
Gallery
Search

프로젝트 후기
백엔드 챌린지에 대한 회고
백엔드 입장에서 프론트엔드에 대한 회고
기타 느낀점

[Spring][258] 프로젝트 완료 후기 회고, 배운점과 아쉬운점
Elasticsearch는 또한 내부적으로 왜 안정적이며, 어떤 알고리즘, 자료구조 등등이기 때문에 빠른것이 보장되는지에 대한 이해도 추가 필요
Elasticsearch가 내부적으로 안정적이며 빠른 이유는 여러 가지가 있습니다.
1.
먼저, Elasticsearch는 Apache Lucene을 기반으로 만들어졌습니다. Lucene은 검색 엔진에 사용되는 강력한 오픈 소스 라이브러리로, 텍스트 인덱싱과 검색에 특화돼 있습니다.
2.
Elasticsearch는 대량의 데이터를 효율적으로 처리하기 위해 여러 가지 알고리즘과 자료구조를 사용합니다. 그 중 하나는 역색인화라는 개념입니다. 역색인화는는 단어가 어느 문서에 나타나는지를 기록해 두어 검색 속도를 향상시키는 데 도움이 됩니다.
3.
Elasticsearch는 분산 시스템으로 설계돼 있어서 여러 노드에 데이터를 분산 저장하고 병렬 처리를 가능하게 합니다. 이렇게 함으로써 데이터 검색 및 분석 작업을 효율적으로 처리할 수 있습니다.
4.
Elasticsearch는 실시간 검색을 지원하고 있어서 데이터가 업데이트되더라도 거의 실시간으로 검색 결과를 반영할 수 있습니다. 이는 대규모의 데이터셋에서도 높은 성능을 제공하는 데 기여하고 있습니다.
엘라스틱 서치의 검색이 빠른 이유?
Elasticsearch는 Lucene 인덱스 를 기반으로 한 검색 엔진입니다.

Lucene은 Apache 소프트웨어 재단에서 개발한 텍스트 검색 라이브러리로, 역색인화를 포함한 다양한 검색 기능을 제공합니다.
엘라스틱 서치는 Lucene을 기반으로 만들어졌기 때문에 Lucene의 강력한 역색인화 기능을 활용하여 대용량의 데이터를 효율적으로 검색할 수 있습니다.
결국, 엘라스틱 서치는 사용자에게 더 편리하고 확장 가능한 인터페이스를 제공하면서 Lucene의 강력한 검색 엔진을 내부적으로 활용하고 있어.
Lucene 의 특징?
Lucene은 텍스트를 단어 또는 토큰 단위로 분석하여 색인화합니다.

[Spring][258] Elasticsearch의 Lucene 인덱싱
질문이 나올만한 부분은 본격적으로 아키텍처 기술도입배경부터 시작된다.
전체적인 요청의 흐름?
전체적으로 클라이언트의 HTTP 요청이 어떻게 처리되는지 알려주세요.
•
기본 흐름
◦
클라이언트→AJAX요청→로드밸런서→시큐리티필터체인→디스패처서블릿→(컨트롤러→서비스→리포지토리)→데이터베이스
▪
로드밸런서에서는 HTTP는 HTTPS로 리디렉션함
•
ROUTE53
•
ACM에서 SSL 인증서
그 흐름에서 카프카는 어떤 역할을 하나요?
•
기본적으로 저희는 메인서버와, 이벤트만을 위한 독립적인 서버가 별도로 존재합니다.
•
서버가 나뉘어졌고 그 중개 역할로 카프카가 데이터를 전달하는 역할입니다.(메시지큐)
아래는 연결되는 질문또는 답변입니다.
두개를 나눈이유?
메인서버에서 부하가 많이 생겼을때, 서버를 확장해야 할때 기존의 모놀로식 구조에서는 모든 서비스가 확장되어야하지만,
이 구조를 통해서 이벤트 서버만 독립적으로 확장 할 수 있습니다.
그 흐름에서 레디스는 어떤 역할을 하나요?
레디스는 레디스 분산락을 위해서 구성되어있습니다.
선택한 이유는 분산 DB의 확장을 위해서 선택했습니다.
왜 인메모리 데이터베이스가 필요했는지?
주키퍼와 비교했는데, 저희는 실시간 처리가 필요했기 때문에 인메모리방식인 레디스가 가장 적합했습니다.
동시성 제어가 필요한 이유는 무엇인가요?
트랜잭션, 갱신실패, 데드락
검색 성능을 개선 시킬수 있는 다른방안? 알고리즘과 자료구조랑 관련있는것?
한번 해본것 , 안해본것
[Spring][258] 예상 질의 응답 목록 - 프로젝트에 대하여 발표흐름에 따른 분류
예상 질의 응답 목록 - 프로젝트에 대하여 발표흐름에 따른 분류JPQL 쿼리로 직접 검색 방식 정하기
아래 쿼리를 @Query 어노테이션을 통해서 작성하여 검색의 방식을 변경 할 수 있다. 기존 직접 내부 로직을 구성하는 방식과 다르게, 마치 JPQL을 사용하는것 처럼 쿼리문을 작성 할 수 있다. 그럼 마찬가지로 쿼리문이 컴파일 단계에서 검사되지 않는 단점이 있을 것으로 보여진다.
QueryDSL로 구현해보기
build.gradle 의존성 추가
QueryDSL 플러그인 및 태스크 설정
ElasticBookRepository를 상속받은 ElasticBookSearchRepositoryImpl.java 구현체에서 다음처럼 구현한다. Q객체를 통해서 쿼리팩토리를 통해 쿼리를 메소드형태로 작성하게 된다. 이러면 컴파일 단계에서 개발자의 오류를 찾을 수 있다.
아래는 JPQL로 직접 쿼리를 보낼 때의 각 검색 API이다.
1. 검색API Template
2. 검색 파라메터

[Spring][258] Elasticsearch APIs
[2:22] ELB 설명하실 때 https를 언급하셨는데, 발표자료에도 그 내용이 반영되어 있으면 좋을 것 같습니다. 그리고 main server와 event server의 spring architecture를 모두 보여줄 필요는 없고, application server로 정의한 뒤에 해당 server의 스펙을 하나만 보여주고 main server와 event server가 application server 구조로 되어있다고 보여주면 더 깔끔할 것 같습니다.
발표자료 수정
대본 수정
영상 멘트 수정
[2:58] mysql DB로 부터 도서 데이터가 동기화된다는 표현보다는, logstash가 전처리한 도서 데이터가 elasticsearch에 저장되고, 이 데이터가 mysql에 동기화되고 있다라고 표현하는게 맞을 것 같습니다.
발표자료 수정 없음
대본 수정
영상 멘트 수정
[3:15] ELK stack에 대한 이야기는 이미 앞에서 같이 구축되어 있다는 내용으로도 충분하므로 굳이 안하셔도 됩니다. 오히려 스택을 구성하는 각 요소(elasticsearch, logstash, kibana)에 대해 간단하게 설명해주시는게 더 좋을 것 같습니다.
발표자료 수정 없음
대본 수정 ELK설명은 10초는되니까 우선 전체 수정하고 남는시간보고 파악
ELK설명은 10초는되니까 우선 전체 수정하고 남는시간보고 파악 ELK Stack은 데이터를 색인화하고 저장하는 ElasticSearch와, 데이터를 수집하고 가공하는 Logstash, 마지막으로 이 데이터를 분석하고 시각화하는 Kibana로 구성됩니다.
영상 멘트 수정
[Spring][258] 발표 피드백 수정[완료]
Spring Boot
Spring Security
JWT
Swagger
Spring Data JPA
Querydsl
GitHub Actions
Elasticsearch
MySQL
Kafka
Redis
AWS 인프라
[Spring][258] 예상 질의 응답 목록 - 기술스택과 관련된 것들
예상 질의 응답 목록 - 기술스택과 관련된 것들1. 검색 기능 업그레이드

•
기존 페이징 버전(v3)
•
슬라이스 방식의 버전(v4)
•
무한 스크롤 기능(is1)
[Spring][258] 프로젝트 마무리 작업
인용
•
간단소개영상과 발표자료 발표영상 최종본제출
◦
편집수정
◦
대본체크
◦
전반흐름이해를 위해 각자에게 질문을 자주할수있습니다.
◦
제출이 가장 중요하니 처리 후 질답부분에 투입할것입니다.
•
주말작업
◦
간단소개 전체 콘티를따라 녹화전 상태 모두 작업완료되었습니다
◦
피티 전체 테마가 변경되었습니다. 간단소개영상용 피티기준으로 기존피티가 발표용으로 이식될 예정입니다.
◦
월요일 발표 피드백이 도착하면 추가적인 개인부분들에 대한 질문 또는 사소한 변경 등 요청이있을수있습니다.
강용영익유헌
•
질의응답 의견결정 관련내용 모두정리
◦
질문이나 꼬리질문이 나올만한 것들에 대해서 사전처럼 꼼꼼히 정리해야합니다
▪
긴 말보다는 간결하게 핵심만 한두문장으로 ‘실제 본인이 대답한다’ 라는 생각을 하고 읽어보면서 작성해둡니다.
◦
브로셔 기술선택근거 부분 참고
◦
꼬리질문
◦
프로젝트에 대해 스스로 보고 질문이 무엇이 나올지 생각해보기
•
API 명세서 표 정리, 스웨거는 결과인 것이므로 표와는 다르다. 이것은 미루었던 일일뿐.
◦
스웨거로 대체했던건 우선순위에서 미뤘던것이지
◦
실제론 api명세서가 있어야합니다. 저희는 프로젝트 주제변경후 빠르게 구현하느라 이부분을 추가수정하는것이 미뤄졌습니다.
◦
본인부분만 처리하지말고 모든부분을 체크해주세요.
◦
456주차 스크럼, 멘토링 등 문서화부분 재확인필요,
▪
막바지에 발표준비에 제가작성을 마무리하지못한 부분이 있을것입니다
▪
특히 멘토링 진행시 우리는 사전노트에 정리한경우가많아서 저희 블로그의 멘토링 태그의 멘토링내용정리 부분을 옮겨주세요
▪
해당 부분들 확인하고 전체적인 SA 미흡부분 체크, 보완 필요합니다
▪
문서화 혼자하기 시간이부족합니다 도와주세요
유헌(주말작업 팀장 확인완료)
프론트엔드 부분 추가 수정 필요사항
•
프론트엔드 메인페이지를 로그인 페이지로 시작하고 로그인 이후 도서 검색 페이지를 기본으로 이동하도록 구성
•
프론트엔드 검색부분을 드롭다운으로 단계적 구성 필요한가? 아니면 최종본만 연결할까
◦
Search
▪
기존페이징 v3
▪
슬라이스 v4
▪
무한스크롤 is1
▪
엘라스틱 el1
•
프론트엔드 네비게이션의 변화필요
◦
로그인 상태에 대한 표현
▪
비로그인 상태
•
로그인 메뉴가 보여야함
•
로그아웃이 안보여야함
▪
로그인 상태
•
로그인 메뉴가 안보여야함
•
로그아웃 메뉴가 보여야함
◦
로그인 유저의 롤에 따라 보이는 메뉴가 달라야 한다
▪
유저인 경우(관리자메뉴빼고)
•
도서검색가능
•
도서나눔신청
•
마이페이지
▪
관리자인경우
•
관리자메뉴들
[Spring][258] [중요공지] 프로젝트 마무리단계 현재 필요한 작업 업무분담입니다.[완료]
Q. 검색 성능이 점진적으로 개선되지 않고 한번에 올랐습니다.
A. 점진적으로 개선되거나 그런 테스트 결과를 원했겠지만, 그렇지 않을 수도 있습니다. 실제로 그렇기도합니다. 오히려 성능이 나쁠때도 있습니다. 하지만 중요한건 그 테스트 자료들의 그렇다고해서 필요 없는것이 아닙니다. 오히려 그런 모습을 연출하려고 조작되면안되고 그대로 나타나는것이 맞습니다. 그래서 지금 결과가 맞는것입니다.
Q. 향후 프로젝트에서 어떤 부분을 중점으로 진행하면 좋을 까요?
A. FTI와 Elasticsearch를 도입한 부분에서 풀텍스트인덱스의 편차가 발생했던 부분을 더 깊게 파보았으면 좋았을것 같습니다. 물론 프로젝트 끝나고도 계속해서 찾아볼 필요가 있습니다.
MySQL의 풀텍인덱스에 대해서 알고리즘이나 자료구조까지 확장해보고 더해서 디폴트 엔진인 InnoDB에 대해서까지 그 차이를 발생시키는것이 무엇인지 알아보기까지..
그 편차의 원인, 무엇이 그렇게 만들었는지 찾아가는 과정을 계속해서 공부해보시는게 도움 될 수 있습니다. 그게 그 부분에 대해서 다른 어느 개발자보다 잘 아는, 왜 이런 현상이 나타나는지 아는 개발자가 되는 깊은 공부 방법입니다.
특히 이런 깊은 공부를 할때는 공식문서를 참고하는것이 가장 좋습니다. 가장 명확한 근거이기 때문입니다.
멘토님의 충고
공통적으로 기술 스택들에 대해서 근거를 잘 정리해오고 있지만 또한 계속해서 보다 더 정리하는 것이 중요합니다. 그 이유는 이는 곧 기술을 선택 또는 판단하는 능력이고, 그 기술을 선택한 것이 맞다는 근거를 만드는 능력. 이게 실무에서 실제로 이루어지기 때문입니다.
프로젝트 끝에 안주하면 안됩니다. 개발공부 시작입니다.
마무리 될 수 있는 부분은 마무리해야겠지만, 앞으로 더해야할것이 많고,
스트레스 관리와 번아웃을 조절해야 합니다.
[Spring][258] [5주차 멘토링] 질문내용 정리와 답변 + 조언
기획
이 영상은 발표영상이아니다. 소개영상이라 생각해야한다.

