선을 유지합니다.
3.
과적합 판단 기준 (Golden Rule): 훈련 손실과 검증 손실 사이에 **'안정적인 간격'**이 생겼습니다. 이 간격은 모델이 **'훈련 셋에만 더 잘 맞추는 노력'**을 하고 있음을 보여주는 일반적인 과적합의 증거이지만, 검증 손실이 폭발적으로 상승하지 않고 유지된다는 점에서 모델의 일반화 능력이 유지되고 있다고 판단합니다.
▪
Accuracy Trend (정확도 추이) 분석:
•
두 정확도 선이 모두 0.9(90%) 이상에서 수렴하며, 특히 검증 정확도(주황색)가 안정적으로 높게 유지됩니다. 이는 모델이 처음 보는 데이터에 대해서도 90% 이상의 정확도를 신뢰성 있게 보인다는 뜻입니다.
•
"1,000개의 샘플을 사용한 결과, 우리는 신뢰할 수 있는 모델을 확보했습니다.
◦
과적합 판단 기준: 검증 손실(주황색 선)이 급격히 상승하거나 불규칙하게 요동치면 불안정하지만, 지금처럼 일정 선을 유지하면 학습을 지속해도 좋다고 판단합니다.
◦
선택: 우리는 이 **Epoch 50 모델(audio_model_50)**을 저장하여 6일차 FastAPI 서버에 탑재하겠습니다. 이 모델이 가장 높은 F1-Score와 안정적인 학습 추이를 동시에 보여주었기 때문입니다."
5단계: 최종 모델 파일 저장 및 확보
"성능이 가장 좋은 모델, 즉 50 Epoch까지 훈련된 모델을 6일차 FASTAPI 서버에서 사용할 수 있도록 저장하겠습니다. 모듈 6 실습의 목표입니다."
# 50 Epoch 모델을 최종 파일로 저장
# 파일명: model_audio.h5 (6일차 FastAPI 서버용)
# NOTE: audio_model_50은 4단계 실행 후 정의됨
audio_model_50.save('model_audio.h5')
print("최종 딥보이스 모델 'model_audio.h5' 저장을 완료함.")
TypeScript
복사
"파일 탐색기(왼쪽 폴더 아이콘)에서 model_audio.h5 파일을 확인하고, 다운로드 명령어를 실행하여 로컬 PC로 확보합니다."
"이것으로 딥보이스 모델 훈련 실습을 마쳤습니다. 잠시 후 딥페이크 이미지 모델 훈련을 시작하기 전에 질문 있으시면 말씀해 주세요."
•
결론: 이 모델은 '음성의 소리 패턴(주파수 분포)' 중에서도 **딥페이크 생성 과정에서 손상되거나 변조된 인공적인 흔적(Artifact)**을 주로 학습하도록 시킨 것입니다.
2. 코드에서 해당 부분이 표현된 방식
코드는 'MFCC 추출' 단계와 '모델 구조' 단계에서 이러한 특징 학습 목표를 명확하게 표현하고 있습니다.
A. 특징 추출 단계 (deepvoice_mfcc_extractor.py)
MFCC를 추출하도록 명시한 부분이 이 모델의 학습 목표를 결정했습니다.
◦
표현된 부분: librosa.feature.mfcc(..., n_mfcc=40)
◦
의미: 이 코드는 음성 데이터에서 40개의 MFCC 특징을 추출하도록 명시합니다. 즉, 모델에게 **'다른 복잡한 데이터는 무시하고, 이 40개의 성도 특징 벡터만 가지고 진짜와 가짜를 구분하라'**고 지시한 것입니다.
B. 모델 구조 단계 (deepvoice_model_build.py)
MFCC 특징을 어떻게 분석할지 구조적으로 표현했습니다.
◦
표현된 부분: Conv1D 레이어
◦
의미: MFCC는 시간 순서를 가진 데이터 시퀀스입니다. Conv1D는 이 시퀀스를 따라 **커널 사이즈(5 또는 3)**만큼의 짧은 패턴을 이동하며 학습합니다.
▪
예를 들어, kernel_size=5는 5개의 시간 단위(프레임) 동안 발생하는 40가지 MFCC 특징들의 패턴을 동시에 분석하여, 이 5개 프레임 내에 딥페이크의 미세한 왜곡이 있는지 없는지를 검출하는 필터 역할을 합니다.
결론적으로, 이 코드는 **"MFCC 특징 40개"**를 입력으로 받아, **"Conv1D 필터"**를 이용해 시간의 흐름 속에서 딥페이크 음성의 미세한 왜곡 패턴을 찾아내도록 최적화된 것입니다.
모델의 탐지 정확도:
◦
테스트 셋 정확도 (Accuracy): 0.9600 (96.00%)
◦
테스트 셋 F1-Score: 0.9583 (95.83%)
이 결과는 1,000개의 샘플로 훈련한 모델이 테스트 데이터에서 96%의 매우 높은 성능을 보였다는 것을 의미합니다.
이 결과의 의미 (강의 보충)
이 결과는 다음과 같이 해석하고 교육할 수 있습니다.
1.
높은 정확도 (Accuracy 0.9600): 모델이 전체 예측 중 **96%**를 성공적으로 맞췄다는 뜻입니다. (Real을 Real로, Fake를 Fake로 맞춘 비율)
2.
높은 F1-Score (0.9583): 딥페이크 탐지처럼 **이진 분류 문제(Real vs. Fake)**에서는 정확도보다 F1-Score가 더 중요합니다. F1-Score는 **정밀도(Precision)**와 **재현율(Recall)**을 모두 고려한 지표입니다.