발표영상보다 까다롭다. 연출이 필요하다.
제한 시간 2분
초 간단한 영상을 연출해야한다.
핵심적인 내용 딱 2개를 설명해내야 한다.
서비스를 보여주면서 핵심기술을 표현해야한다.
[Spring][258] 간단소개 영상 구상[완료]
발표자료의 구성
첫화면
목차
기획배경
목표
시연영상
아키텍처설명 + 기술도입배경
트러블슈팅
성능개선사항
종료화면
발표자료와 영상의 활용
영상은 피티 흐름에 적절한 내용들을 간결하고 충분하게 설명되도록 구성
씽크는 기본
피티 디자인 콘티
프리미어를 활용한 편집
엔지를 최소화해야한다 시간적 세이브가 필요하다
[Spring][258] 발표 영상&PPT 구성[완료]
프로젝트 기획 배경 설명 (30초)
•
해당 프로젝트를 어떠한 배경과 당위성으로 기획하게 되었는지 설명해주세요.
•
“현실에서 어떠한 문제를 발견하여 어떤 기술을 활용하면 이 문제를 해결할 수 있을 것 같았다.”
시연 영상 재생 (1분)
•
서비스의 핵심이 되는 기능만 시연해 주세요. 즉, 회원가입, 로그인 과정 등은 생략해도 됩니다.
•
서비스 시연에는 변수가 많습니다. 가능한 녹화 영상을 활용하여 발표를 진행해주세요.
아키텍처 설명 및 기술 도입 배경 (2분)
•
서비스가 어떤 구조를 갖고 있는지, 주요 기능을 구현하기 위해 어떤 기술을 썼는지 설명하는 시간입니다.
•
아키텍쳐 및 도입한 기술을 설명하실 때는 반드시 의사결정 과정을 설명해 주세요.
스프링부트- MySQL 데이터베이스를 기반으로 하고있습니다. DB는 AWS RDS 환경으로 구축되어 있습니다.
추가적으로 카프카 레디스는 동시성 제어를 위하여 있습니다.
엘라스틱서치는 검색 엔진 기능 역할을 위해 별도 EC2 서버에 Logstash와 KIbana와 함께 구축되어 있습니다. MySQL로부터 도서 데이터를 동기화 하고 있습니다.
[Spring][258] 발표 대본 흐름 구상[완료]
초안
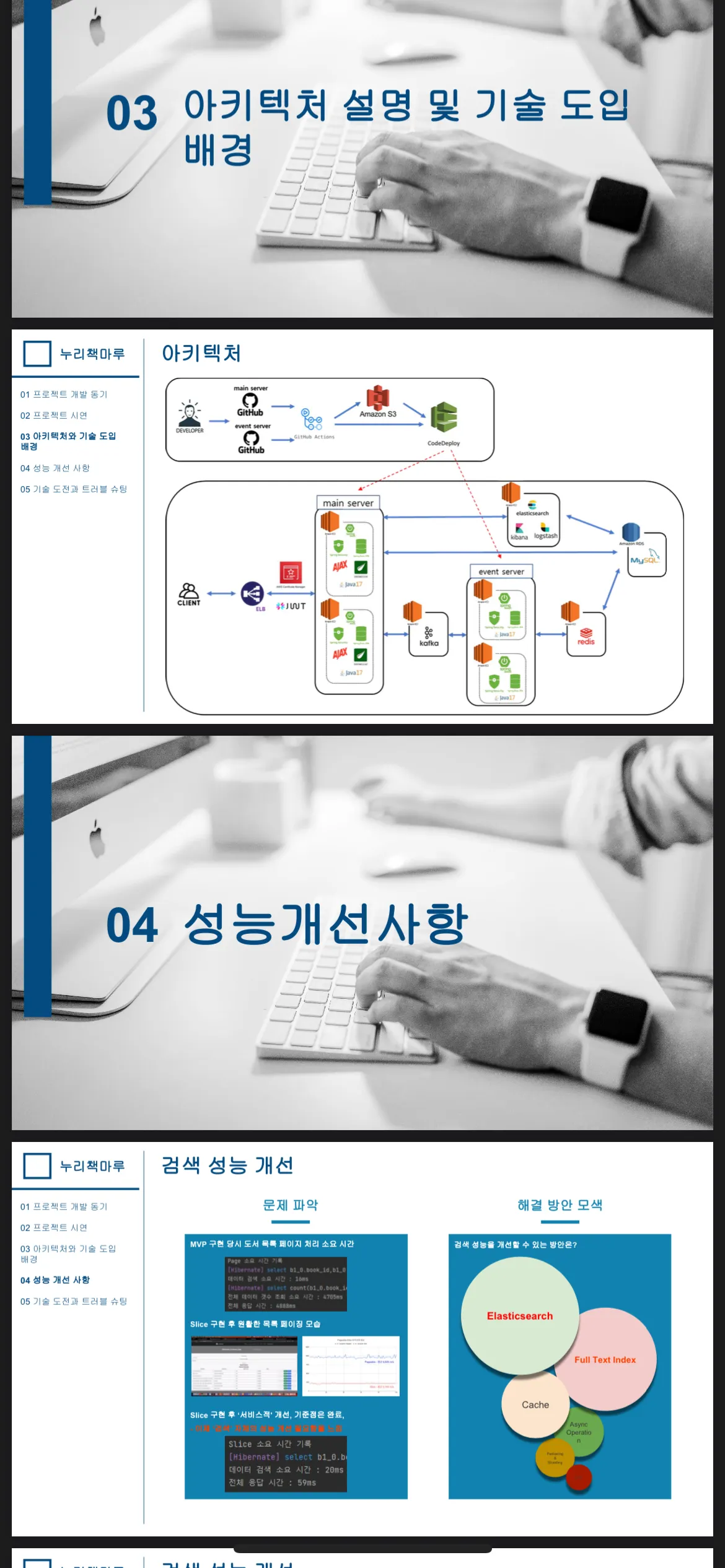
저희 프로젝트의 CI/CD와 소프트웨어 아키텍처를 설명드리겠습니다.
저희조는 CI/CD를 Github Action과 AWS의 S3, Codedeploy를 이용해서 구현하였습니다.
저희 GitHub에서 main 브랜치로 pull request를 보내면 GitHub Action을 이용해서 AWS의 S3와 Codedeploy를 통해 AWS EC2 서버로 배포되는 구조입니다.
그럼 이제 저희가 왜 GIthub Action으로 CI/CD를 구성하였는지 말씀드리겠습니다.
저희는 초기 Jenkins와 GitHub Action 사이에서 고민을 하였습니다.
Jenkins는 별도의 서버를 준비하고 유지보수해야 하는 비용과 노력이 필요하며, AWS CI/CD에 특화된 도구들과의 통합을 위해 추가적인 플러그인이나 설정이 요구됩니다.
Jenkins가 강력한 커스터마이징을 제공하지만, GitHub Actions는 AWS와의 통합 및 관리 측면에서 더 간편하고 효율적인 솔루션을 제공합니다.
또한 GitHub Action을 사용하면 GitHub 리포지토리와의 긴밀한 통합으로 이벤트 기반 워크플로를 쉽게 설정할 수 있고 코드 소스와 CI/CD 파이프라인이 동일한 장소에서 관리되므로 개발자는 별도의 CI 도구로 전환할 필요 없이 편리하게 작업할 수 있기에 선택하였습니다.
그럼 이제 저희 소프트웨어 아키텍처에 대하여 설명하겠습니다.
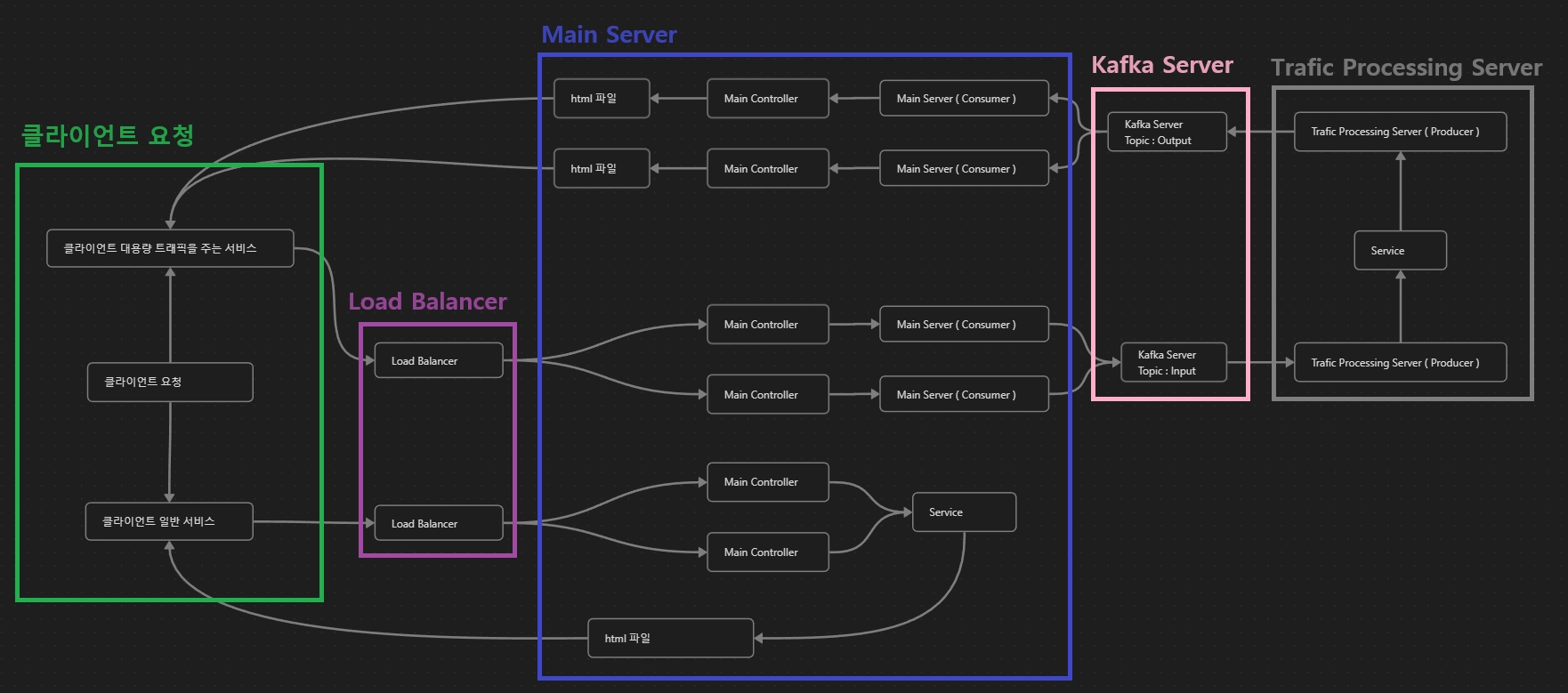
클라이언트가 요청을 할시 우선 ELB ( ALB )에서 클라이언트가 https 프로토콜을 사용 하는지 살펴보고 http면 https 통신을 하도록 상태코드 301을 통해 리디렉션을 합니다. 클라이언트가 HTTPS 프로토콜을 사용하면 Main Server로 전달해 줍니다. 여기서 클라이언트가 여럿이면 요청을 나누어서 한 서버에서 모든 요청을 처리하지 않게 분배해줍니다. 그 후 Main 서버에서는 클라이언트가 요청한 서비스가 마이크로서비스 아키텍처 구조를 적용한 책 나눔 서비스인지 여부를 파악합니다. 책나눔 서비스는 짧은 시간 대규모의 트래픽이 예상되는 서비스이기에 마이크로서비스 아키텍처 구조를 적용하였습니다. 만약 책나눔 서비스가 아니라면 메인서버에서 자체적으로 처리합니다. 그리고 책나눔 서비스인 경우에는 프로듀서를 통해 카프카로 클라이언트의 요청 데이터를 보내고 이벤트 서버에서는 컨슈머로 요청 데이터를 받은 이후 레디스의 분산락을 통해 동시성 제어를 하며 비즈니스 로직을 처리한 결과를 다시 프로듀서를 통해 카프카 서버로 보냅니다. 메인서비스에서는 컨슈머를 통해 보낸 요청에 해당하는 이벤트 서버의 결과를 비동기적으로 처리하여 클라이언트에게 전달해줍니다.
1차 수정 및 정리
프로젝트의 CI/CD 및 소프트웨어 아키텍처에 대해 안내해 드리겠습니다.
저희 팀은 Github Action, AWS의 S3, 그리고 Codedeploy를 활용하여 CI/CD를 구성했습니다.
이를 통해, Github의 main 브랜치로 pull request가 이루어지면 자동으로 AWS EC2 서버로 코드가 배포되는 시스템을 갖추었습니다.
CI/CD 시스템 선택에 있어, 저희는 Jenkins와 GitHub Action 중 고민 끝에 후자를 선택했습니다. Jenkins는 강력한 맞춤 설정이 가능하지만 별도의 서버 유지 및 AWS와의 통합을 위한 추가 작업이 필요한 반면, GitHub Action은 AWS와의 통합이 용이하고 관리가 더 간단하여 개발자가 더 쉽게 작업할 수 있는 장점이 있습니다.
다음으로 저희 소프트웨어 아키텍처를 설명하겠습니다.
클라이언트의 요청이 들어오면 ELB(ALB)가 이를 받아서 HTTP 프로토콜을 사용하는지 확인하고, 필요한 경우 HTTPS로 리디렉션합니다.
안전한 HTTPS 프로토콜을 사용할 경우 요청은 메인 서버로 전달되며, 이 서버는 요청을 적절히 분산하여 처리합니다.
특히 대규모 트래픽을 처리해야 하는 책 나눔 서비스 같은 경우, 마이크로서비스 아키텍처를 적용하여 요청을 처리합니다. 이는 카프카를 통해 이벤트 기반으로 데이터를 처리하고, 레디스의 분산 락을 활용해 동시성을 제어함으로써 효율적인 서비스를 제공합니다.
마지막으로, 메인 서비스는 이벤트 서버의 결과를 비동기적으로 받아 클라이언트에게 전달합니다.
[Spring][258] CI/CD 및 소프트 웨어 아키텍처 동작 흐름 정리
작업 진행 전

작업 결과

[Spring][258] 프론트 디자인 작업 _ 책나눔 이벤트 페이지
EC2 Kibana의 외부 접속 환경 설정
Kibana는 Elasticsearch의 데이터를 관제하고 각종 분석도구를 제공합니다. 시각화를 담당하는 HTML + Javascript 엔진이라 볼 수 있습니다.
하지만 EC2에서 구축한 경우 해당 서비스에 접속하기 위해서는 외부 사용자 또는 관리자가 EC2서버의 5601포트에 접근 할 수 있어야 하는데 대부분의 DB는 기본적으로 Localhost를 통한 접근만을 허용하고 있습니다. 따라서 외부 접속에 대한 커넥션을 열어주어야 합니다.
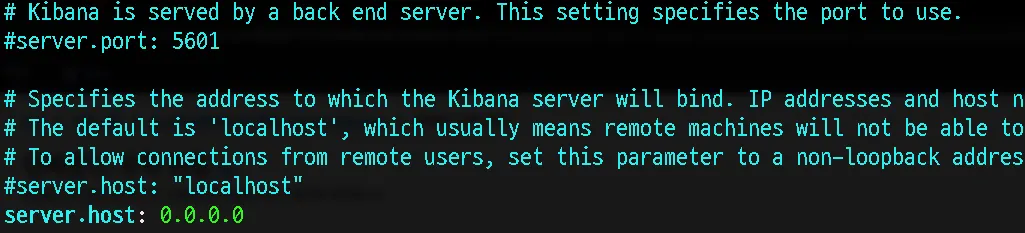
Kibana의 설정 파일은 EC2의 다음과 같은 경로에 위치합니다. vi에디터를 통해 CLI환경에서 파일을 수정합니다.
server.host 부분이 기본적으로 localhost로 되어있으며, 이것 조차 주석처리되어 default가 localhost임을 알려주고 있습니다. 해당 부분에 외부 접근을 허용 할 수 있도록 0.0.0.0을 입력해줍니다.
Kibana의 기본 포트는 5601포트입니다.
:wq 를 통해 저장하고 서버를 재시작해줍니다.
EC2의 인바운드 규칙 설정
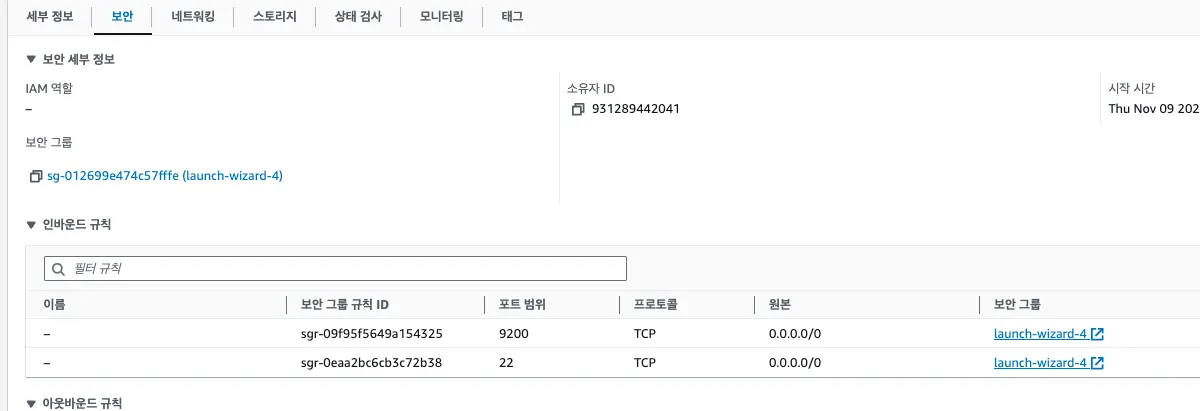
외부 접근은 허용했지만 EC2 컴퓨터 자체의 포트 접근을 허용해야 합니다. 이는 AWS EC2의 인바운드 규칙 부분에서 대상 포트를 추가하여 접근 권한을 열 수 있습니다.
현재는 기본 설정인 22 SSH-SFPT 포트와 이전 Elasticsearch의 환경 구축을 통해 추가된 9200 Elasticsearch의 포트만 설정되어 있는것을 볼 수 있습니다.
[Spring][258] AWS EC2 Elastic Stack의 Kibana 외부 접속 환경 설정
1차 Code 정리 [ resource ( JS, CSS, Templates ) ]
•
자원 파일(자바스크립트, CSS, 템플릿)을 체계화합니다.
2차 정리 [ Security Filter 및 domain 일부 불필요 컨트롤러 ]
•
보안 필터 제거 및 도메인에서 불필요한 컨트롤러를 제거합니다.
[Spring][258] EventApply 서버 코드 리팩토링 및 불필요 브랜치 제거 작업
AWS EC2의 Ubuntu환경에서 Elasticsearch를 설치를 완료한 상태에서는 EC2입장에서의 localhost:9200으로만 Elasticsearch에 접근 할 수 있습니다. 본래 EC2 자체를 생성하고 Elastic stack을 설치한 이유는 해당 인스턴스 자체를 Elasticsearch 전용 서버로 사용하기 위함이기 때문에 스프링부트 프로젝트가 실행되는 EC2와 RDS로 구축된 MySQL에서 해당 서버에 외부접속을 통해서 접근 할 수 있어야 합니다.
Elasticsearch 서비스 시작 및 포트확인
우선 Elasticsearch는 기본적으로 9200포트를 사용하며, 기본 설정에서 현재 로컬 서버(EC2)에서만 통신이 가능하도록 지정되어 있습니다.

elasticsearch의 대부분의 설정은 elasticsearch.yml라는 파일에서 관리하고 있습니다. 해당 파일을 열어 일부분 수정하여 외부 주소로 접근 할 수 있도록 하고자 합니다.
해당 파일을 열어보면 path를 제외한 모든 부분이 주석처리된 상태가 기본입니다.
[Spring][258] AWS EC2 Elasticsearch 외부 접속 환경 설정
로컬(나의 컴퓨터)의 외부접속 환경 만들어서 테스트하기
MySQL의 도서데이터는 book 테이블에 존재하고 709만 개의 대용량데이터로 이동 성공 및 실패를 떠나 AWS에 큰 비용을 초래할 수 있기 때문에 충분한 테스트를 진행하고 있는 과정입니다. 따라서 비교적 데이터양이 적은 book_category로 테스트를 우선 진행하고자 합니다.
Elasticsearch, Logstash, Kibana는 다른 컴퓨터(EC2 인스턴스)에 있으며 특히 Logstash는 내 컴퓨터의 MySQL에 접근해야 합니다. 따라서 내 컴퓨터의 MySQL의 외부 접속을 가능하도록 해야 합니다.
이는 AWS RDS에 MySQL을 구축해둔 프로젝트의 방향과 비슷하게 localhost가 아닌 특정 주소를 통해서 데이터를 받아 올 수 있는지에 대한 원격 접근을 테스트하기 위함입니다.
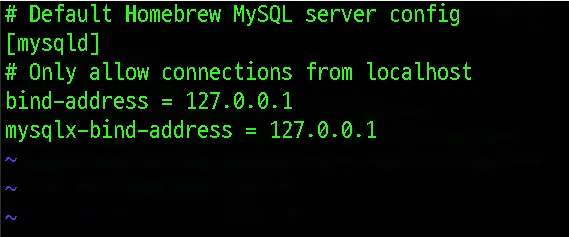
나의 로컬 컴퓨터의 콘솔에서 MySQL의 설정 파일을 찾아야 합니다. 우선 my.cnf 또는 my.ini라는 파일을 찾아야 합니다. 저의 경우 Homebrew를 통해 MySQL을 설치 했기 때문에 /usr/local/etc/ 라는 경로에서 찾을 수 있습니다.

해당 파일을 vi 에디터를 통해 열어보면 MySQL server 설정 정보가 나타나있습니다. 기본 설정은 localhost로 작동하도록 되어 있습니다.
[Spring][258] AWS EC2에 구현된 Elasticsearch 에 내 외부(RDS) MySQL 데이터 전달 테스트 및 EC2 스케일업
테스트 기준
MySQL Workbench 8.0을 사용하고 검색 키워드는 “황토집 짓기”를 사용한다.
변수는 ngram_token_size = 2, innodb_ft_min_token_size = 1을 설정하여 인덱싱한다.
인덱싱 기법은 구분자 기법, N gram 기법을, 검색 방식은 아래 세 명령어를 사용한다.
예상 결과
구분자 기법 : keyword를 구분자로 분류하여 저장, 검색 시에는 입력값이 저장된 값과 정확히 동일한 데이터를 출력
N-Gram 기법 : 2글자씩 분류하여 저장, 검색 시 입력값을 2글자씩 분류하여 저장한 값과 일치하는 데이터를 출력
•
CASE1. SELECT * FROM book WHERE MATCH(book_name) AGAINST('황토집 짓기');
구분자 기법의 경우 황토집, 짓기가 띄어쓰기로 정확히 구분된 데이터가 출력될 것으로 예상
N-Gram 기법의 경우 황토, 토집, 집짓, 짓기가 포함된 결과가 모두 출력될 것으로 예상
•
CASE2. SELECT * FROM book WHERE MATCH(book_name) AGAINST('황토집 짓기' IN boolean mode);
[Spring][258] FULLTEXT index 설정 및 검색 명령어 간 결과 테스트
AWS EC2에 Elasticsearch 설치하기
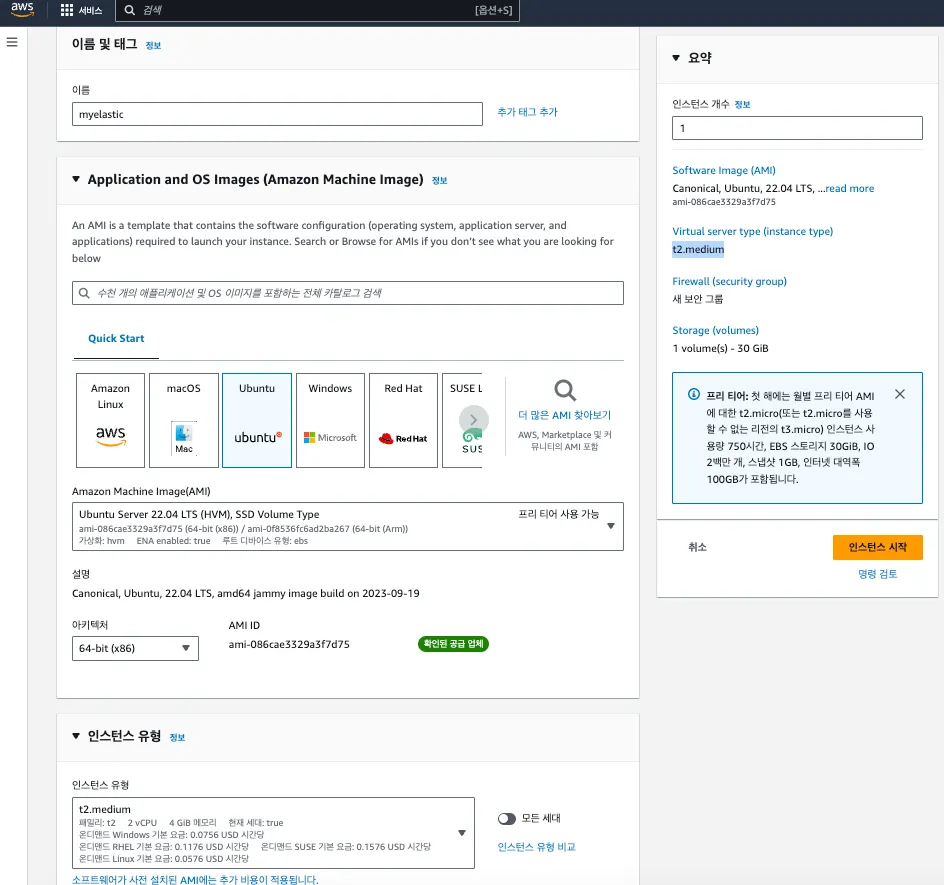
Elasticsearch 전용 EC2 인스턴스 생성합니다. 구글링을 통해 기본적으로 프리티어에서 사용되는 t1.micro로는 문제가 발생하는 것을 확인했고, t2.medium(2core CPU / 4GB RAM)을 최초 구성하는 것이 안정적인 테스트가 될 것으로 판단되었습니다.
인스턴스에 접속
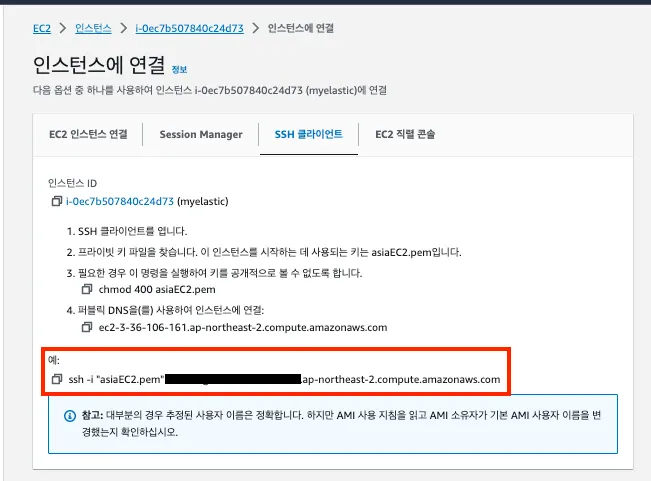
기본적으로 AWS 서비스의 키페어를 생성하고 로컬에 다운 받는 과정은 생략했습니다. 결과적으로 {keyname}.pem 이라는 확장자의 사용자 키를 로컬에 받을 수 있고 이것을 통해서 EC2를 접속할 수 있는 권한을 얻게 됩니다. FTP 접속에서도 필요한 인증 방법입니다.
AWS 콘솔에서 간단히 브라우저에서도 콘솔로 EC2 내부에 접근 할 수도 있습니다. SSH 클라이언트에서 제공해주는 CLI 명령어를 통해서 로컬 터미널을 통해 EC2로 접근했습니다.
Elasticsearch 설치를 위한 JDK 설치
[Spring][258] AWS EC2 ubuntu 환경의 Elasticsearch 구축
마이크로 서비스 아키텍처의 필요성
책나눔 서비스는 대규모 트래픽을 효율적으로 처리할 수 있는 시스템 구조가 필수적이었습니다.
이에 따라 기존의 모놀리식 구조에서 마이크로서비스 아키텍처로 전환하며, 이 과정에서 카프카를 도입하기로 결정했습니다.
카프카는 대용량 데이터를 여러 컨슈머가 병렬로 처리할 수 있게 해주어, 트래픽이 급증하는 상황에서도 메시지의 유실 없이 높은 처리량을 유지할 수 있습니다.
또한 각 마이크로서비스가 독립적으로 확장될 수 있도록 지원함으로써, 서비스의 확장성과 안정성을 보장하고, 시스템 전체의 부하 분산을 가능하게 합니다.
이러한 이유로 카프카는 고가용성이 요구되는 대용량 트래픽 환경에 매우 적합한 선택이라고 판단했습니다.
기존 서버의 모놀리식 아키텍처 흐름도

[Spring][258] 카프카를 통한 서비스 아키텍처 구조 개선
레디스 분산 락이란?
레디스(Redis) 분산 락은 여러 컴퓨터 또는 프로세스 간에 자원의 동시 접근을 제어하기 위한 메커니즘입니다.
분산 시스템에서 여러 노드가 동일한 자원에 접근하려 할 때, 일관성과 순서를 유지하면서 동시성 문제를 해결하는 데 쓰입니다.
레디스 분산 락의 필요성
•
동시성 관리: 복수의 인스턴스가 동일한 데이터를 동시에 수정하려 할 때, 데이터 불일치를 방지합니다.
•
일관성 유지: 분산 시스템 내에서 데이터의 일관성을 유지하며, 작업의 순서를 보장합니다.
•
데드락 방지: 데드락을 감지하고 해결하는 메커니즘을 제공합니다.
레디스 분산 락의 작동 원리 ( Redisson )
1.
락 회득: Redisson은 Lua 스크핍트를 사용하여 락을 획득합니다. 이 스크립트는 락키가 존재하지 않는 경우에만 락 키를 생성하고, 이 키에 대한 유효 시간 (TTL)을 설정합니다.
이로 인해 서버나 애플리케이션에 문제가 발생하여 락을 해제하지 못하는 경우에도 설정된 유효 시간 이후에 자동으로 락이 해제됩니다.
2.
레디스 키의 유효기간: 락을 회득 시 레디스 키에 유효기간을 설정하여 락 획득자가 특정 시간 안에 작업을 완료하지 못하면 락이 자동으로 해제되도록 합니다.
이를 통해 데드락을 방지합니다.
3.
락 재진입: Redisson은 동일한 락을 여러번 회득 할 수 있는 재진입 가능한 락을 지원합니다.
Lua 스크립트는 락을 요청하는 쓰레드나 인스턴스가 이미 락을 보유하고 있는지를 확인하고 만약 락을 가지고 있다면 락 획득 요청을 허용하여 재진입을 가능하게 합니다.
[Spring][258] 레디스 분산락을 이용한 동시성 문제 대응
Kafka를 시도하는 이유
1.
현재 진행 중인 프로젝트의 서비스는 대용량 트래픽을 받는 서비스입니다.
→ kafka를 사용하면 데이터 베이스나 애플리케이션에 락을 걸지 않고 전송 속도를 제어해서 동시성 문제가 발생하지 않는 속도로 순차적으로 전달한다면 락보다 속도가 빠를것입니다.
2.
확장성이 중요한 경우
→ 서비스가 계속 성장하고 더 많은 트래픽을 처리해야 할 경우, Kafka는 쉽게 확장할 수 있는 구조를 가지고 있어 미래의 성장에 대비할 수 있습니다.
3.
탄력성과 고가용성이 중요한 경우
→ Kafka는 분산 시스템으로 설계되어 있어 노드 하나가 실패하더라도 서비스의 가용성을 유지할 수 있습니다.
즉 저희 서비스의 확장성과 안정성, 서버 과부하 방지, 동시성 문제를 성능 저하하는 락없이 해결하기 위해 카프카를 시도하였습니다.
KafKa의 동작 흐름
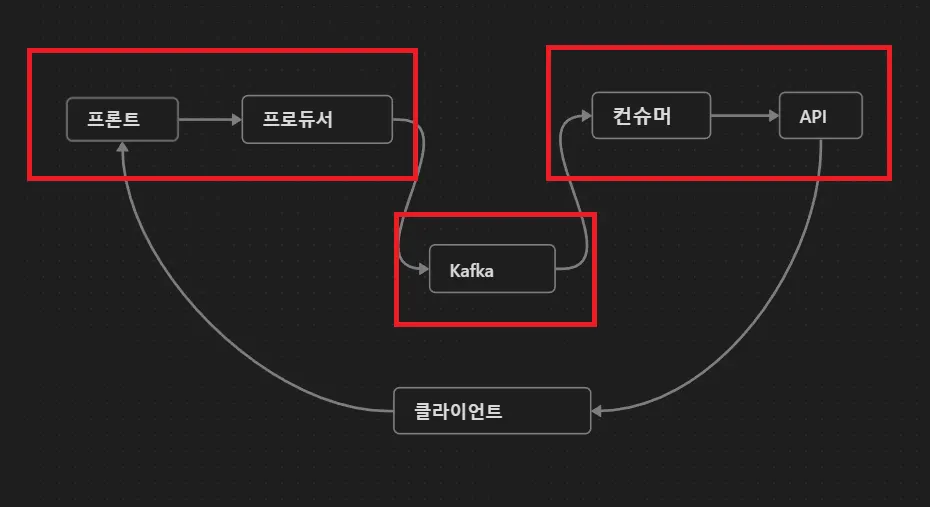
1.
프론트엔드에서 요청: 사용자의 액션에 의해 프론트엔드에서 백엔드로 HTTP 요청이 전송됩니다.
2.
Kafka 컨트롤러: Spring Boot 어플리케이션 내의 컨트롤러가 HTTP 요청을 받아 처리합니다.
3.
Kafka 프로듀서: 컨트롤러는 Kafka 프로듀서를 통해 메시지를 Kafka 서버의 특정 토픽으로 전송합니다.
[Spring][258] 카프카 도입으로 구조적으로 동시성 문제에 대응
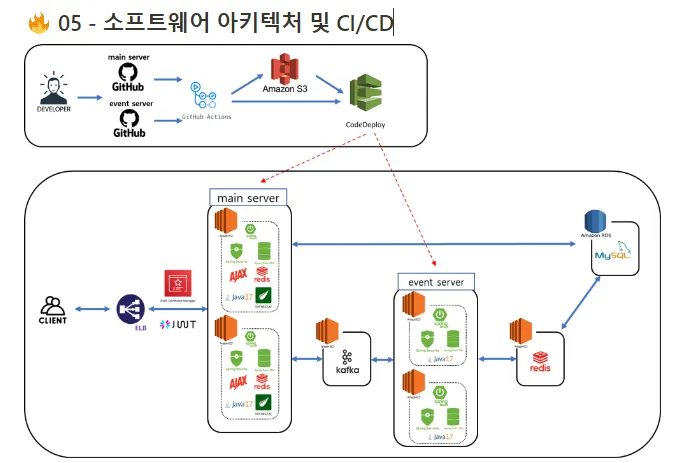
[Spring][258] 소프트웨어 아키텍처 및 CI/CD 가독성 올린 구조로 수정
MySQL DB의 데이터와 Elasticsearch 데이터는 동기화로 일관성을 유지해야 한다.
기존 MVP 기능으로 도서의 정보를 변경하는 부분들이 있습니다. 특히 Elasticsearch와 연결된 도서 목록에서 사용자는 도서 대출, 도서 대출 예약을 진행 할 수 있습니다.
사용자가 도서 대출을 진행하면 도서의 대출 가능 여부를 알 수 있는 Status 컬럼은 POSSIBLE에서 IMPOSSIBLE로 변경됩니다. 해당 기능은 HTML의 Ajax HTTP 요청을 통해 MySQL DB에 있는 대상 book_id의 도서의 상태를 즉시 변경하지만, Elasticsearch는 MySQL의 DB를 Logstash로 가져와서 인덱싱하기 때문에 이 과정에서 새로 목록을 불러와야 할 필요성이 있습니다.
Logstash의 데이터 변경 추적 설정 필요성
기존 Logstash를 통해 MySQL의 DB를 전달하여 색인하는 부분입니다. 709만개의 도서 데이터를 한번에 읽어오는 과정에서 JVM의 메모리 부족 현상이 발생하여 200만개씩 메모리에 로드하고 Elasticsearch로 전달하도록 구성되어있습니다.
하지만 이 부분에서 설정의 문제점이 있습니다.
•
최초 실행 1회 이후로 데이터를 전달하고 해당 소스는 종료됨
•
MySQL DB의 변경사항이 생기면 수동으로 해당 파일을 다시 실행시켜 주어야 업데이트가 됨
•
다시 한번 200만개씩 총 709만개를 돌면서 업데이트가 아닌 모든 정보를 덮어쓰는 형태
최초의 전체 709만개 도서 데이터 전달은 기본적으로 실행되어야 하는데 지속적으로 어떤 도서의 정보 업데이트에 대한 별도 동기화 처리가 필요했습니다.
Logstash의 tracking_column을 이용한 변경 추적