•
F1-Score가 0.9583이라는 것은, 모델이 **'가짜라고 예측하는 신뢰도(정밀도)'**와 '실제 가짜를 놓치지 않고 잡아내는 능력(재현율)' 모두가 매우 높고 균형 잡혀 있음을 의미합니다.
결론: 이 모델은 현재까지의 테스트 데이터 기준으로 매우 안정적이고 신뢰할 만한 딥페이크 탐지 성능을 보인다고 판단할 수 있습니다.
Part 2: 딥페이크(이미지) 학습 (이론 & 실습)
(슬라이드 16: Part 2. 딥 페이크(이미지) 학습)
"다음은 두 번째 파트, **'딥페이크(이미지) 학습'**입니다. 이미지 파일의 진위 여부를 학습합니다."
1. 이미지 데이터 전처리
•
OpenCV: 이미지 분석 및 조작 (리사이징 등).
•
Pillow: 이미지 파일 형식 변환 및 필터 적용.
•
데이터 증강 (Data Augmentation): 기존 이미지를 변형(회전, 반전 등)하여 추가 데이터 생성, 모델 일반화 능력 향상.
(슬라이드 17: OpenCV 활용법 및 전처리)
"이미지 전처리의 핵심입니다.
**'OpenCV'**는 이미지 분석과 조작을 위한 강력한 라이브러리입니다.
**'Pillow'**는 이미지 파일 형식 변환과 필터 적용이 용이한 라이브러리입니다.
가장 중요한 개념은 **'데이터 증강(Data Augmentation)'**입니다. 모델의 일반화 능력을 향상시키기 위해 기존 이미지를 변형(회전, 반전 등)하여 추가 데이터를 생성하는 방법입니다."
2. 딥페이크 이미지 탐지 모델
•
목표: 비정상적인 아티팩트를 확인하여 진위 판별.
•
주요 모델 (오픈소스):
◦
XceptionNet: 깊은 합성곱 신경망, 효율적인 특징 추출로 이미지 분류 성능 극대화.
◦
EfficientNet: 스케일링 기술로 성능과 효율성을 동시에 개선.
•
모델 선정 기준: 성능(정확도, 재현율 등), 경량성(시스템 자원 소모), 구현 용이성.
(슬라이드 18: 딥페이크 이미지 탐지 개요 및 모델 선정)
"딥페이크 이미지 탐지의 목표는 비정상적인 아티팩트를 확인하여 진위를 판별하는 것입니다.
주요 오픈소스 모델로는 **'XceptionNet'**과 **'EfficientNet'**이 있으며, 성능과 경량성 면에서 높은 평가를 받습니다.
모델 선정 시에는 성능, 경량성, 구현 용이성을 기준으로 프로젝트에 적합한 모델을 선택해야 합니다."
(슬라이드 19: 주요 오픈소스 딥페이크 탐지 모델)
"각 모델의 특징입니다.
**'XceptionNet'**은 깊은 합성곱 신경망으로, 효율적인 특징 추출을 통해 이미지 분류 성능을 극대화합니다.
**'EfficientNet'**은 스케일링 기술을 사용하여 성능과 효율성을 동시에 개선한 모델입니다.
우리는 이들 중 성능, 경량성, 구현 용이성을 고려하여 실제 프로젝트에 최적화된 선택을 해야 합니다."
(슬라이드 20: 모델 선정 기준 - 상세)
"다시 한번 모델 선정 기준을 정리합니다.
성능은 정확도와 재현율 같은 지표로 평가되고, 경량성은 시스템 자원 소모를 고려합니다. 구현 용이성은 코딩 및 통합의 간편함을 의미합니다. 팀별로 이 기준에 따라 각 오픈소스 모델의 장단점을 비교하고 최적의 선택을 하게 됩니다."
3. 딥페이크 학습 랩 (Colab 실습)
•
실습 목표:
◦
'미비한 학습(Epoch 5)' vs '충분한 학습(Epoch 50)' 성능(F1-Score) 비교.
◦
6일차 추론 서버용 model_image.h5 파일 저장.
•
과정:
◦
AI Hub '이미지' 데이터셋 업로드.
◦
OpenCV로 리사이징 및 정규화.
◦
ImageDataGenerator로 데이터 증강 적용 후 학습 진행.
(슬라이드 21: 딥페이크(이미지) 학습 랩 (Colab 실습))
"마지막으로 이미지 학습 Colab 실습입니다.
1.
실습 목표는 딥페이크 이미지 모델을 '미비하게' 훈련할 때와 '충분히' 훈련할 때의 성능(F1-Score) 차이를 비교하는 것입니다. 그리고 6일차 추론 서버용 model_image.h5 파일을 저장합니다.
2.
데이터 준비 단계에서는 AI Hub '이미지' 데이터셋을 업로드하고, OpenCV로 리사이징 및 정규화를 수행하며, **ImageDataGenerator*로 데이터 증강을 적용합니다."
1단계: Colab 환경 설정 및 라이브러리 준비
"딥보이스 실습에서 이미 설치한 대부분의 라이브러리를 재사용합니다. 이미지 탐지에 필요한 OpenCV와 전이 학습 모델인 XceptionNet을 위한 준비를 진행합니다."
호환성 문제 해결을 위하여 해당 코드를 먼저 실행합니다.