공식 문서에 따라서 tracking_column을 통해서 특정 컬럼의 값이 변경되는 것을 추적할 수 있고, Elasticsearch에 변동된 행만을 업데이트 할 수 있는 방안이 있었습니다.
[Spring][258] MySQL→Logstash→Elasticsearch 의 동기화 처리에서 발생하는 문제
현재 프로젝트에서 책 대출, 책 나눔 신청 2가지 기능에서 동시성 오류가 발생합니다.
1. 책 대출 신청
사용자는 아래와 같이 책을 검색하고 대출 버튼을 눌러 책을 대출할 수 있습니다.
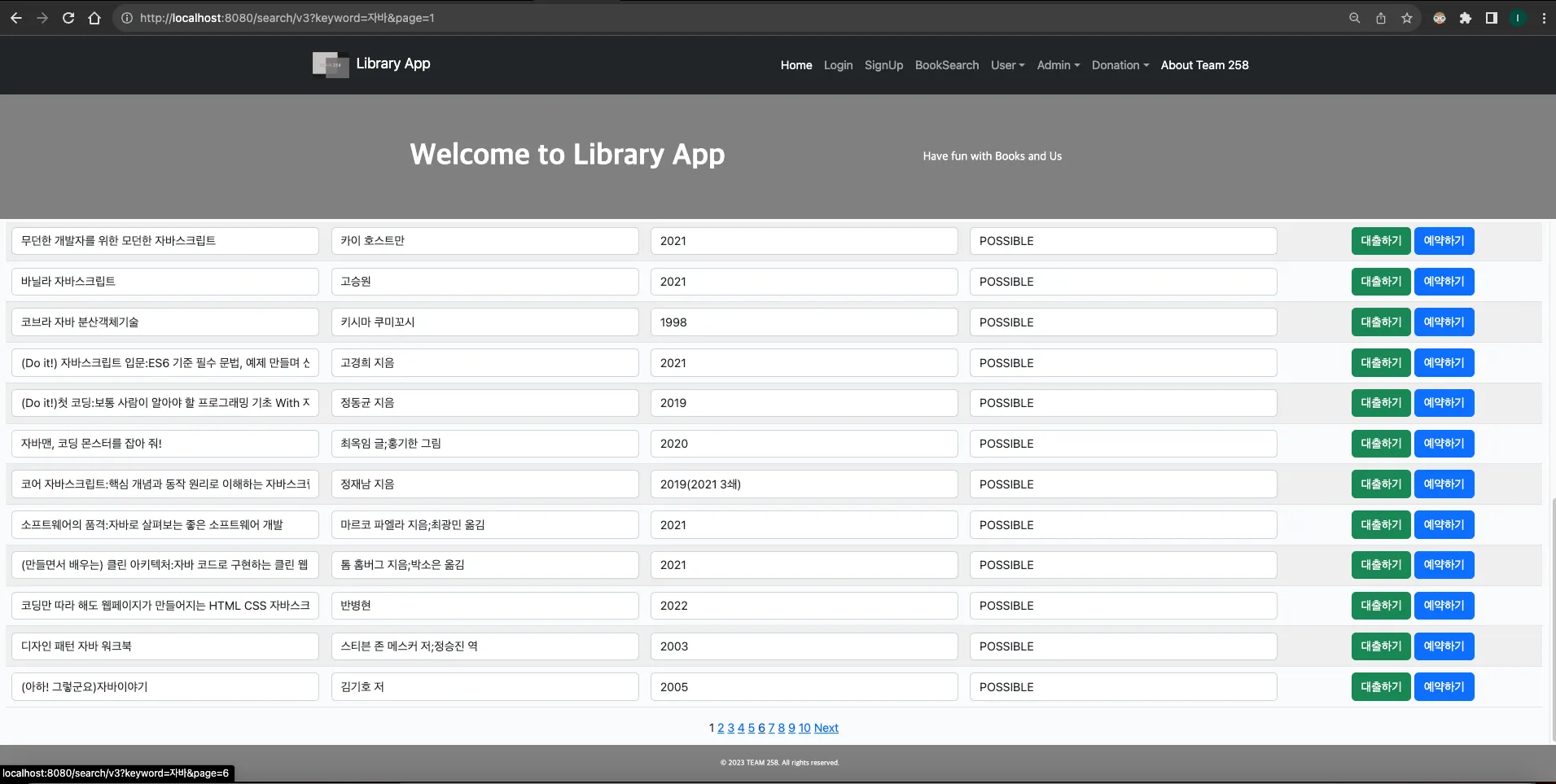
여러명이 동시에 같은 책에 대한 대출 버튼을 누르는 경우 아래와 같이 여러 건의 책 대출 데이터가 생기는 동시성 문제가 발생합니다.

[Spring][258] 현재 프로젝트 내에서 동시성 문제
동시성 제어란?
동시성 제어란 여러 사용자나 시스템이 데이터베이스나 파일 시스템 같은 공유 자원에 동시에 액세스할 때 발생할 수 있는 문제(동시성문제)들을 관리하고 해결하기 위한 기술입니다.
데이터의 일관성과 무결성을 유지하면서, 여러 요청이 서로 간섭하지 않고 동시에 처리될 수 있도록 보장하는 역할을 합니다.
웹 서비스에서의 동시성 문제란?
웹 서비스에서의 동시성 문제란 여러 사용자가 동시에 웹 서비스의 리소스에 접근하거나 조작할 때 발생하는 충돌 또는 데이터 무결성 문제를 말합니다.
웹 서비스는 대개 많은 사용자가 동시에 같은 애플리케이션을 사용하기 때문에, 이러한 문제는 흔하게 발생할 수 있습니다.
동시성 제어가 필요한 이유
동시성 제어가 필요한 이유는 여러 사용자나 프로세스가 동시에 데이터베이스나 파일 시스템과 같은 공유 자원에 접근할 때 발생할 수 있는 여러 가지 문제들을 예방하고 해결하기 위함입니다.
•
발생 가능한 여러가지 문제
1.
분실된 갱신 (Lost Update): 두 개 이상의 트랜잭션이 동시에 같은 데이터를 수정할 경우, 한 트랜잭션에 의한 변경 사항이 다른 트랜잭션에 의해 덮어쓰여 분실될 수 있습니다.
2.
모순성 (Inconsistency): 동시에 같은 데이터에 접근하여 갱신하는 작업이 발생하면 데이터가 모순된 상태로 남을 위험이 있습니다.
3.
연쇄 복귀 (Cascading Rollback): 하나의 트랜잭션이 실패하여 롤백할 때, 그 트랜잭션에 의존하는 다른 트랜잭션들도 롤백해야 하는 상황이 발생할 수 있습니다.
4.
비완료 의존성 (Uncommitted Dependency): 아직 커밋되지 않은 데이터를 다른 트랜잭션이 참조하게 되면, 그 트랜잭션이 실패했을 때 문제가 생길 수 있습니다.
5.
데드락 (Deadlock): 두 트랜잭션이 서로가 소유한 자원의 잠금을 기다리는 상태가 되어, 시스템이 정지하는 현상이 발생할 수 있습니다.
[Spring][258] 웹 서비스 동시성 제어
1. 개요
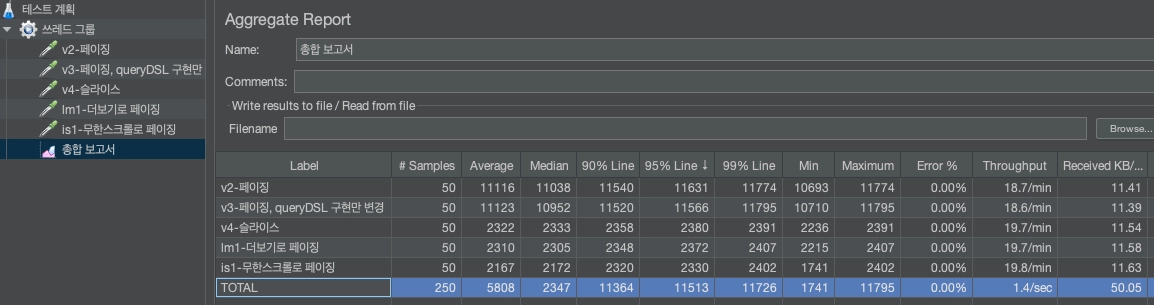
동시성 문제를 해결하기 위한 다양한 방법들을 모두 적용해보며 JMeter로 테스트를 하고
최종적으로 결정한 방법을 선택한 과정을 정리하였습니다.
2. 동시성 해결 성능 테스트
책 나눔 신청에 대한 동시성 오류를 해결하기 위해 아래의 4가지 방법을 사용하였습니다.
1.
뮤텍스
2.
낙관적락
3.
비관적락
4.
@Transactional(isolation = Isolation.SERIALIZABLE)
4가지 방법 모두 동시성 오류가 성공적으로 해결이 되었고, 이에 대한 성능 테스트를 진행하였습니다.
테스트는 로컬에서 진행하였으며, Jmeter로 100개의 쓰레드에서 요청을 0.1초 안에 보내는 방식으로 여러 번 측정하여 평균값을 구하였습니다. 테스트 결과는 아래와 같습니다.
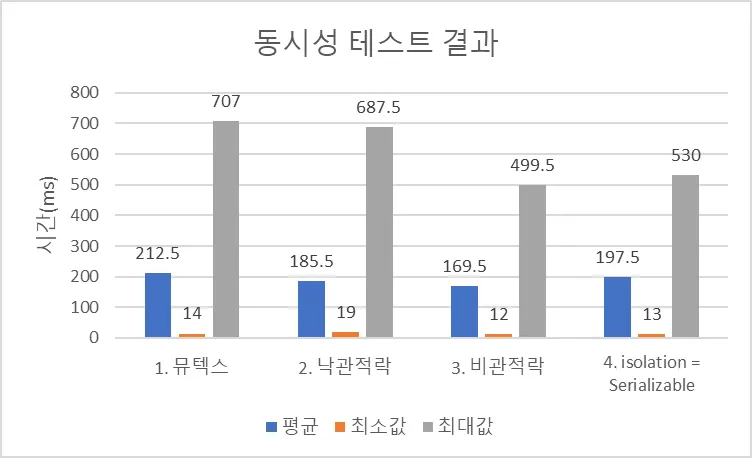
[Spring][258] 데이터베이스 및 애플리케이션 레벨에서의 동시성 문제 대응
지속적인 통합(CI)과 지속적인 배포(CD) 란?

개발 환경에서 지속적인 통합(CI)과 지속적인 배포(CD)는 코드의 품질을 유지하면서 빠르고 안정적인 배포를 가능하게 하는 핵심 요소들입니다.
지속적인 통합 (CI)
[Spring][258] CI/CD GitHub Action을 선택한 이유
책 나눔 서비스
책나눔 서비스는 사용자가 지정된 기간 내에 접속하여 원하는 도서를 요청하고 먼저 신청한 사용자가 해당 책을 수령할 수 있는 서비스입니다.
이 서비스는 짧은 시간 내에 많은 사용자가 동시에 도서를 신청하는 방식으로 운영되므로 상당한 양의 트래픽이 발생할 것으로 예상됩니다.
그렇기 때문에, 트래픽의 증가에 유연하게 대응할 수 있도록 서비스 확장성을 고려해야 합니다. 이에 따라, 기존 단일 구조의 모놀리식 아키텍처보다는, 필요에 따라 쉽게 확장할 수 있는 마이크로서비스 아키텍처로 전환하려고 합니다.
[Spring][258] 프로젝트 내 마이크로서비스 아키텍처 적용
마이크로 서비스 아키텍처란?
마이크로서비스 아키텍처는 소프트웨어 개발에서 사용되는 설계 접근 방식 중 하나입니다.
이 아키텍처는 큰 규모의 애플리케이션을 작고 독립적으로 실행 가능한 서비스들의 모음으로 분할합니다.
각 서비스는 특정 비즈니스 기능을 담당하고, 서로 독립적으로 개발, 배포, 운영될 수 있습니다.
마이크로서비스 아키텍처의 주요 특징
1.
분산 구조: 애플리케이션의 기능이 작고 독립적인 서비스로 나뉘어져 있으며, 각각 독립적으로 개발 및 배포될 수 있습니다.
2.
서비스 지향: 각 기능은 서비스로서 개별적으로 기능하며, API를 통해 서로 통신합니다.
3.
수평적 확장: 시스템을 확장하기 위해 개별 서비스를 복제하거나 분산하여 시스템의 부하를 분산시키는 수평적 확장이 가능합니다.
4.
복잡성의 분산: 시스템의 복잡성이 각 서비스로 분산되어 있어, 관리 및 업데이트가 유연합니다.
5.
장애의 격리: 하나의 서비스에 문제가 발생하더라도, 다른 서비스는 영향을 받지 않거나 최소화되는 장애 격리 특성을 가집니다.
프로젝트 내의 마이크로서비스 아키텍처 적용의 필요성
프로젝트에서는 대규모 트래픽을 처리하는 책나눔 서비스에 직면하여 효율적인 관리와 확장성을 위해 책나눔 서비스에 마이크로서비스 아키텍처 적용이 필요하다고 생각합니다.
이는 책나눔 서비스의 확장성과 유연성을 크게 향상시켜서 독립적으로 확장할 수 있게 하며, 시스템 전체의 안정성을 강화합니다. 특히 트래픽이 많은 책 나눔 서비스를 개별적으로 리소스를 조정하여 전반적인 서비스의 탄력성을 보장할 수 있습니다.
이러한 접근은 저희 프로젝트의 지속가능한 확장과 향후 시장의 변화에 유연하게 대처할 수 있기에 책나눔 서비스에 대한 마이크로서비스 아키텍처가 필요한 것으로 보입니다.
[Spring][258] 마이크로서비스 아키텍처
문제 상황 및 원인
구분자 기법의 FULLTEXT indexing은 keyword를 자동으로 규칙에 맞춰 분류해 준다. 그러나 검색 시에는 생성된 keyword가 정확히 일치한 데이터만 출력해 준다. 그렇기에 like 구문을 사용한 데이터와 구분자 기법의 FULLTEXT index를 활용한 데이터는 서로 다른 결과값을 출력한다.

해결 방법
MySQL FULLTEXT indexing 기법에는 N-gram 기법이 있다. 구분자 기법과는 다르게 모든 데이터를 N글자씩 분리하여 keyword로 생성하는 방법이다.
분리되는 글자 수는 ngram_token_size 변수명으로 관리되고 있고 변경하려면 my.ini에 동일하게 값을 넣어 수정할 수 있으나 기본값이 2이기에 따로 수정하지 않았다.
[Spring][258] keyword 검색 시 keyword를 포함한 일부 데이터가 검색되지 않는 문제
MySQL에서 지원하는 FULLTEXT 명령어는 기본적으로 구분자 기법을 사용하고 있기에 단순한 명령어만으로도 인덱싱이 가능하다.
위 명령어를 입력하면 자동으로 해당 테이블의 해당 컬럼을 기준으로 index를 생성한다.
다만 시간이 오래 걸릴 경우 workbench에서는 timeout이 일어나기에 명령 프롬프트에서 mysql에 접근해 명령어를 입력해 주어야 했다.
FULLTEXT index를 활용한 검색은 LIKE절을 사용하지 않는다. MATCH ~ AGAINST라는 FULLTEXT index를 위한 검색 명령어가 따로 존재한다.
위 명령어를 통해 FULLTEXT index 검색을 활성화할 수 있다.

explain() 명령어에 위 명령어를 넣어 실행하면 fulltext index를 사용하고 있음을 볼 수 있다.

Like 구분을 사용했을 때보다 훨씬 빠른 응답을 보여주고 있다.
그러나 like 구문을 사용했을 때와는 다르게 동일한 검색어에도 다른 결과값이 나오고 있는데, 이는 구분자 기법으로 생성된 keyword가 정확히 “스프링”으로 분리되지 않았다면 이 방법으로는 찾을 수 없게 되어 일부 데이터가 감지되지 않은 것이다.
[Spring][258] 구분자 기법을 활용한 FULLTEXT indexing
문제 상황
기본 설정으로 FULLTEXT indexing을 하게 되면 3글자 이상의 단어들만 검색이 가능하며, 2글자 이하의 단어는 검색이 되지 않는다.
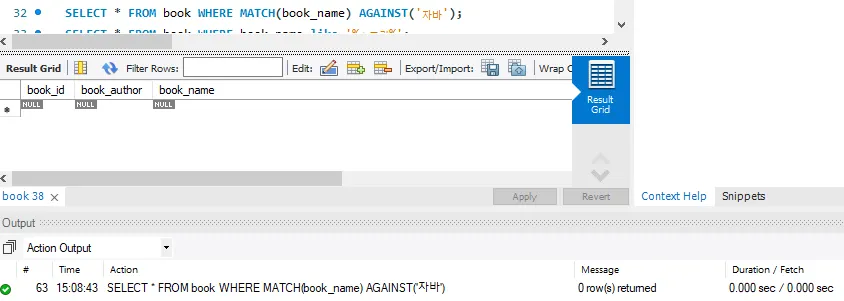
문제 원인
기본적으로 MySQL은 Storage engine으로 innodb라는 것을 사용한다.
%programdata%\MySQL\MySQL Server 8.0\my.ini 파일을 보면 아래와 같은 설정이 되어 있음을 알 수 있다.
[Spring][258] 구분자 기법의 FULLTEXT index가 2자 이하의 단어를 검색할 수 없는 문제
FULLTEXT index
FULLTEXT 인덱스는 문자열 데이터에 대해 전문 검색 기능을 제공하는 인덱스 유형이다. 이를 사용하면 특정 단어 또는 구문이 포함된 문장을 빠르게 찾을 수 있다. FULLTEXT 인덱스는 전체 문장을 토큰으로 분해하여 효과적으로 검색을 수행할 수 있도록 만들어 준다.
FULLTEXT index에는 두 가지 기법이 있다.
구분자(Stopword) 기법
•
공백, 탭, 문장기호, 또는 사용자 정의 문자열을 구분자로 등록
•
구분자 기법은 이렇게 생성한 구분자를 이용하여 내용을 분리, 키워드를 분석하고 결과 단어를 인덱스로 생성해 두고 검색에 이용하는 방법
•
MySQL에는 기본적으로 지정된 구분자가 있으며, 이를 비활성화할 수 있음.
N-그램(N-Gram) 기법
•
컬럼의 내용을 무조건적으로 N자씩 잘라서 인덱싱하는 방법
•
구분자 기법보다 알고리즘이 복잡하고 크기가 큼
•
다양한 언어에 대한 하나의 규칙을 적용하거나 키워드 일부 검색이 불가능한 구분자 기법을 보완할 수 있음
•
N은 인덱싱할 키워드의 최소 글자 수를 의미하고, 일반적으로 2의 크기를 가짐.
[Spring][258] FULLTEXT indexing
1. 접속 환경 설정
build.gradle 의존성 추가
application.properties 연결 주소 입력
ElasticsearchConfig.java를 통한 Elasticsearch 실제 커넥션
application.properties에서 직접 연결 할 수도 있지만 모듈화시켜서 구조를 살펴보고자 했습니다.
2. 3 Layered 아키텍처와 Elasticsearch 연결
ElasticsearchBook.java JPA엔티티와의 충돌을 막기 위한 전용 엔티티 생성
기존 Book.java 엔티티에 @Document 어노테이션을 사용하면 JPA와 Elasticsearch가 동시에 해당 엔티티에 접근하게 되면서 충돌 문제가 발생했었습니다. 여러 참고자료를 찾아본 결과 ~Application.java 메인 이닛 클래스에서 @Enable.. 어노테이션을 통해서 각각 스캔 대상을 분리 시킬 수도 있지만, 우선 간략한 테스트 과정을 위해서 우선 별도의 엔티티를 생성하는 것으로 대체했습니다.
•
@Document어노테이션으로 인덱스명(RDBMS의 테이블명과 비슷)을 입력하면 의 인덱스와 맵핑됩니다.
•
@Field어노테이션으로 각 필드(RDBMS의 컬럼과 비슷) 타입, 이름을 지정하게 됩니다.
•
Elasticsearch는 소문자로만 구성하라는 주의사항이 있었고 이름에 스네이크 컨벤션을 유지했습니다.
[Spring][258] 프로젝트에서 3 Layered Architecture와 Elasticsearch 연결 테스트
문제 원인