# [1블럭 수정] Keras 2 (Legacy) 강제 설정
# 주의: 이 셀 실행 후 혹시 뭔가 꼬이면 [런타임] -> [세션 다시 시작]을 하세요.
import os
# 1. 환경 변수 설정 (무조건 tensorflow import보다 먼저!)
os.environ["TF_USE_LEGACY_KERAS"] = "1"
# 2. 패키지 설치
!pip install tf_keras
import tensorflow as tf
import tf_keras
# 3. 설정 확인 (에러 없이 경로 확인)
print(f"TensorFlow Version: {tf.__version__}")
print(f"Current tf.keras implementation: {tf.keras}")
# tf.keras 출력 결과에 'tf_keras' 라는 단어가 포함되어 있으면 성공입니다.
if "tf_keras" in str(tf.keras):
print("\n" + "="*50)
print("✅ 설정 성공! 구버전(Legacy) Keras가 적용되었습니다.")
print("이제 'batch_shape' 오류 없이 서버에서 모델을 읽을 수 있습니다.")
print("="*50 + "\n")
else:
print("\n" + "!"*50)
print("⚠️ 경고: 설정이 완벽하지 않을 수 있습니다.")
print("하지만 일단 진행해 보세요. 에러 메시지가 'tf_keras'를 가리키고 있다면 작동할 겁니다.")
print("!"*50 + "\n")
Python
복사
"이 코드를 실행하여 이미지 탐지에 필요한 라이브러리들과 환경 변수(IMG_SIZE, BATCH_SIZE 등)를 설정하십시오."
# 필요한 라이브러리 임포트
import cv2 # 영상/이미지 처리 (OpenCV)
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt # 학습 추이 시각화용
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.applications import Xception # 전이 학습 모델 (XceptionNet) 로드
from tensorflow.keras.callbacks import ModelCheckpoint
# 딥러닝 모델 저장 경로
MODEL_IMAGE_PATH = 'model_image.h5'
# 이미지 해상도 설정 (XceptionNet 표준 권장 해상도에 맞춰 244x244 or 299x299 사용)
IMG_SIZE = (299, 299)
BATCH_SIZE = 32
TypeScript
복사

2단계: 데이터셋 준비 및 전처리 (영상 프레임 추출 및 로드)
"딥페이크 영상 데이터를 학습용 이미지로 변환하는 핵심 전처리 과정입니다.
우선 샘플로 진짜와 변조 이미지를 드리겠습니다. AI 허브에서 준비한 위변조 학습 데이터는 영상 형태기 때문에 특정 프레임들을 추출하여 이미지로 준비하였습니다. OpenCV를 사용하여 프레임을 추출합니다. 매우 오랜시간이 걸리기 때문에 미리 진행한 샘플을 준비했습니다.
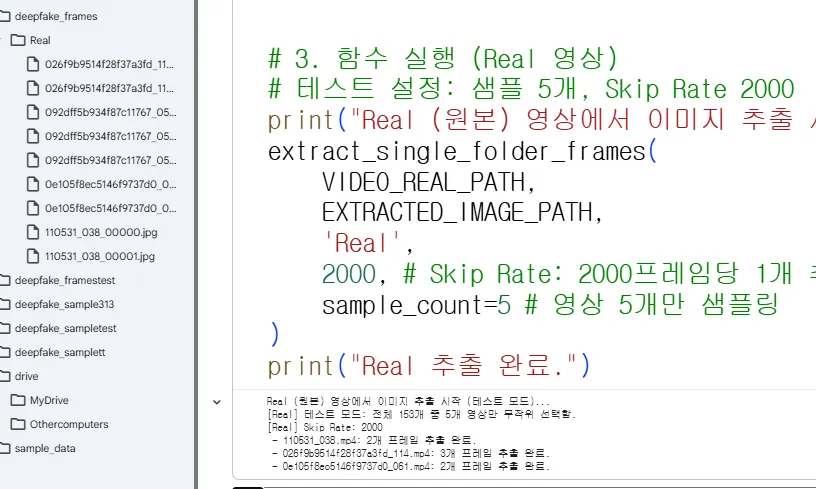
영상에서 이미지 추출 코드(Real), OpenCV의 얼굴 인식 기능(Haar Cascade)을 사용해 얼굴 인식 추출
영상에서 이미지 추출 코드(Fake)
준비된 학습 데이터를 ImageDataGenerator를 사용해 로드 및 데이터 증강을 적용합니다."
데이터 증강이 적용된 Train/Validation Generator를 생성합니다."
# ----------------------------------------------------------------------
# 3단계: 이미지 데이터 로드 및 증강 (ImageDataGenerator)
# ----------------------------------------------------------------------
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
# 1. 경로 및 하이퍼파라미터 설정
# 2단계에서 추출된 이미지가 저장된 상위 폴더 경로
EXTRACTED_IMAGE_PATH = './drive/MyDrive/딥페이크 학습데이터/deepfake_frames'
# XceptionNet 권장 입력 크기 (224)
IMG_SIZE = (224, 224)
BATCH_SIZE = 32
# 데이터가 제대로 준비되었는지 경로 확인
if not os.path.exists(EXTRACTED_IMAGE_PATH):
print(f"오류: 데이터 경로 '{EXTRACTED_IMAGE_PATH}'가 존재하지 않습니다. 2단계 실습을 먼저 완료해 주세요.")
else:
print(f"데이터 경로 확인됨: {EXTRACTED_IMAGE_PATH}")
print(f"내부 폴더: {os.listdir(EXTRACTED_IMAGE_PATH)}")
print("\n3단계: 데이터 증강(Data Augmentation) 설정 및 Generator 생성을 시작합니다...")