문제의 원인은 SSH 키 파일(Team258_RedisServer.pem)의 권한이 너무 개방적으로 설정되어 있어서 발생한 걸로 추정 됩니다.
이 파일은 사용자 본인만이 접근할 수 있도록 제한되어야 합니다.
문제 해결
[Spring][258] 트러블 슈팅 : SSH 권한 부족 GUI 기반 문제 해결
분산락 이란 동시성 문제를 해결하기 위한 방법 중 하나로 같은 자원에 접근할 시 락을 제공하여 접근이 완료되면 락을 해제하여 다음 순번에게 넘어가는 방식이다.
분산락을 사용하는 이유는 분산된 서버 및 분산된 DB환경에서도 동시성 이슈를 해결하기 위함이다.
분산락을 Redis로 구현하는 방법에는 lettuce, redisson 라이브러리가 있는데 lettuce방식은 스핀락(락을획득하지 못할 경우 계속 요청) 방식으로 redis에 부하가 갈 수 있어 redisson을 사용하여 구현해보았다.
RedissonConfig를 작성하여 Bean에 등록하고
BookApplyDonationService에 아래와 같이 구현하였다.
잘 구현은 되나 bookApplyDonation2 를 추가로 생성하여 만드는 찝찝함이 있는데 이에 대한 내용은 별도 트러블슈팅 문서에 정리하겠다.
[Spring][258] redisson 분산 락 구현
여러 방법으로 동시성 문제를 해결한 방법들에 대해서 성능 테스트를 진행하였다.
Jmeter로 100개의 쓰레드에서 0.1초로 요청하였음
Jmeter 첫번째 테스트 시 매우 큰(느린) 값이 나오는 이슈가 있어 평균값에서 제외하고 2,3번쨰 시행의 평균값을 냈다.

bookDonation2,3번째 시행의 평균값 | |
1. ReentrantLock | 212.5 |
2. @Version 사용한 낙관적락 | 185.5 |
3. 비관적락 | 169.5 |
4. isolation = Serializable | 197.5 |
5. redisson 분산락 | 359 |
테스트 결과는 위와 같다
아래에 엑셀 파일을 첨부한다.
동시성 성능 테스트.xlsx
18.0KB
[Spring][258] 동시성 해결 성능 테스트
Redis 분산락 구현 ( AWS Server )
설치 환경
•
AWS EC2 Ubuntu
•
c5.xlarge
Redis EC2에 설치


Redis 설정 파일 변경
[Spring][258] AWS EC2 Redis 분산락 구현
버전 호환 확인 필요
버전간의 제공되는 클래스, 삭제된 기능 등 레퍼런스간의 차이가 유독 심해서 기능 구현에서 참고 자료를 활용하지 못하는 경우가 많았다.
많은 예제에서 사용하고 있는 RestHighLevelClient의 사용 불가 문제
spring-data-elasticsearch:5.1.3 버전에서 RestHighLevelClient을 사용 할 수 없었습니다. RestHighLevelClient는 Elasticsearch를 RESTful API를 통해 효과적으로 사용할 수 있도록 하는 Elasticsearch Java 클라이언트 라이브러리 중 하나입니다. 이 라이브러리는 Elasticsearch의 REST API와 상호 작용하여 데이터를 쿼리하고 색인화하며, 기타 Elasticsearch 작업을 수행하는 데 사용됩니다. 이를 통해 객체 지향적이고 사용하기 편리한 인터페이스를 제공합니다.
[Spring][258] Elasticsearch의 RestHighLevelClient 사용에 있어 의존성 주입 문제, 버전간의 호환 확인과 버전 명시 주입
메인 서버 스캐일 업

•
기존 인스턴스 t1.micro에서 c5.large로 변경
•
IOPS 3000
이벤트 적용 서버 스캐일 업
[Spring][258] 서버 스케일 업: AWS EC2 인스턴스 업그레이드 및 성능 향상
1. 문제
처음에 bookApplyService.java 에서 redisson으로 분산락을 구현한 코드는 아래와 같다
위와 같이 작성 시 기존 10개정도 발생하는 동시성 문제가 2~3개로 줄어들었으나,
2~3개의 동시성 문제가 발생되는 문제가 있었다.
2. 원인
위에서 작성한 코드의 일부이다.
@Transactional로 만들어진 트랜잭션이 닫히는 시점은 메소드가 끝나는 시점인데,
락을 해제하는 부분은 메소드가 끝나는 시점 이전이다.
따라서 락을 해제하고 메소드가 끝나는 시점 사이에 트랜잭션이 닫히지 않아서 동시성 이슈가 일부(1~2개) 발생하게 된다.
3. 해결
처음엔 클래스 내에서 추가 메소드를 작성하여 아래와 같이 로직 부분만 @Transactional을 걸어주었으나,
@Transactional 이 붙지 않은 메소드에서 같은 클래스 내 @Transactional 이 붙은 메소드를 실행하면 @Transactional이 적용되지 않는다고 한다.
[Spring][258] redisson 분산 락 구현 문제
Q. 한 주간 카프카에 대해서 아래와 같이 탐구하고 프로젝트에 적용해 보았습니다.
이러한 방법이 올바른 접근인지 피드백을 받고 싶습니다.
[Spring][258] 웹 서비스 카프카 적용 주간 정리
A. 멘토님답변정리!
접근 O, 더 심도있게 다룰 필요 O
Q. 아키텍처 구성과 관련된 질문 메인서버와 트래픽서버의 구분 이 방식에 대한 의견?
A. 멘토님답변정리!
아키텍처의 구성
메인,트래픽 서버를 나누는것보다는 도메인을 기준으로 나누는것이 확장, 유지보수적으로 유리 할 수 있다. → 추후 메인과 트래픽서버의 모호함이 발생하게 되므로
→ 마이크로 아키텍처의 방향으로 하려면 도메인, 데이터를 우선 기준으로 서버를 독립화 시키는 방향이 좋다. → Consumer group을 각각 → Topic은 1개로 연결
Q. Elasticsearch의 도서 데이터를 넣기 위해서 Logstash를 설치하여 설정 파일을 통해 MySQL DB의 도서 데이터를 전달해보고있습니다.
우선 이러한 방법이 올바른 접근 방법인지 알고 싶습니다.
대량 데이터는 아래처럼 나누어서 로드하는게 맞는지? 아니면 JVM의 메모리를 증가시키는지?
처음엔 별도의 설정 없이 710만건의 도서를 한번에 메모리에 올리고 전달하는 설정을 했고 JVM Heap의 OutOfMemory 문제가 나타났습니다.
따라서 jdbc_paging_enabled 옵션을 추가하여 50000건씩 로드하는 과정으로 나누니 메모리 문제는 나타나지 않았습니다.
설정파일의 주기에 대한 이해도 부족)
하지만 710만건을 다 로드하는데 다시 0부터 로드하고 있습니다.
→ 수가 데이터 카테고리로 테스트해보니 계속 로드하는것이 동일하게 나타났고, 무엇인지 생각해보니 설정 파일의 schedule => "* * * * *" # Query주기 설정에 따른것이고,
계속해서 그래서 매 분마다 SELECT * FROM book_category 쿼리를 실행하여 데이터를 가져오고 Elasticsearch로 전송하고 있는 것인것 같습니다. Logstash가 계속해서 데이터를 가져오고 Elasticsearch에 전송하는 동작을 수행하는것으로 정리.
그럼 계속 도서는 50000건씩 710만을 모두 돌면 계속해서 데이터를 가져오기 위한 동작인것이고, 이해가 됩니다.
그럼 주기가 길면 어떤 문제가 발생하는지 알고싶습니다. 그 사이 업데이트, 삭제 등 없어진 데이터가 있으면 아직 로드되지 않은 상태에서 검색의 오류가 나타날지 등..
A. 멘토님답변정리!
서버를 처음 띄울때 select * from… 이 맞을 수 있어도
서버가 유지되는 상황에서는 update에 대한 것만 불러올수 있는것을 확인해보기.
우선 데이터를 넣어두고,
변화된 데이터만 넣는것으로 구축해야 할 것 같다.
Q. Elasticsearch를 구성한다면 아키텍쳐가 보통 어떤방식으로 구성되는지 궁금했었습니다.
EC2 로컬에 설치하는것으로 생각했었는데 그럼 RDS에 MySQL을 실행하는것 처럼 Elasticsearch만의 별도의 서버를 구성하고 외부접속하듯이 접근해야 하는것으로 잘못 파악했었습니다.
서비스 시 로드밸런서로 인해 검색 요청이 Elasticsearch가 설치되지 않은 서버쪽으로 요청이 간다면 문제가 발생할것 같고, 똑같은 Elasticsearch를 설치해둔다면 그 두개는 각각 별도의 서버기 때문에 일관성은 어떻게 유지할지 궁금했었습니다.
좀더 찾아보니 Elasticsearch 자체가 설치하면서 노드로 구분되고 노드들끼리 연결된 집합들은 클러스터라는 단위로 서로 연결되는것으로 보여집니다.
따라서 Elasticsearch 노드(서버)간 클러스터(집합)을 구성하면 그 안에서는 자동적으로 분산하고 공유하는것 처럼 느껴지는데 맞게 이해하고 있는것인지 궁금합니다.
노드란?
클러스터란??
결론적으로 Elasticsearch 아키텍처의 특징
노드추가하기
A. 멘토님답변정리!
Q. Elasticsearch 관련된 세부 주제를 나누어보았습니다. 검색개선팀은 분담해서 하나씩 클리어해나가려합니다. 우선순위가 높은 주제부터 해나가고 부족한 것들은 프로젝트 이후에도 진행해나가려 합니다.
MySQL과 Elasticsearch의 비교가 가장 기본을 보여주고 세부 주제로 다루면 좋음
•
Full Text Index vs Elasticsearch 비교 심화
•
Elasticsearch의 기본에 대한 성능차이 MySQL에 대한것
◦
“검색어 기반”
A. 멘토님답변정리!
→ Elasticsearch와 비교하기 위해서는 Full Text 인덱싱에 대한 MySQL 에서의 테스트가 필요하다. → Ela VS Full Text 의 차이를 비교하는것이 핵심
페이징에서 가장 속도에 문제가 있었던 도서 전체 count 부분을 캐싱을 활용하고자 했음
1.
카운트 쿼리 자체를 캐싱하는것도 의미가 있다.
2.
첫페이지나, 특정 키워드의 첫페이지, 또는 그 검색 결과를 캐싱해두면 좋다.
3.
서비스에서 유도한경우( ex 카테고리 처럼, 정해진것 결과가 같은것을 캐싱하면 좋다)
4.
사용 주기와 데이터 업데이트 주기를 서로 고려해서 설계해야 한다.
[Spring][258] [4주차 멘토링] 질문내용 정리와 답변
통계 평균 | |||
카프카 | |||
단일 트래픽 서버 | 다중 트래픽 서버 | ||
단일 파티션 | 다중 파티션 | 단일 파티션 | 다중 파티션 |
525.6 | 591.5 | 336.4 | 354 |
뮤텍스 | 세마포어 | 비관적인 락 | Transactional Serializable |
607.6 | 585.6 | 393.2 | 555.1 |
구분 | 표본수 | 평균 | 중간값 | 90% | 95% | 99% | 최소값 | 최대값 | 오류 | 처리량 | 수신 KB / 초 | 전송 KB / 초 | 동시성 문제 |
1. 카프카 다중 트래픽 서버 / 다중 파티션 | 100 | 399 | 394 | 504 | 519 | 529 | 260 | 533 | 0 | 185.8736 | 71.88081 | 91.12163 | X |
100 | 362 | 387 | 436 | 447 | 543 | 190 | 556 | 0 | 177.9359 | 68.81117 | 87.23032 | X | |
100 | 360 | 358 | 445 | 457 | 464 | 246 | 472 | 0 | 210.084 | 81.24343 | 102.9904 | X | |
100 | 348 | 338 | 425 | 437 | 451 | 234 | 452 | 0 | 219.2982 | 84.80674 | 107.7217 | X | |
100 | 354 | 340 | 450 | 468 | 487 | 200 | 516 | 0 | 193.0502 | 74.65613 | 94.82837 | X | |
100 | 388 | 384 | 476 | 484 | 491 | 271 | 493 | 0 | 200.4008 | 77.49875 | 98.43907 | X | |
100 | 359 | 357 | 460 | 466 | 476 | 241 | 480 | 0 | 207.0393 | 80.06599 | 101.7 | X | |
100 | 334 | 333 | 408 | 425 | 435 | 222 | 440 | 0 | 227.2727 | 87.89063 | 111.6388 | X | |
100 | 313 | 305 | 382 | 398 | 408 | 216 | 408 | 0 | 241.5459 | 93.41033 | 118.65 | X | |
100 | 323 | 309 | 415 | 426 | 438 | 244 | 440 | 0 | 226.2443 | 87.49293 | 111.1337 | X | |
카프카 단일 트래픽 서버 / 단일 파티션 | 100 | 521 | 514 | 782 | 824 | 844 | 190 | 854 | 0 | 116.9591 | 45.23026 | 57.45157 | X |
100 | 560 | 558 | 821 | 852 | 876 | 244 | 879 | 0 | 112.7396 | 43.59851 | 55.37891 | X | |
100 | 571 | 575 | 852 | 880 | 904 | 244 | 918 | 0 | 108.4599 | 41.94347 | 53.27667 | X | |
100 | 596 | 603 | 867 | 900 | 924 | 249 | 927 | 0 | 107.2961 | 41.49343 | 52.70504 | X | |
100 | 538 | 523 | 814 | 851 | 866 | 227 | 876 | 0 | 113.6364 | 43.94531 | 55.81942 | X | |
100 | 452 | 450 | 690 | 713 | 744 | 191 | 753 | 0 | 132.626 | 51.28896 | 65.14734 | X | |
100 | 459 | 444 | 708 | 738 | 761 | 124 | 762 | 0 | 129.7017 | 50.15807 | 63.71089 | X | |
100 | 551 | 547 | 796 | 834 | 852 | 233 | 858 | 0 | 116.0093 | 44.86296 | 56.98503 | X | |
100 | 530 | 529 | 779 | 804 | 824 | 231 | 829 | 0 | 119.3317 | 46.14782 | 58.61706 | X | |
100 | 478 | 471 | 708 | 739 | 768 | 191 | 778 | 0 | 128.5347 | 49.70678 | 63.13765 | X | |
카프카 다중 트래픽 서버 / 단일 파티션 | 100 | 439 | 442 | 576 | 588 | 601 | 224 | 612 | 0 | 163.3987 | 63.18934 | 80.26323 | X |
100 | 346 | 342 | 455 | 462 | 478 | 199 | 478 | 0 | 205.7613 | 79.57176 | 101.0722 | X | |
100 | 314 | 306 | 405 | 422 | 432 | 208 | 434 | 0 | 227.2727 | 87.89063 | 111.6388 | X | |
100 | 378 | 369 | 473 | 504 | 512 | 164 | 516 | 0 | 191.9386 | 74.22625 | 94.28233 | X | |
100 | 354 | 357 | 453 | 464 | 478 | 212 | 480 | 0 | 205.3388 | 79.40837 | 100.8647 | X | |
100 | 326 | 324 | 424 | 447 | 453 | 171 | 455 | 0 | 217.8649 | 84.25245 | 107.0176 | X | |
100 | 309 | 294 | 403 | 418 | 425 | 190 | 426 | 0 | 232.5581 | 89.93459 | 114.2351 | X | |
100 | 326 | 324 | 428 | 441 | 445 | 173 | 447 | 0 | 220.7506 | 85.36838 | 108.4351 | X | |
100 | 310 | 286 | 434 | 450 | 460 | 188 | 461 | 0 | 215.0538 | 83.16532 | 105.6368 | X | |
100 | 262 | 282 | 386 | 401 | 416 | 91 | 417 | 0 | 234.7418 | 90.77905 | 115.3077 | X | |
카프카 단일 트래픽 서버 / 다중 파티션 | 100 | 562 | 559 | 770 | 803 | 821 | 327 | 827 | 0 | 119.6172 | 46.25822 | 58.75729 | X |
100 | 603 | 600 | 819 | 846 | 866 | 262 | 876 | 0 | 114.0251 | 44.09564 | 56.01037 | X | |
100 | 598 | 591 | 828 | 853 | 875 | 327 | 884 | 0 | 112.8668 | 43.64771 | 55.44142 | X | |
100 | 522 | 505 | 736 | 771 | 797 | 229 | 804 | 0 | 124.2236 | 48.0396 | 60.89868 | X | |
100 | 591 | 575 | 856 | 880 | 902 | 243 | 905 | 0 | 109.7695 | 42.44992 | 53.81277 | X | |
100 | 686 | 681 | 929 | 956 | 976 | 386 | 986 | 0 | 101.0101 | 39.0625 | 49.51862 | X | |
100 | 567 | 566 | 803 | 826 | 862 | 252 | 866 | 0 | 115.0748 | 44.50158 | 56.41362 | X | |
100 | 604 | 604 | 824 | 851 | 873 | 310 | 877 | 0 | 113.2503 | 43.79601 | 55.51918 | X | |
100 | 645 | 649 | 867 | 898 | 921 | 358 | 924 | 0 | 107.6426 | 41.62742 | 52.77012 | X | |
100 | 537 | 534 | 783 | 808 | 833 | 235 | 841 | 0 | 118.2033 | 45.71144 | 57.94733 | X | |
2. 뮤텍스 | 100 | 661 | 649 | 880 | 899 | 930 | 393 | 930 | 0 | 106.383 | 41.14029 | 53.0876 | X |
100 | 669 | 672 | 885 | 924 | 944 | 397 | 946 | 0 | 104.6025 | 40.45175 | 52.1991 | X | |
100 | 677 | 676 | 891 | 917 | 940 | 391 | 1031 | 0 | 95.96929 | 37.11312 | 47.89092 | X | |
100 | 636 | 637 | 847 | 878 | 897 | 361 | 899 | 0 | 109.7695 | 42.44992 | 54.77755 | X | |
100 | 613 | 613 | 835 | 859 | 881 | 338 | 883 | 0 | 112.2334 | 43.40278 | 56.00712 | X | |
100 | 624 | 621 | 846 | 870 | 891 | 348 | 897 | 0 | 110.6195 | 42.77862 | 55.20171 | X | |
100 | 535 | 533 | 734 | 756 | 784 | 283 | 786 | 0 | 125.9446 | 48.70513 | 62.8493 | X | |
100 | 597 | 594 | 815 | 839 | 855 | 335 | 863 | 0 | 115.0748 | 44.50158 | 57.42502 | X | |
100 | 528 | 522 | 731 | 765 | 788 | 275 | 795 | 0 | 124.8439 | 48.27949 | 62.30005 | X | |
100 | 536 | 536 | 733 | 763 | 782 | 284 | 785 | 0 | 125.9446 | 48.70513 | 62.8493 | X | |
3. 세마포어 | 100 | 575 | 571 | 790 | 811 | 840 | 315 | 845 | 0 | 117.9245 | 45.60363 | 59.99871 | X |
100 | 637 | 632 | 853 | 878 | 903 | 376 | 913 | 0 | 109.2896 | 42.26434 | 55.60536 | X | |
100 | 598 | 600 | 813 | 838 | 859 | 329 | 863 | 0 | 115.0748 | 44.50158 | 58.5488 | X | |
100 | 680 | 680 | 904 | 934 | 950 | 386 | 957 | 0 | 104.2753 | 40.32521 | 53.05413 | X | |
100 | 547 | 549 | 754 | 783 | 804 | 285 | 806 | 0 | 123.0012 | 47.56688 | 62.58168 | X | |
100 | 586 | 591 | 807 | 834 | 854 | 279 | 865 | 0 | 115.2074 | 44.55285 | 58.61625 | X | |
100 | 519 | 515 | 718 | 743 | 764 | 257 | 775 | 0 | 128.2051 | 49.57933 | 65.10417 | X | |
100 | 557 | 562 | 767 | 798 | 815 | 298 | 823 | 0 | 120.919 | 46.76164 | 61.40417 | X | |
100 | 577 | 571 | 779 | 810 | 832 | 336 | 832 | 0 | 119.1895 | 46.09282 | 60.52592 | X | |
100 | 580 | 578 | 801 | 828 | 851 | 297 | 859 | 0 | 115.6069 | 44.70737 | 58.70665 | X | |
4. 비관적락 | 100 | 413 | 412 | 512 | 521 | 525 | 287 | 526 | 0 | 187.6173 | 72.55511 | 94.17507 | X |
100 | 405 | 417 | 506 | 511 | 519 | 273 | 521 | 0 | 191.2046 | 73.9424 | 95.97574 | X | |
100 | 403 | 405 | 511 | 517 | 526 | 265 | 527 | 0 | 188.6792 | 72.9658 | 94.70814 | X | |
100 | 383 | 383 | 490 | 505 | 511 | 244 | 511 | 0 | 193.7984 | 74.94549 | 97.27774 | X | |
100 | 381 | 384 | 468 | 477 | 485 | 265 | 487 | 0 | 204.0816 | 78.92219 | 102.4394 | X | |
100 | 562 | 557 | 686 | 692 | 714 | 426 | 717 | 0 | 139.47 | 53.93567 | 70.00741 | X | |
100 | 335 | 339 | 409 | 420 | 424 | 232 | 428 | 0 | 233.1002 | 90.14423 | 116.7778 | X | |
100 | 330 | 322 | 411 | 421 | 426 | 235 | 432 | 0 | 230.4147 | 89.1057 | 115.4324 | X | |
100 | 332 | 330 | 407 | 413 | 422 | 239 | 426 | 0 | 234.7418 | 90.77905 | 117.6001 | X | |
100 | 388 | 390 | 501 | 512 | 516 | 232 | 524 | 0 | 188.6792 | 72.9658 | 94.70814 | X | |
5. Transactional Serializable | 100 | 548 | 550 | 614 | 676 | 692 | 430 | 708 | 0.09 | 141.2429 | 53.31783 | 70.89733 | X |
100 | 566 | 569 | 659 | 665 | 670 | 459 | 675 | 0.09 | 147.7105 | 55.75927 | 74.14374 | X | |
100 | 521 | 523 | 607 | 610 | 615 | 415 | 621 | 0.09 | 160.2564 | 60.49523 | 80.44121 | X | |
100 | 552 | 556 | 621 | 650 | 662 | 436 | 663 | 0.12 | 150.1502 | 56.21833 | 75.36834 | X | |
100 | 532 | 527 | 624 | 633 | 642 | 387 | 646 | 0.09 | 154.7988 | 58.43502 | 77.70172 | X | |
100 | 524 | 534 | 616 | 632 | 636 | 398 | 636 | 0.09 | 156.7398 | 59.16775 | 78.67604 | X | |
100 | 714 | 723 | 818 | 821 | 826 | 472 | 827 | 0.18 | 120.3369 | 44.31549 | 60.4035 | X | |
100 | 494 | 496 | 579 | 586 | 593 | 388 | 598 | 0.09 | 166.6667 | 62.91504 | 83.65885 | X | |
100 | 505 | 506 | 602 | 609 | 615 | 396 | 620 | 0.09 | 160.5136 | 60.59233 | 80.57033 | X | |
100 | 595 | 596 | 667 | 704 | 719 | 413 | 719 | 0.16 | 137.1742 | 50.79733 | 68.85502 | X |
[Spring][258] Jmeter을 통한 대용량 트래픽 발생 성능 테스트
1. 문제
현재 진행하는 프로젝트에서 여러명이 동시에 1개의 책에 대해서 대출을 신청할 때 동시성 오류 발생
JMeter을 이용하여 100명이 동시에 1개의 책을 대출신청하도록 설정하였다.

Book과 BookRent는 일대일 관계이나, 10개의 bookRent가 생성된 모습이다.

2. 원인
책을 대출하는 로직은 아래와 같다.
[Spring][258] BookRent 동시성 문제 해결
이번주 동안 카프카를 진행한 내용
초기

Kafka를 시도하는 이유
[Spring][258] 웹 서비스 카프카 적용 주간 정리
대량의 도서 데이터 준비
약 710만건의 도서 데이터가 CSV파일로 정리되어있습니다. 문화데이터 포털의 도서 정보 데이터를 활용하고 있습니다.
이전 MySQL을 활용했던 기본 검색 기준에서도 동일한 데이터를 MySQL의 LOAD FILE을 통해서 입력해서 사용했었기 때문에 동일한 데이터를 Elasticsearch에 넣어서 검색 성능의 차이를 살펴보고자합니다.

Elasticsearch에 데이터를 넣는 방법
기본적으로 Elasticsearch에 직접 데이터를 넣는 방법과 Logstash를 활용하는 방법이 있습니다. 우선 직접 데이터를 넣는 방법으로 간단한 테스트부터 진행해보고자 합니다.
Elasticsearch에 데이터를 직접 넣기

[Spring][258] Elasticsearch 검색 성능 개선 05(X) - 대량 데이터 넣기 실패과정과 데이터 재가공을 통한 문제 해결
Elasticsearch 설치 이후, Logstash와 Kibana 설치 이유
Elasticsearch를 단순 DB로 보고 데이터를 넣어보고자 했으나, 궁극적으로 Elasticsearch를 사용하는 목적에 큰 영향을 주는 부분이 아니라고 판단되었습니다. Logstash를 사용하여 다양한 데이터 소스에서 데이터를 수집하고 Elasticsearch에 전송하는 것은 일반적인 방법이므로 곧바로 적용해보기로 결정했습니다.
또한 Kibana라는 분석 툴에서 어떤것들을 확인 할 수 있는지 확인하고자 이 또한 설치하면서 ELK 스택을 모두 설치해보는 기본 환경 구축을 진행하고자 합니다.
Logstash, Kibana 설치
Elasticsearch 설치 과정은 아래 링크
Elasticsearch와 동일한 문제가 발생해서 곧바로 패키지 설치 정보를 수정해주었다.
Elasticsearch, Logstash, Kibana를 설치하고 모두 실행시켜줍니다.

[Spring][258] Elasticsearch 검색 성능 개선 04 Logstash, Kibana 추가 설치 ELK stack 구성
MySQL - Logstash - Elasticsearch의 연결을 하는 이유?
간단히 mysql의 데이터를 사용해서 elasticsearch에서 검색을 하기위해서는 elasticsearch DB에 데이터를 담아야합니다. 이를위한 도구로서 Logstash를 사용하게 됩니다.
Logstash을 사용하여 MySQL과 Elasticsearch 간의 데이터 전송을 쉽게 설정할 수 있습니다. Logstash은 다양한 데이터 소스에서 데이터를 수집하고 처리하여 다른 저장소로 전송하는 역할을 합니다.
해당 과정은 Elasticsearch, Logstash, Kibana인 ELK 스택을 설치한 이후로 진행되는 과정입니다. 아래 링크를 통해 설치와 실행 상태를 확인후 진행해야 합니다.
설치와 관련된 링크 참고
우선 Logstash를 통해 Elasticsearch에 데이터가 전달되어야 한다.
Logstash를 통한 Elasticsearch 데이터 전달 설정 절차
1.
Logstash 설치: 먼저 Logstash을 설치합니다.
2.
Logstash 설정 파일 작성: Logstash은 설정 파일을 통해 입력(Input), 필터(Filter), 출력(Output)을 정의합니다. MySQL과 Elasticsearch 간의 연결 정보를 설정합니다.
3.
Logstash 실행: 작성한 Logstash 설정 파일을 사용하여 Logstash을 실행합니다.
Logstash 설정 파일 위치 확인
Logstash의 설정 파일은 설치된 디렉토리에 위치한다. 로컬에 설치했으므로,
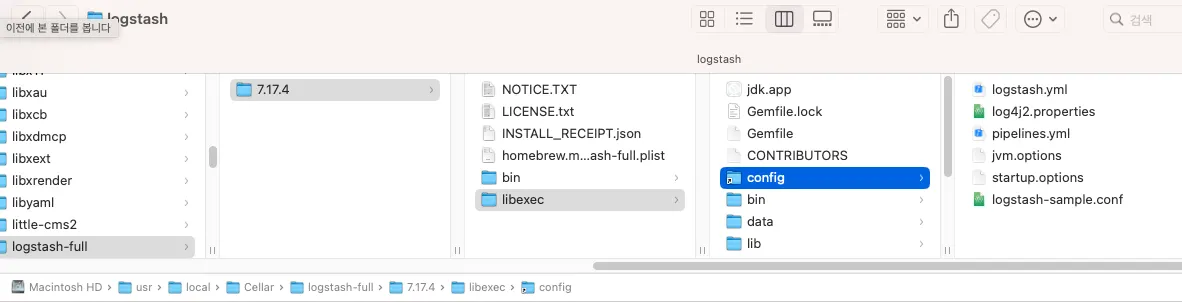
/usr/local/Cellar/logstash-full/7.17.4/libexec/config 이 경로에 conf파일을 생성해준다.
Logstash 설정 파일 작성

[Spring][258] Elasticsearch 검색 성능 개선 05 MySQL→Logstash-Elasticsearch 연결 설정, Heap Space 부족 트러블 슈팅
ELK Stack이란?
우선 ELK Stack이 무엇인지부터 정리하려합니다.
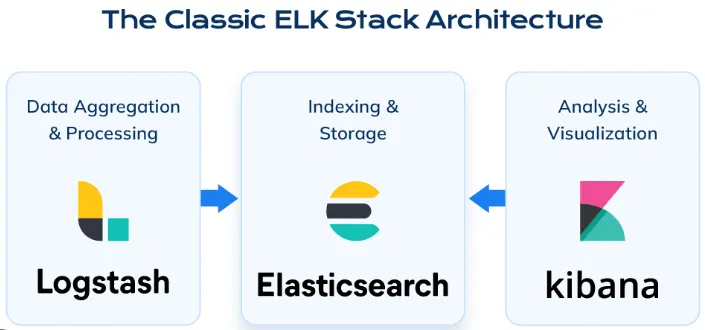
ELK는 위 그림과 같이, 데이터 인덱싱 및 저장 기능을 담당하는 ElasticSearch, 데이터 수집 기능을 하는 Logstash, 이를 분석 및 시각화하는 도구인 Kibana의 앞글자만 딴 단어입니다.
Logstash
•
오픈소스 서버측 데이터 처리 파이프라인으로, 다양한 소스에서 동시에 데이터를 수집하고 변환하여 stash 보관소로 보낸다.
•
수집할 로그를 선정해서, 지정된 대상 서버(ElasticSearch)에 인덱싱하여 전송하는 역할을 담당하는 소프트웨어
ElasticSearch
[Spring][258] Elasticsearch 설치 이후, Logstash와 Kibana 설치 ELK Stack 환경 구축
문제 상황

•
CodeDeploy를 사용하여 소프트웨어 배포 중에 예상치 못한 문제가 발생했습니다.
•
문제의 원인은 appspec.yml 파일의 ApplicationStart 섹션에서 확인되었습니다.
문제 원인 파악
[Spring][258] 트러블 슈팅 : CodeDeploy 배포 중 발생한 sh 파일 생성 오류 해결 사례