# 2. ImageDataGenerator 정의 (데이터 증강 및 전처리)
# - rescale: 픽셀 값을 0~255에서 0~1 사이로 정규화
# - rotation, shift, flip: 이미지를 무작위로 변형하여 데이터 다양성 확보 (과적합 방지)
# - validation_split: 전체 데이터의 20%를 검증용으로 자동 분리
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20, # 랜덤 회전 (20도 이내)
width_shift_range=0.2, # 랜덤 가로 이동
height_shift_range=0.2, # 랜덤 세로 이동
horizontal_flip=True, # 랜덤 좌우 반전
fill_mode='nearest', # 빈 공간 채우기 방식
validation_split=0.2 # 20%는 검증 데이터로 사용
)
# 3. 학습용 데이터 생성기 (Training Generator)
# subset='training'으로 설정하여 학습 데이터만 로드
print("\n[학습 데이터셋 로드 중...]")
train_generator = train_datagen.flow_from_directory(
EXTRACTED_IMAGE_PATH,
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='binary', # Real(0) vs Fake(1) 이진 분류
subset='training' # 학습용 데이터
)
# 4. 검증용 데이터 생성기 (Validation Generator)
# subset='validation'으로 설정하여 검증 데이터만 로드
# 주의: 검증 데이터에는 증강을 적용하지 않는 것이 일반적이나,
# 여기서는 코드 간소화를 위해 동일한 datagen 객체의 split 기능을 사용합니다.
print("\n[검증 데이터셋 로드 중...]")
validation_generator = train_datagen.flow_from_directory(
EXTRACTED_IMAGE_PATH,
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='binary', # Real(0) vs Fake(1) 이진 분류
subset='validation' # 검증용 데이터
)
# 5. 클래스 인덱스 확인
# 폴더 이름(Real, Fake)이 어떻게 0과 1로 매핑되었는지 확인
print("\n클래스 매핑 정보:", train_generator.class_indices)
print("3단계: 데이터셋 준비 완료. 이제 모델 구축 단계로 넘어갈 수 있습니다.")
Python
복사
3단계: 딥페이크 탐지 모델 구축 및 컴파일 (XceptionNet 기반)
"딥페이크 이미지 탐지에 최적화된 XceptionNet 아키텍처를 전이 학습 방식으로 활용하여 모델을 구축하겠습니다. **base_model 가중치는 동결(Freeze)**하고, 최상단 분류 레이어만 새로 학습시킵니다."
XceptionNet 기반 모델 구축
# ----------------------------------------------------------------------
# 4단계: 딥페이크 탐지 모델 구축 (XceptionNet 기반 전이 학습)
# ----------------------------------------------------------------------
import tensorflow as tf
from tensorflow.keras.applications import Xception
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout
# 1단계에서 설정한 IMG_SIZE 사용
# 만약 1단계 실행을 안 했다면 아래 주석 해제
# IMG_SIZE = (299, 299)
def build_xception_model(input_shape):
# 1. 사전 학습된 모델 로드 (ImageNet 가중치 사용, Top 층 제외)
base_model = Xception(weights='imagenet', include_top=False, input_shape=input_shape)
# 2. 핵심: 베이스 모델의 가중치 동결 (Freeze)
# 학습된 특징 추출 능력을 유지하기 위해 업데이트를 막음
base_model.trainable = False
# 3. 새로운 분류기(Classifier) 추가
model = Sequential([
base_model,
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5), # 과적합 방지
Dense(1, activation='sigmoid') # 이진 분류 (Real vs Fake)
])
# 4. 모델 컴파일
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
return model
print("3단계: 모델 구축 시작...")
# 모델 생성
image_input_shape = IMG_SIZE + (3,) # (299, 299, 3)
image_model = build_xception_model(image_input_shape)
# 모델 구조 및 파라미터 확인
image_model.summary()
print("\n[확인 포인트] Summary 하단의 'Non-trainable params' 숫자를 확인하십시오.")
print("이 숫자가 0이 아니라면, XceptionNet의 가중치가 성공적으로 동결된 것입니다.")
Python
복사
"모델 구조(summary())를 확인하시고, **Non-trainable params(동결된 파라미터)**가 대부분을 차지하는 것을 확인하십시오."
이 부분은 **전이 학습(Transfer Learning)**의 핵심 개념을 다루는 중요한 단계입니다.
1. 가중치 동결 (Weight Freezing) 개념 설명
•
XceptionNet은 이미 방대한 이미지 데이터(ImageNet)로 **'이미지의 일반적인 특징(선, 면, 질감 등)'**을 잘 추출하도록 훈련된 모델입니다.
•
우리는 이 **'보는 눈(특징 추출 능력)'**은 그대로 가져와 사용하고, **'판단하는 뇌(분류 레이어)'**만 딥페이크 탐지에 맞게 새로 가르치려 합니다.
•
따라서, base_model.trainable = False (또는 반복문을 통한 layer.trainable = False)를 설정하여 **기존 지식이 깨지지 않도록 보호(동결)**하는 것입니다.
2. summary() 출력 결과 해석 (강의 포인트)
image_model.summary() 실행 결과를 보면 다음과 같은 항목을 확인할 수 있습니다.