Elasticsearch는 무엇인지?
•
Elasticsearch는 검색 및 분석을 위한 오픈 소스 분산 검색 엔진입니다.
•
JSON 형식의 문서를 저장하고, 강력한 검색 및 분석 기능을 제공합니다.
•
분산 환경에서 운영되며, 대용량 데이터를 효율적으로 색인화하고 검색할 수 있습니다.
Elasticsearch를 이해 하기 위한 주요 키워드
•
노드 : 노드는 간단하게 말하면 Elasticsearch가 설치된 각 서버를 의미합니다.
◦
마스터 노드 : 마스터 노드는 클러스터 관리를 담당합니다. 새로운 노드의 가입, 클러스터 내의 노드 상태 모니터링, 인덱스 생성 및 삭제와 같은 관리 작업을 담당합니다. 하지만 데이터를 저장하거나 검색하는 주된 역할을 하는것은 아닙니다.
◦
데이터 노드 : 이름 그대로, 실제로 데이터를 저장하고 검색하는 데 사용됍니다. 이 노드들은 클러스터의 실질적인 작업을 수행하며, 사용자의 요청에 따라 데이터를 처리하고 반환합니다.
◦
서버 하나에 Elasticsearch를 설치하면 마스터노드이기도 하면서 데이터노드이기도 합니다.
◦
만약 두개의 서버에 Elasticsearch를 설치하면 각각 마스터노드-데이터노드가 있게 되는데, 마스터노드끼리 클러스터로 연결되면 1개의 환경으로 간주되며, 마스터노드간의 통신을 통해 클러스터의 일관성을 유지하고 관리합니다.
•
클러스터 : 클러스트는 간단하게 말하면 여러 노드의 집합체라고 볼 수 있습니다. 이들이 함께 작동해서 데이터를 효율적으로 관리하고 검색할 수 있는 환경이 제공됩니다.
◦
마스터 노드간의 연결은 elasticsearch.yml 라는 설정 파일에서 클러스터 환경을 설정하게 됩니다. 아래와 같이 마스터노드1, 마스터노드2가 있다면 my-cluster 라는 동일한 클러스터 환경에 연결 시킬 수 있게 됩니다.
cluster.name: my-cluster
node.name: master-node-1
node.master: true
node.data: true
discovery.seed_hosts: ["master-node-2"]
cluster.initial_master_nodes: ["master-node-1", "master-node-2"]
Shell
복사
[Spring][258] Elasticsearch란?
문제 상황
웹 서비스 구성
카프카 서버를 사용하는 서비스에서 메인 서버와 트래픽 서버가 각각 2개씩 존재합니다.
메인 서버에서는 프로듀서를 통해 메시지를 보내고, 트래픽 서버에서는 컨슈머를 사용해 메시지를 받아 비즈니스 로직을 처리한 후 다시 프로듀서로 결과를 보냅니다.
메인 서버에서는 비동기 처리로 결과를 받아 클라이언트에게 뷰를 반환합니다.
서버와 토픽의 파티션을 확장한 후에 메시지 처리에 문제가 발생했습니다.
메인 서버1에서 트래픽 서버1로 데이터를 보냈을 때, 결과를 메인 서버1 쪽으로 전달하지 못하는 문제를 파악했습니다.
문제 원인
모든 메인 서버와 트래픽 서버의 컨슈머가 같은 컨슈머 그룹에 속해 있었기 때문에, 파티션 할당이 제대로 이루어지지 않았습니다.
카프카는 컨슈머 그룹 내에서 라운드 로빈 방식으로 파티션을 할당하는데, 이 때 메시지의 키와 파티션 할당 로직이 올바르게 설정되지 않아 잘못된 컨슈머에게 메시지가 전달되는 문제가 발생했습니다.
해결
각 메인 서버의 컨슈머가 서로 다른 컨슈머 그룹에 속하도록 설정을 변경했습니다.
메인 서버1의 컨슈머는 "main-server-apply-consumer-group"에, 메인 서버2의 컨슈머는 "main-server-apply-consumer-group2"에 속하도록 설정을 변경함으로써 각 서버의 컨슈머가 올바른 파티션에 할당되어 메시지를 정확히 처리할 수 있게 되었습니다.
또한 메시지 키와 파티션 할당 로직을 검토하여 올바르게 설정함으로써 앞으로 이러한 문제가 재발하지 않도록 예방했습니다.
[Spring][258] 트러블 슈팅 : 카프카 컨슈머 그룹 설정 오류로 인한 메시지 처리 문제
Elasticsearch를 활용한 성능개선을 위해서 진행해 볼 순서를 정리해보았다.
1.
Elasticsearch 설치
2.
도서 데이터를 Elasticsearch에 넣고 JMeter로 테스트해보기
3.
MySQL과 Elasticsearch의 성능 차이점 비교하기
4.
Beats 를 추가해보고 JMeter로 테스트해보기
5.
이전과 차이점 비교하기
6.
Logstash 추가해보고 JMeter로 테스트해보기
7.
이전과 차이점 비교하기
8.
Kibana 추가해보기
9.
JMeter 결과와 Kibana 대쉬보드의 차이점, Kibana가 제공해주는 것들 정리해보기
10.
위 ELKB 스택을 로컬이 아닌 Docker에 구현해보기
11.
환경 구성 방법의 차이를 확인해보기

[Spring][258] Elasticsearch 검색 성능 개선 02 - Elasticsearch 활용해보기 순서 정리
Apache Kafka는 대용량의 실시간 데이터 스트림 처리를 위한 분산 메시징 시스템입니다.
Kafka를 통해 서버 간 비동기 통신을 구현하고, 대량의 데이터를 빠르고 안정적으로 처리할 수 있습니다.
Kafka 메시지 처리의 기본 흐름
1.
메시지 생성 및 전송
프로듀서는 메시지를 생성하고 이를 Kafka 토픽의 특정 파티션에 전송합니다.
메시지는 correlationId 같은 식별 정보를 포함하고 있어, 나중에 처리 결과를 정확히 매칭할 수 있습니다.


2.
메시지 저장
Kafka 서버는 받은 메시지를 파티션에 저장합니다.

[Spring][258] Kafka에서의 효율적인 메시지 처리: 컨슈머 그룹 ID의 활용
Elasticsearch 로컬 Homebrew를 통한 설치 명령어
Elasticsearch를 사용해보기 위해 로컬 환경에 설치부터 진행합니다. MacOS도 윈도우와 마찬가지로 간단히 tar.gz를 다운로드를 받아서 설치해도 되지만 현재 로컬의 JDK부터 MySQL까지 Homebrew를 통한 CLI 환경에 설치해왔기 때문에 통일성있는 관리를 위하여 brew로 설치하고자 합니다.
Elastic 기술 스택 관련 설치 방법은 을 통해 접근했으며, README.md를 통해 설치 방법과 관련된 명령어들을 확인 할 수 있습니다.
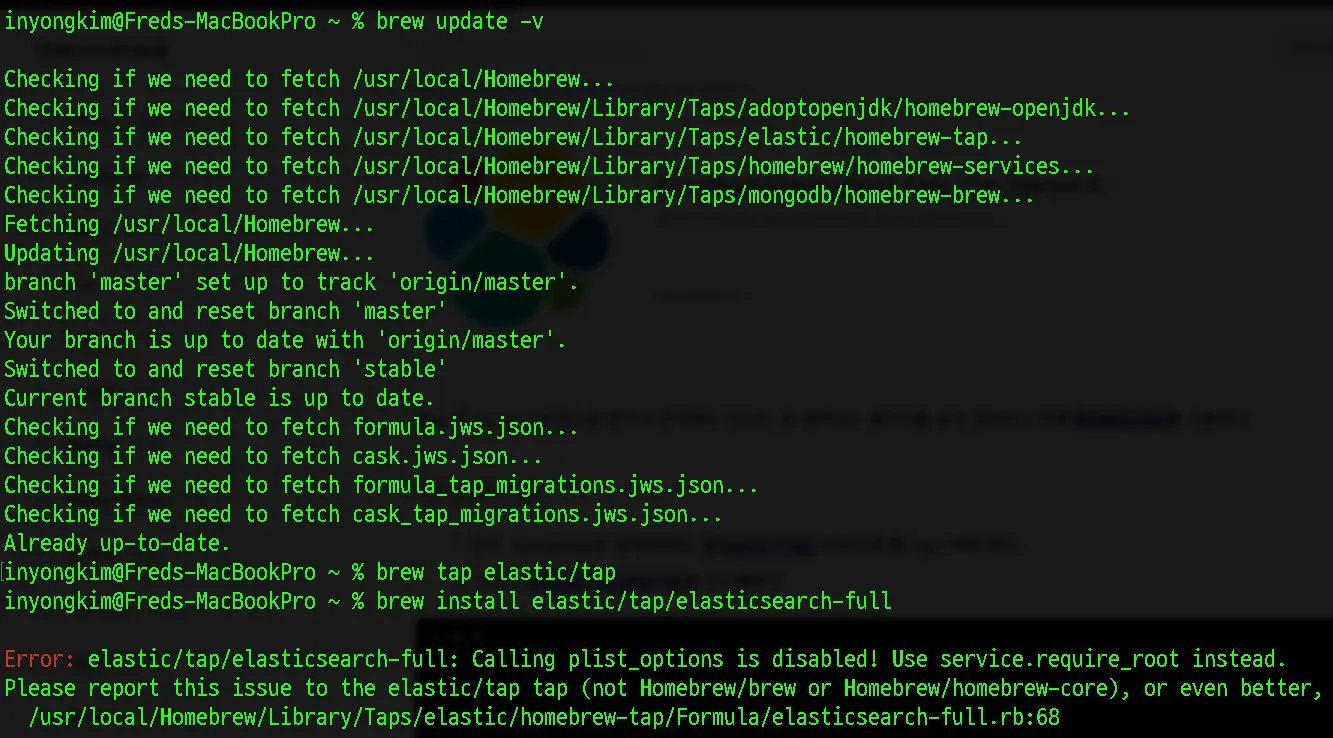
[Spring][258] Elasticsearch 사용을 위한 로컬 환경 구축 기본
문제 상황

웹서비스를 그룹 ID를 다르게 설정하여 각 서버에 배포하려 하던 도중에 문제가 발생 하였습니다.

위 처럼 환경변수로 GROUP_ID를 설정하였지만 여전히 Ec2의 서버에서는 여전히 문제가 발생하엿습니다.
[Spring][258] 트러블 슈팅 : AWS CodeDeploy를 이용한 웹서비스 배포 중 환경 변수 문제
Elasticsearch 로컬 Homebrew를 통한 설치 명령어
Elasticsearch를 사용해보기 위해 로컬 환경에 설치부터 진행합니다. MacOS도 윈도우와 마찬가지로 간단히 tar.gz를 다운로드를 받아서 설치해도 되지만 현재 로컬의 JDK부터 MySQL까지 Homebrew를 통한 CLI 환경에 설치해왔기 때문에 통일성있는 관리를 위하여 brew로 설치하고자 합니다.
Elastic 기술 스택 관련 설치 방법은 을 통해 접근했으며, README.md를 통해 설치 방법과 관련된 명령어들을 확인 할 수 있습니다.

[Spring][258] Elasticsearch 검색 성능 개선 03 - Elasticsearch 설치와 테스트 실행 및 설치과정 사소한 트러블슈팅

Elasticsearch는 무엇인지?
•
Elasticsearch는 검색 및 분석을 위한 오픈 소스 분산 검색 엔진입니다.
•
JSON 형식의 문서를 저장하고, 강력한 검색 및 분석 기능을 제공합니다.
•
분산 환경에서 운영되며, 대용량 데이터를 효율적으로 색인화하고 검색할 수 있습니다.
Elasticsearch를 이해 하기 위한 주요 키워드
•
노드 : 노드는 간단하게 말하면 Elasticsearch가 설치된 각 서버를 의미합니다.
◦
마스터 노드 : 마스터 노드는 클러스터 관리를 담당합니다. 새로운 노드의 가입, 클러스터 내의 노드 상태 모니터링, 인덱스 생성 및 삭제와 같은 관리 작업을 담당합니다. 하지만 데이터를 저장하거나 검색하는 주된 역할을 하는것은 아닙니다.
◦
데이터 노드 : 이름 그대로, 실제로 데이터를 저장하고 검색하는 데 사용됍니다. 이 노드들은 클러스터의 실질적인 작업을 수행하며, 사용자의 요청에 따라 데이터를 처리하고 반환합니다.
◦
서버 하나에 Elasticsearch를 설치하면 마스터노드이기도 하면서 데이터노드이기도 합니다.
◦
만약 두개의 서버에 Elasticsearch를 설치하면 각각 마스터노드-데이터노드가 있게 되는데, 마스터노드끼리 클러스터로 연결되면 1개의 환경으로 간주되며, 마스터노드간의 통신을 통해 클러스터의 일관성을 유지하고 관리합니다.
•
클러스터 : 클러스트는 간단하게 말하면 여러 노드의 집합체라고 볼 수 있습니다. 이들이 함께 작동해서 데이터를 효율적으로 관리하고 검색할 수 있는 환경이 제공됩니다.
◦
마스터 노드간의 연결은 elasticsearch.yml 라는 설정 파일에서 클러스터 환경을 설정하게 됩니다. 아래와 같이 마스터노드1, 마스터노드2가 있다면 my-cluster 라는 동일한 클러스터 환경에 연결 시킬 수 있게 됩니다.
cluster.name: my-cluster
node.name: master-node-1
node.master: true
node.data: true
discovery.seed_hosts: ["master-node-2"]
cluster.initial_master_nodes: ["master-node-1", "master-node-2"]
Shell
복사

[Spring][258] Elasticsearch 검색 성능 개선 01 - Elasticsearch란?
시작 전에 점검
토픽 점검

main Server 카프카 정상 할당 점검

traffic Server 카프카 정상 할당 점검

웹 서비스 정상 동작 확인
[Spring][258] CI/CD AWS Ec2 서버 다중 배포
1. 개요
기부된 책을 신청하는 과정에서 N+1 문제가 발생하였다.
N+1이 발생하지 않도록 코드를 수정하고 Jmeter로 성능테스트를 하여 결과를 비교하고자 한다.
2. N+1 발생 상황
기부된 책을 신청하는 로직은 아래와 같다.
책 신청 요청을 보내면 아래와 같이 N+1 문제가 발생한다.

[Spring][258] BookApplyDonation에서의 N+1 문제 해결 및 성능 테스트
문제 상황

SSH를 통해 AWS EC2 인스턴스에 연결을 시도할 때, team258serverkey.pem 파일의 권한이 너무 개방적으로 설정되어 있어서 연결이 거부되는 문제가 발생하였습니다.
문제 해결 과정
[Spring][258] 트러블 슈팅 : SSH 키 파일 권한 문제로 인한 연결 실패
문제 상황

카프카 컨슈머가 대상 토픽에 대한 파티션을 할당 받지 못하여 정상 동작하지 못하는 문제가 발생했습니다.
문제 원인 분석
[Spring][258] 트러블 슈팅 : 컨슈머 서버가 카프카 서버 토픽의 파티션을 할당 받지 못하는 문제
초기에 Kafka를 도입할 때 Kafka의 구조와 특성으로 동시성 문제를 자연스럽게 해결할 수 있을 것이라 기대하였습니다.
Kafka는 메시지를 파티션 단위로 관리하며, 각 파티션은 순서를 가진 로그로 구성되어 있습니다.
따라서 단일 파티션에 대해서는 프로듀서와 컨슈머 간의 동시성 문제가 크게 발생하지 않습니다
그러나 Kafka 환경이 확장되면서 여러 파티션이 생성되고, 각각의 파티션에 대해 병렬 처리가 필요해지기 시작하면서 동시성 문제가 구조적으로 해결되지 않는다는 것을 알게 되었습니다.
각각의 파티션에 대해 독립적으로 메시지를 처리하지만, 전체 시스템의 관점에서 보면 동시에 여러 작업이 이루어지기 때문에 동시성 문제가 발생할 수 있기 때문입니다
이러한 문제를 해결하기 위해 방법을 찾던 도중 분산 락이라는 것을 알게 되었습니다.
redis나 ZooKeeper와 같은 분산 락 서비스를 사용하여 리소스에 대한 접근을 제어함으로써 동시성 문제를 해결할 수 있을 것으로 추정됩니다.
여러 컨슈머가 동일한 리소스에 접근해야 하는 상황에서 ZooKeeper를 사용하여 분산 락을 구현함으로써, 한 번에 하나의 컨슈머만이 리소스에 접근할 수 있도록 제어하는 방향으로 말입니다.
결론적으로 Kafka를 통한 분산 처리와 함께 분산 락을 적절히 사용함으로써, 데이터베이스 락에서 발생할 수 있는 데드락의 위험을 줄이면서 동시성 문제를 해결하는 방향으로 진행할려구 합니다.
[Spring][258] Kafka를 활용한 분산 처리 환경에서의 동시성 문제 해결을 위한 고찰
1. 개요
팀 프로젝트를 진행하며 동시성 문제를 해결하기 위해 다양한 방법들을 사용해 보았으며
이 방법들을 모두 포함한 프로젝트를 AWS를 이용한 서버에 올려서 구동하였다.
서버에서 동시성 부하 테스트를 진행하며 성능을 측정해보았다.
2. 테스트 환경
메인서버 : t2.micro(??)
트래픽(카프카) 서버 : t2.micro(??)
카프카서버 : t3.small(??)
RDS서버 : t2.micro(??) MySQL
테스트는 카프카,뮤텍스,세마포어,비관적락, Transactional Serializable 5가지로 진행하였으며
각각 0.1초동안 100개 쓰레드에서 같은 요청을 보내는 테스트를 10번 진행하였다.
초기 테스트 수행시 속도가 느리게 측정되는 현상이 있어 10번 중 앞의 4개 시행은 버리고 6개 시행을 기록하였고
6개 시행의 평균값들의 평균을 작성하였다.
3. 테스트 결과
구분 | bookDonation 평균값 | 시행 | 표본수 | 평균 | 중간값 | 90% | 95% | 99% | 최소값 | 최대값 | 오류 |
1. 카프카 | 749.2 | 1 | 100 | 780 | 767 | 1020 | 1043 | 1072 | 485 | 1080 | 0 |
2 | 100 | 737 | 734 | 987 | 1011 | 1042 | 416 | 1047 | 0 | ||
3 | 100 | 744 | 744 | 965 | 995 | 1016 | 472 | 1021 | 0 | ||
4 | 100 | 725 | 729 | 955 | 977 | 998 | 417 | 1007 | 0 | ||
5 | 100 | 763 | 765 | 978 | 1010 | 1028 | 471 | 1034 | 0 | ||
6 | 100 | 746 | 748 | 960 | 985 | 1007 | 335 | 1012 | 0 | ||
2. 뮤텍스 | 563.2 | 1 | 100 | 568 | 569 | 796 | 836 | 848 | 251 | 851 | 0 |
2 | 100 | 630 | 652 | 900 | 923 | 948 | 264 | 953 | 0 | ||
3 | 100 | 555 | 552 | 771 | 795 | 829 | 287 | 830 | 0 | ||
4 | 100 | 538 | 531 | 767 | 791 | 816 | 257 | 825 | 0 | ||
5 | 100 | 536 | 536 | 748 | 780 | 805 | 257 | 810 | 0 | ||
6 | 100 | 552 | 555 | 784 | 806 | 836 | 256 | 837 | 0 | ||
3. 세마포어 | 613.2 | 1 | 100 | 791 | 789 | 1014 | 1041 | 1061 | 513 | 1070 | 0 |
2 | 100 | 535 | 531 | 749 | 779 | 796 | 277 | 802 | 0 | ||
3 | 100 | 542 | 539 | 763 | 782 | 806 | 278 | 813 | 0 | ||
4 | 100 | 632 | 627 | 877 | 910 | 940 | 346 | 945 | 0 | ||
5 | 100 | 579 | 575 | 809 | 840 | 865 | 277 | 876 | 0 | ||
6 | 100 | 600 | 592 | 813 | 851 | 874 | 331 | 876 | 0 | ||
4. 비관적락 | 412.2 | 1 | 100 | 442 | 438 | 565 | 574 | 581 | 301 | 584 | 0 |
2 | 100 | 428 | 425 | 549 | 566 | 571 | 281 | 572 | 0 | ||
3 | 100 | 422 | 428 | 536 | 546 | 550 | 261 | 551 | 0 | ||
4 | 100 | 383 | 381 | 495 | 507 | 512 | 248 | 512 | 0 | ||
5 | 100 | 386 | 388 | 489 | 496 | 499 | 248 | 505 | 0 | ||
6 | 100 | 394 | 390 | 498 | 504 | 511 | 268 | 512 | 0 | ||
5. Transactional Serializable | 451.8 | 1 | 100 | 482 | 473 | 570 | 631 | 644 | 362 | 648 | 0.09 |
2 | 100 | 470 | 465 | 557 | 593 | 621 | 352 | 625 | 0.11 | ||
3 | 100 | 440 | 425 | 550 | 571 | 578 | 320 | 587 | 0.13 | ||
4 | 100 | 422 | 418 | 494 | 545 | 562 | 310 | 567 | 0.1 | ||
5 | 100 | 456 | 434 | 512 | 556 | 601 | 323 | 603 | 0.1 | ||
6 | 100 | 441 | 466 | 536 | 589 | 597 | 340 | 611 | 0.12 |
[Spring][258] 동시성 해결 기법들 Jmeter 부하 성능 테스트
1. 문제
현재 작업중인 프로젝트에서
뷰 페이지에 들어갈 때마다 username으로 user를 찾는 쿼리가 마지막에 2번 추가로 날아가는 현상이 발견됨