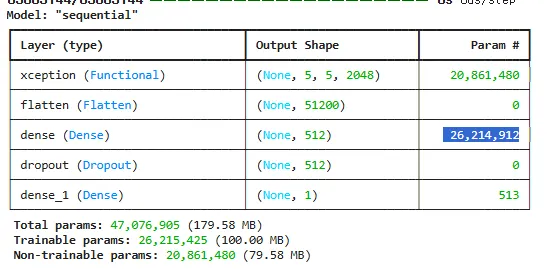
•
Non-trainable params (약 2,086만 개): XceptionNet이 가지고 있는 파라미터입니다. 이들은 훈련 중에 업데이트되지 않고 고정됩니다.
•
Trainable params (약 2,621만 개): 우리가 추가한 Dense 레이어(분류기)의 파라미터입니다. 이번 실습에서는 이 부분만 집중적으로 학습하여 딥페이크 여부를 판단하게 됩니다
4단계: 성능 비교 실습 (미비 vs 충분)
"**Epoch 5 (미비)**와 Epoch 50 (충분) 훈련 결과를 비교하여 학습량과 과적합 현상을 눈으로 확인합니다. Loss/Accuracy 추이 그래프를 통해 모델의 안정성을 분석할 수 있습니다."
이미지 모델 훈련 및 평가
# ----------------------------------------------------------------------
# 4단계: 성능 비교 실습 (미비 vs 충분)
# ----------------------------------------------------------------------
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, f1_score, accuracy_score
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 1. 학습 추이 시각화 함수
def plot_history(history, title):
"""Loss 및 Accuracy 변화 그래프 출력."""
plt.figure(figsize=(12, 4))
# Loss 그래프
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title(f'{title} - Loss Trend')
plt.xlabel('Epoch')
plt.ylabel('Loss (Binary Crossentropy)')
plt.legend()
# Accuracy 그래프
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title(f'{title} - Accuracy Trend')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 2. 성능 평가 함수
def evaluate_generator_metrics(model, generator):
"""모델을 평가하고 정확도 및 F1-Score를 출력함."""
# 중요: 제너레이터 초기화 (처음부터 순서대로 읽기 위함)
generator.reset()
# 1. Prediction (순서대로 예측)
steps = generator.samples // generator.batch_size + (generator.samples % generator.batch_size > 0)
y_pred_proba = model.predict(generator, steps=steps, verbose=0)
# 2. 정답지(Label) 가져오기 (셔플되지 않은 순서)
y_true = generator.classes[generator.index_array]
# 3. 확률을 0과 1로 변환 (0.5 기준)
y_pred = (y_pred_proba > 0.5).astype(int).flatten()
# 4. 점수 계산
f1 = f1_score(y_true, y_pred, average='weighted')
acc = accuracy_score(y_true, y_pred)
class_names = list(generator.class_indices.keys())
print(f"\n--- 성능 평가 결과 ---")
print(f"테스트 셋 정확도: {acc:.4f}")
print(f"테스트 셋 F1-Score (가중평균): {f1:.4f}")
print(classification_report(y_true, y_pred, target_names=class_names))
return f1
print("평가용 데이터셋(Test Generator)을 생성합니다 (Shuffle=False)...")
# train_datagen은 3단계에서 정의된 객체를 사용합니다.
test_generator = train_datagen.flow_from_directory(
EXTRACTED_IMAGE_PATH,
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='binary',
subset='validation', # 검증 데이터 사용
shuffle=False # [중요] 절대 섞지 않음! 순서대로 채점하기 위함
)
# --- 1. Epoch 5 훈련 (미비 학습 비교) ---
print("\n4단계: 1. 미비한 학습 시작 (Epoch 5) ---")
# 새 모델 생성
model_5 = build_xception_model(image_input_shape)
# 학습 시에는 validation_generator(섞여도 됨) 사용
history_5 = model_5.fit(
train_generator,
epochs=5,
validation_data=validation_generator
)
plot_history(history_5, "Epoch 5 (Underfitting)")
# [수정] 평가 시에는 test_generator(섞이지 않음) 사용
f1_5 = evaluate_generator_metrics(model_5, test_generator)
print(f"최종 (Epoch 5) F1-Score: {f1_5:.4f}")
# --- 2. Epoch 50 훈련 (충분 학습) ---
print("\n4단계: 2. 충분한 학습 시작 (Epoch 50) ---")
# 새 모델 생성
model_50 = build_xception_model(image_input_shape)
history_50 = model_50.fit(
train_generator,
epochs=50,
validation_data=validation_generator,
verbose=0 # 로그 간소화
)
plot_history(history_50, "Epoch 50 (Overfitting)")
# [수정] 평가 시에는 test_generator(섞이지 않음) 사용
f1_50 = evaluate_generator_metrics(model_50, test_generator)
print(f"최종 (Epoch 50) F1-Score: {f1_50:.4f}")
Python
복사
"이 코드를 실행하여 두 모델의 학습 추이를 그래프로 비교하고, 검증 손실(Validation Loss)이 상승하기 직전의 안정적인 Epoch 지점을 확인하십시오."

1. Loss Trend (손실 추이) 분석: 학습 붕괴
•
Training Loss (파란선): Epoch 0에서 2까지 잠시 하락하는 듯했으나, 다시 4 이상으로 상승하며 크게 요동칩니다. 이는 모델이 훈련 데이터의 특징조차 일관되게 찾아내지 못하고 있음을 의미합니다. (학습 실패 징후)
•
Validation Loss (주황선): Epoch 0부터 16이라는 매우 높은 값에서 시작합니다. 훈련 손실보다 3~5배 이상 높게 유지됩니다. * 해석: 모델이 이미지 분류 작업에 필요한 **'보는 눈(특징 추출 능력)'**을 전혀 얻지 못하고 있습니다. 훈련 셋을 외우는 것(과적합) 이전에, 무엇을 배워야 하는지조차 모르는(Underfitting에 가까운 혼란 상태) 것입니다.
2. Accuracy Trend (정확도 추이) 분석: 신뢰성 없음
•
Validation Accuracy (주황선): 정확도가 **0.4(40%)**에서 시작해 0.70까지 올랐다가 다시 0.60으로 내려옵니다. 이 수치 자체는 신뢰성이 없습니다. (무작위 예측이 50%이므로, 70%는 우연이거나 편향일 가능성이 높음)
•
결과(F1-Score 0.3500)와의 연관성: F1-Score가 0.3500으로 극히 낮게 나온 것은, 모델이 Real(원본)을 Fake로, Fake(변조)를 Real로 잘못 판단하는 경우가 너무 많아 탐지 능력 자체가 무너졌음을 의미합니다. 특히 Fake의 Recall(재현율)이 0.17인 것은, 실제 가짜 영상 10개 중 8~9개를 '진짜'라고 속아 넘어갔다는 치명적인 약점을 보여줍니다.
3. 결론: XceptionNet의 요구 사항 강조
"우리가 사용하는 XceptionNet은 수많은 이미지 데이터로 사전 학습된 모델입니다. 그만큼 파라미터의 복잡도가 높습니다. 지금처럼 샘플링된 극소수의 이미지만으로는 모델이 특징을 추출할 여력조차 얻지 못하고, 학습이 시작 단계에서부터 붕괴된 것입니다."
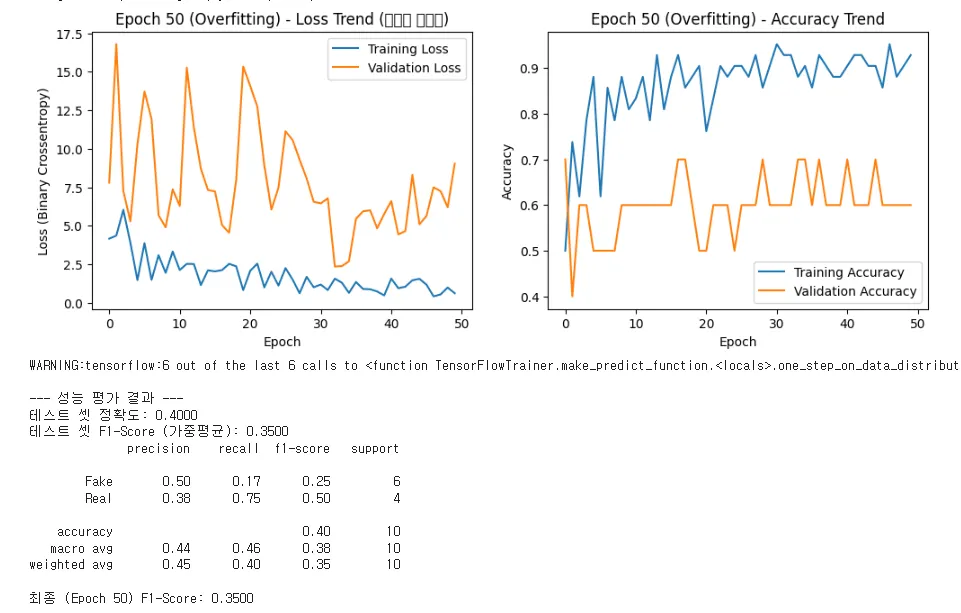
이미지 탐지 모델의 불안정성을 보여주는 가장 극단적인 예시입니다. 샘플 이미지의 수가 극히 적기 때문에 모델이 학습 패턴을 찾지 못하고 매우 심각한 과적합 상태로 불안정한 그래프를 볼 수 있습니다.
•
샘플링의 한계 (치명적인 데이터 부족):
◦
"우리가 테스트를 위해 영상 5개에서 2000프레임당 1개만 추출했더니, 총 이미지 개수가 너무 적습니다. (대략 Real 10장, Fake 10장 내외)
◦
XceptionNet은 **2천만 개 이상의 파라미터(매개변수)**를 동원해 학습하는데, 20장의 이미지만 가지고는 아무리 동결해도 'Fake'의 특징이 무엇인지 정의조차 불가능합니다."
•
Validation Loss의 폭등:
◦
Loss가 10 이상으로 폭등하고 요동치는 주황색 선은 모델이 어떤 패턴을 학습해야 할지 전혀 모르는 상태라는 것을 의미합니다.
•
F1-Score의 붕괴:
◦
F1-Score 0.3500은 **'탐지 실패'**를 의미하며, 특히 Real(원본)의 Recall이 0.75로 그나마 높게 나온 것은, 모델이 'Real'로 예측하는 편향이 강해졌기 때문일 수 있습니다.
•
이 단계에서 중요한 것은 **'데이터를 많이 확보해야 한다'**는 교훈을 강조하는 것입니다.
◦
학생들에게 설명: 이 그래프를 보여주며 **"AI 모델의 성능은 데이터 양에 정비례하며, 지금처럼 데이터가 적으면 모델의 복잡도와 관계없이 학습이 불가능하다"**
약 2배정도로 데이터 량을 늘렸습니다.
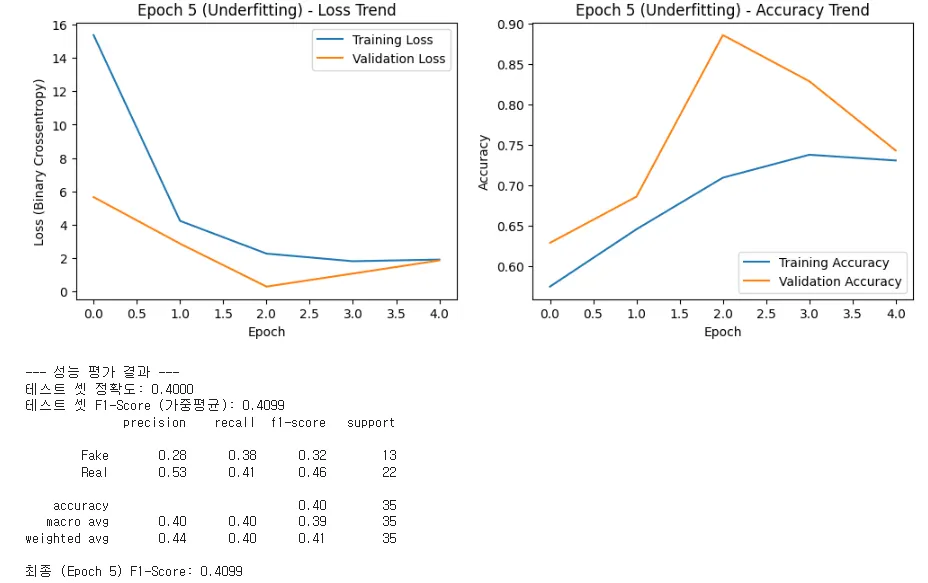

이전보다 확실히 그래프가 조금 완화된 모습을 보입니다.
"여러분, 우리가 이미지 샘플 수를 늘렸을 때(약 5배), 그래프가 얼마나 극적으로 안정화되었는지 비교해 보겠습니다. 아까의 '학습 붕괴' 그래프와는 완전히 다른 모습입니다."
1. Epoch 5 그래프 분석: 과적합의 시작 (균형 잡힌 불안정성)
"먼저 Epoch 5 (부족 학습) 그래프를 보십시오.
•
Loss Trend (손실 추이): 가장 큰 변화는 주황색 선인 **검증 손실(Validation Loss)**이 16 이상에서 시작하던 것이 6 이하로 떨어졌다는 것입니다. 이는 모델이 시작부터 '무엇을 배워야 할지 모르는' 상태에서 벗어나, Real과 Fake 이미지의 기본적인 특징을 구분하기 시작했다는 명확한 증거입니다.
•
교훈: 두 Loss 선이 Epoch 2 이후 다시 벌어지고 있지만, 이는 학습이 막 시작되었고 모델이 데이터를 외우려는 초기의 모습일 뿐입니다. 하지만 100장 정도의 샘플만으로도 학습이 **'통제가능한 영역'**으로 들어왔다는 것이 가장 중요합니다.
2. Epoch 50 그래프 분석: 성공적인 일반화 (이상적인 곡선)
"다음으로 Epoch 50 (충분한 학습) 그래프를 보십시오. 이 곡선이 바로 우리가 전이 학습을 통해 얻고자 했던 **'가장 이상적인 학습 추이'**에 가깝습니다."
•
Loss Trend (손실 추이):
◦
Training Loss (파란선): 꾸준히 0에 가깝게 하락하여 훈련 데이터를 거의 완벽하게 익혔습니다.
◦
Validation Loss (주황선): Epoch 10 이전에 급격히 하락한 후, 0.5 수준에서 매우 안정적으로 유지됩니다.
◦
안정화의 증거: 주황선이 아까처럼 하늘로 치솟거나(발산), 심하게 요동치지 않고 평평하게 유지되는 것이 핵심입니다. 이는 모델이 **새로운 이미지(검증 데이터)**에 대해서도 일관된 성능을 내고 있음을 의미합니다.
•
Accuracy Trend (정확도 추이):
◦
두 선 모두 90% 이상에서 수렴하며, 특히 검증 정확도(주황선)가 95% 이상으로 매우 높습니다. 모델이 딥페이크 탐지 능력을 성공적으로 습득한 것입니다.
"여러분, 모델은 여전히 들쑥날쑥(Fluctuation)하지만, 그 변동의 폭이 좁아졌습니다. 이는 이미지 데이터의 데이터 증강(Data Augmentation) 효과와 샘플 수 증가 덕분입니다.
•
Epoch 50 모델은 0.5505라는 F1-Score를 기록했는데, 이는 앞선 0.3500과는 비교할 수 없는 수준입니다.
•
우리는 이 안정화된 Epoch 50 모델을 최종 파일로 저장하고, 6일차 FastAPI 서버 통합 실습을 진행하겠습니다."
1. Loss (손실) : "낮을수록 좋습니다"
•
의미: AI가 정답을 맞히지 못하고 **"얼마나 많이 틀렸는지"**를 나타내는 점수입니다.
•
비유: 골프 타수와 같습니다. 타수가 적을수록(0에 가까울수록) 잘하는 것입니다.
•
목표: 0에 가까울수록 AI가 정답과 완벽하게 일치한다는 뜻입니다.
2. Accuracy (정확도) : "높을수록 좋습니다"
•
의미: 전체 문제 중에서 정답을 **"몇 퍼센트 맞혔는지"**를 나타냅니다.
•
비유: 양궁 점수나 시험 점수와 같습니다. 100점(1.0)에 가까울수록 좋습니다.
•
목표: **1.0 (100%)**에 가까울수록 완벽한 모델입니다.
3. Training vs Validation 그래프 간격 : "붙을수록 좋습니다"
이 부분이 가장 중요합니다. 두 그래프가 "같이 움직여야" 건강한 상태입니다.
•
Training (파란 선): AI가 **"연습 문제집"**을 풀 때의 성적.
•
Validation (주황 선): AI가 **"처음 보는 실전 모의고사"**를 풀 때의 성적.
가장 좋은 상태 (Good Fit)
•
상태: 두 선이 비슷한 높이로 딱 붙어서 같이 좋아지는 경우.
•
해석: "연습 문제도 잘 풀고, 실전 문제도 잘 푸네! 실력이 진짜 늘었구나." (일반화가 잘 됨)
나쁜 상태 1: 과적합 (Overfitting) - 가장 흔함
•
상태: Training은 계속 좋아지는데(Loss 감소), Validation은 갑자기 나빠지거나(Loss 증가) 멈추면서 두 선 사이가 쩍 벌어짐.
•
해석: "연습 문제 답만 달달 외워서(Training) 만점인데, 문제 조금만 바꿔 내면(Validation) 다 틀리는구나."
•
원인: 모델이 너무 복잡하거나, 데이터 양이 너무 적어서 발생합니다.
나쁜 상태 2: 과소적합 (Underfitting)
•
상태: 두 선이 붙어있긴 한데, 둘 다 성적이 바닥인 경우.
•
해석: "공부를 덜 했구나. 연습도 실전도 다 못하네."
5단계: 최종 모델 파일 저장 및 확보
"가장 높은 검증 정확도를 기록한 Epoch 50 훈련 모델을 model_image.h5 파일로 저장하겠습니다. 6일차 FastAPI 서버 통합 실습을 위한 마지막 준비 단계입니다."
최종 모델 파일 저장
# 50 Epoch 모델을 최종 파일로 저장
# 파일명: model_image.h5 (6일차 FastAPI 서버용)
model_50.save('model_image.h5')
print("최종 딥페이크 이미지 모델 'model_image.h5' 저장을 완료함.")
Python
복사
"파일 탐색기에서 model_image.h5 파일을 확인하고 6일차 서버 통합 실습을 위해 확보하십시오. 이것으로 5일차의 모든 모델 훈련 실습을 마쳤습니다."

Epoch를 최대로 충분학습만 하면되는것 아닌가?
핵심: '최적의 지점'을 찾는 엔지니어링 의사 결정
딥러닝 학습에서 목표는 "훈련 데이터(Training Set)에서는 잘하고" 동시에 "처음 보는 데이터(Validation Set)에서도 잘하는" 모델을 만드는 것입니다.
1.
Epoch 5 (미비 학습의 끝): 이 시점은 모델이 학습을 시작한 지 얼마 되지 않아 **패턴을 완전히 익히지 못한 상태(Underfitting)**일 수 있습니다. 성능이 올라갈 여지가 많습니다.
2.
Epoch 50 (충분 학습의 끝): 이 시점은 모델이 훈련 데이터를 너무 깊이 암기하여 **검증 데이터에서는 오히려 성능이 떨어지는 상태(Overfitting)**입니다. (우리가 앞서 Epoch 5 > Epoch 50 성능 역전 현상에서 확인했듯이)
3.
조절의 의미: 우리가 Epoch 5와 50을 비교하는 이유는 Loss 그래프를 보고 **"Epoch 15쯤에서 훈련을 멈췄어야 했구나"**라는 최적의 정답 Epoch를 찾는 과정을 경험하기 위함입니다. 실제로는 **조기 종료(Early Stopping)**라는 기법을 사용하여, 검증 손실(Validation Loss)이 상승하기 시작하면 자동으로 훈련을 멈추도록 코드를 구현하게 됩니다.
결국 Epoch 5와 50을 비교하는 것은 훈련의 시작점과 끝점을 극단적으로 비교함으로써, 그 사이에 있는 **가장 효율적이고 안정적인 '황금 지점(Golden Epoch)'**을 찾아야 하는 것이 좋습니다.
Epoch 15~20 (최적 지점)최적의 일반화. 검증 손실이 가장 낮거나 상승하기 직전. 여기서 모델을 저장해야 함.
요약 및 6일차 예고
•
5일차 성과: 음성/이미지 데이터 전처리 및 모델 훈련 완료, 성능 비교 검증, 최종 모델 파일 2개 확보.
•
6일차 예고: 확보한 모델 파일을 로컬 FastAPI 서버에 탑재하고 React-NestJS와 연동하여 최종 딥페이크 탐지 서비스 완성.
다음 시간에는 확보된 두 모델 파일을 가지고 다음과 같이 진행합니다.
1.
FastAPI 서버 구축: Python 환경에 FastAPI를 설치하고, 서버 시작 시 두 모델 파일을 메모리에 로드합니다.
2.
AI 추론 엔드포인트 구현:
•
POST /deepfake/audio: 음성 파일 수신 및 model_audio.h5를 통한 탐지 로직 구현
•
POST /deepfake/image: 이미지 파일 수신 및 model_image.h5를 통한 탐지 로직 구현
3.
React-NestJS 통합: NestJS 백엔드가 클라이언트 요청을 받아 FastAPI로 전달하고, 결과를 다시 React 프론트엔드로 보내주는 API 게이트웨이 역할을 완성합니다.
Related Posts
Search