근데 또 로그인을 하지 않은 상태에서 뷰페이지에 접근하면 username쿼리가 날라가지 않는다

2. 원인
[Spring][258] 뷰페이지 접속시 user쿼리 추가로 2번 발생하는 문제 해결
문제 상황


Kafka 서버로 프로듀서가 데이터를 전송하는 것은 성공하였으나
Kafka 리스너가 Kafka 서버에서 데이터를 읽지 못하는 상황이 발생했습니다.
이 문제는 @KafkaListener 애노테이션을 사용하여 Kafka 메시지를 수신하는 Spring Boot 어플리케이션에서 나타났습니다.
문제 분석
[Spring][258] 트러블 슈팅 : Kafka 리스너(컨슈머)가 Kafka 서버에서 데이터를 읽지 못하는 문제 발생 및 해결
무한 스크롤 구현 모습

무한 스크롤의 필요성
더보기 기능을 구현하면서 기본 페이징보다 상당히 뛰어난 사용자 경험을 상승 시키는 효과를 만들 수 있었습니다. 여기서 더욱 사용자의 상호작용을 고려하여 무한 스크롤을 통해 더보기의 자동화를 진행하고자 했습니다. 따라서 무한 스크롤은 더보기 기능의 또 다른 확장판으로 생각 할 수 있습니다.
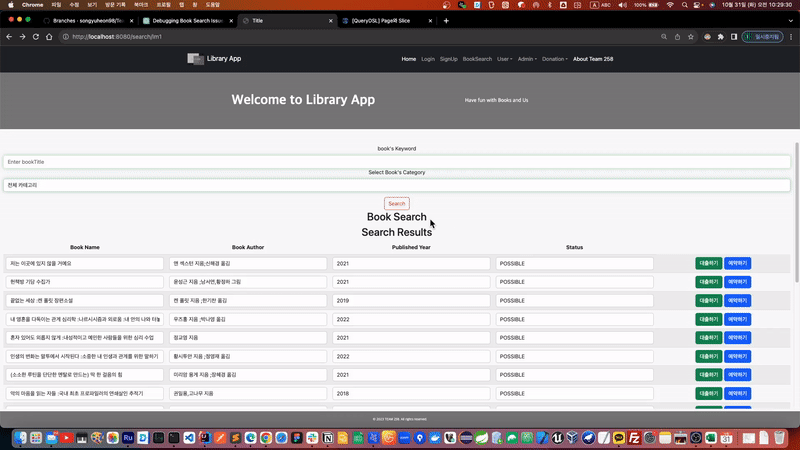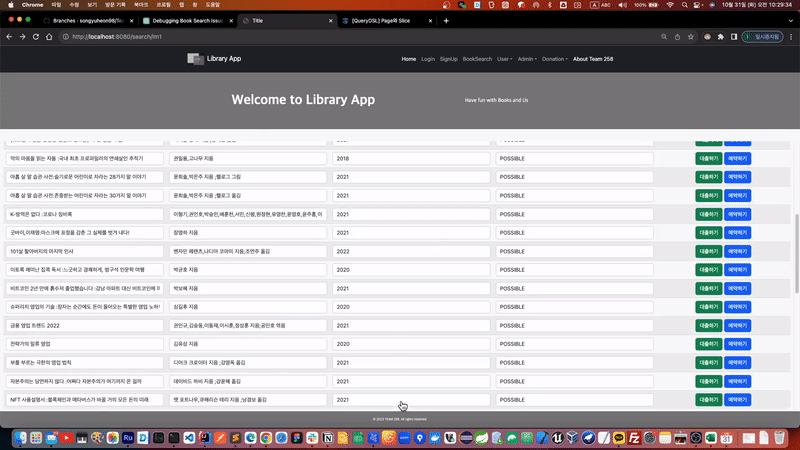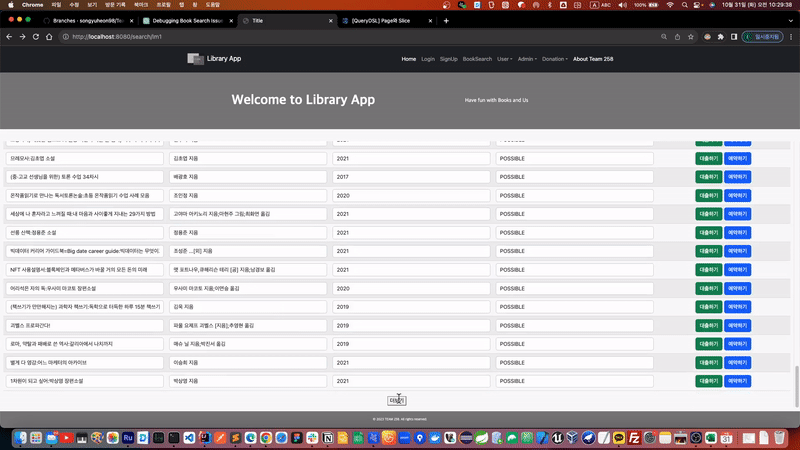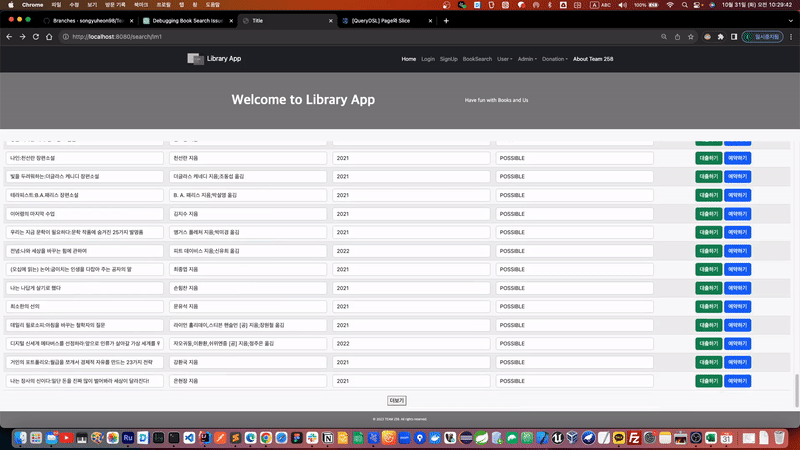
우선 더보기 기능으로 페이징 자체의 원활한 기능적 목적을 달성하는데에는 Slice 인터페이스의 역할이 큽니다. 이번 무한 스크롤을 구현하는데 있어서도 최적화 된 구현체로 활용됩니다.
무한 스크롤은 다음에 조회할 페이지가 있는지 내부적으로 체크한 다음, 클라이언트에게 다음 페이지 여부를 알려주는 방식으로 구현할 수 있습니다.
[Spring][258] 무한스크롤(Infinity Scroll) 기능 구현
[Spring][258] Pagenation→Slice→LoadMore→InfinityScroll 변화로 보는 성능 및 사용자경험의 선택과정
전체 프로그램 구조
현재 아직은 AWS에 배포하지 않은 상태입니다.
배포 전 카프카 테스트를 위해 아래의 구조에서 로드 밸런서 없이 main Server ( Localhost:8080 ), Traffic Server ( Localhost:8090 ), Kafka Server ( AWS Ec2 ) 구조로 테스트 하였습니다.

AWS EC2 생성 및 설정
[Spring][258] EC2 Kafka 서버 적용 ( 테스트 환경 : 로컬 )
개요
문화빅데이터포털에서 공공도서관 소장도서 목록을 csv 파일들로 받아 정리하고
서적분류코드를 BookCategory로 정리하여
DB에 삽입한 과정을 작성하였다.
1. Book 데이터 다운로드 및 가공
문화빅데이터 플랫폼에서 공공도서관 소장도서 목록을 다운로드하였다.
22년 3월도 데이터를 다운받았으며 csv 파일 10개 가량이다.
팀원분이 파이썬을 이용하여 필요한 데이터셋(저자, 출판년도, 책이름, 분류기호) 만 추출하고 중복을 제거하였다.
2. BookCategory 작성
Book 데이터에서 책의 도서분류코드는 ex) 812.43 이런식으로 구성되어있다. 백의자리와 십의자리만을 포함한 810이 이 책의 십진분류표상 도서분류이고 분류는 아래와 같다.

순서대로 000 총류 -> id 1, 010 도서학 --> id 2 .... 로 DB에 삽입할 수 있도록 csv 파일을 작성하였다.
3. MySql 삽입
local infile 기능을 사용해 MYsql에 위에서 작성한 Book, BookCategory 데이터를 삽입하였다.
[Spring][258] bookData 가공 및 bookCategory MySQL 삽입
더보기 기능의 구현 모습

불편함으로 부터 시작
웹 서비스에서 페이징은 아주 흔하게 사용되는 기능입니다. 다만, 기초적인 페이징 구현 방식은 서비스가 커짐에 따라 큰 장애를 유발할 수 있는데요.
서비스 초기에는 수천 ~ 수십만건정도로 데이터가 적어서 큰 문제가 없지만, 점차 적재된 데이터가 많아짐에 따라 페이징 기능이 수십초 ~ 수분까지 조회가 느려지는걸 경험하게 됩니다.
실제로 도서 목록이 나타나는 저희 프로젝트에서도 기본적인 페이징을 구현했었습니다. 하지만 각 페이지를 이동 할 때마다 약 1.0~1.2초가 소요될 정도로 “느리다”, “원활하지 않다” 라는 점을 직접 체감 할 수 있었습니다.
[Spring][258] 더보기(No Offset) 기능 구현
프로젝트에 수백만 건의 데이터를 불러오는 페이지가 있다. 그런데 이 모든 데이터를 불러오면 속도도 느리고 사용자 입장에서 이를 보는 경험도 좋지 않다. 그래서 일반적으로는 데이터를 불러올 때 일부만 불러오는 것이 일반적이다. 스프링에서는 Slice와 Page를 통해 이를 구현할 수 있다.
Page
JPA에서 데이터를 호출하면 Pageable을 기준으로 List를 생성하여 그 양식에 맞게 데이터를 저장한다. 데이터를 호출할 때 Pageable이라는 인스턴스를 생성해 입력해 주는데, Pageable에는 페이지 번호, 페이지 크기, 그리고 정렬 기준과 순서의 데이터를 갖는 Sort라는 객체를 필드로 갖는다.
Pageable을 통해 데이터를 호출하면, 전체 데이터를 PageSize만큼 자른 후, PageNumber번째의 데이터들을 불러오게 된다. PageNumber는 0부터 시작하여 순차적으로 올라가게 된다.
Page 객체를 통해 데이터를 불러오는 경우, 총 데이터 갯수를 함께 저장하여 총 Page 수를 계산하게 된다.
프로젝트에서 Page를 사용해 Book데이터를 구현하였다.

전체 데이터 중 20개만 호출하는 결과를 볼 수 있다.
데이터를 불러오는 Query문과 전체 데이터의 크기를 불러오는 쿼리 총 두 번의 쿼리를 실행한다. 단순히 전체 데이터 중 상위 20개만 호출하는 코드임에도 소요시간이 상당했는데, 시간 소요 중 대부분은 전체 데이터의 갯수를 호출하는 데에 사용되었다.
Slice
Slice는 Page에서 total 필드 대신 hasNext 필드가 존재한다. 전체 데이터의 크기를 불러오는 대신, 불러온 데이터 다음의 데이터가 있는지 없는지만 판별하여 hasNext에 저장한다. 실제 코드로는 Page가 Slice를 확장시켜 만든 개념이다.
[Spring][258] Page와 Slice를 통한 데이터 호출 제어
[Spring][258] Kafka 적용한 서버 구조 변경
우선 코드를 변경하기 전에 전체적인 적용할려는 시스템의 로직을 파악하자

초록을 프로듀서 연파랑을 컨슈머로 하면 되지 않을까?
전체적으로 적용을 위한 구조를 작성해 보았다.

카프카 설정
Front Kafka Config
[Spring][258] 프로젝트에 Kafka 서비스 적용

고찰
책 나눔 신청 서비스에 Kafka를 적용할려구 합니다
하지만 그 설정하는 과정에서 약간의 고민이 생겼습니다.
기존 그룹과 같은 그룹 ID로 설정할지 아니면 새로운 그룹을 만들지...
Kafka를 사용하는 ‘유저 관리 페이지 로딩’ 서비스는 부하가 상대적으로 작습니다.
반면에, 추가될 ‘책 나눔 신청’ 서비스는 훨씬 더 많은 부하를 발생시킬 것으로 예상됩니다.
이 두 서비스의 부하 차이를 고려할 때, group.id를 분리하여 각 서비스를 독립적으로 관리하는 것이 합리적이지 않을까? 라는 생각이 들었습니다.
[Spring][258] Kafka Consumer Group 설정에 대한 고찰
문제 상황
Java의 LocalDateTime 타입을 사용하여 개발을 진행하는 과정에서, JSON 변환을 담당하는 Jackson 라이브러리가 LocalDateTime 타입을 올바르게 처리하지 못하는 문제가 발생하였습니다.
구체적으로는 BookApplyDonationRequestDto 클래스의 applyDate 필드를 JSON 문자열로 변환하려고 했을 때, 아래 이미지와 같은 에러 메시지가 발생했습니다.

원인 분석
[Spring][258] 트러블 슈팅 : Jackson 라이브러리와 LocalDateTime 타입 처리 문제 해결
기존 프로젝트에 카프카 적용 할려던 구조

기존에 생각했던 프로젝트의 구조는 크게 세 부분으로 구성되어 있습니다.
사용자의 요청은 클라이언트 서버를 통해 이루어지고, 이후 카프카 서버를 통해 데이터가 전송되어 백엔드 서버에서 처리됩니다.
처리된 결과는 다시 카프카를 통해 클라이언트 서버로 전송되어 최종적으로 사용자에게 뷰를 반환합니다.
문제 인식 및 고찰
[Spring][258] Kafka를 활용한 실시간 데이터 처리: 시스템 구조 및 개선 방향 고찰
문제 상황

Spring Kafka를 사용하여 메시지를 송수신하는 과정에서 org.springframework.kafka.KafkaException: Seek to current after exception 오류가 발생하였습니다.
이 오류는 Kafka 컨슈머가 메시지를 정상적으로 처리하지 못했을 때 발생합니다.
문제 상황 분석
[Spring][258] 트러블 슈팅 : Spring Kafka를 사용하여 메시지를 송수신하는 과정에서 org.springframework.kafka.KafkaException: Seek to current after exception 오류가 발생

데이터 통신과 메시지 큐를 사용한 비동기 처리는 현대 웹 서비스에서 중요한 역할을 담당하고 있습니다고 생각합니다.
그중에서도 Apache Kafka는 그 뛰어난 처리 능력과 확장성으로 많은 개발자들에게 선택받고 있습니다.
하지만 모든 서비스에 무조건적으로 Kafka를 적용하는 것이 정말 효율적인 방법일지 프로젝트를 진행하며 의문을 가지게 되었습니다.
Kafka 적용의 고민
모든 서비스에 Kafka를 적용한다면 간단한 작업조차도 Kafka를 거쳐야 하므로 이는 사용자에게 제공되는 전체적인 서비스의 리소스를 낭비할 수 있습니다고 생각됩니다.
특히 간단한 로직이나 데이터 처리에 Kafka를 사용하는 것은 오버헤드를 증가시켜 결국 시스템의 성능 저하를 초래할 수 있습니다.
그래서 생각이 난 접근 방법은, 대용량 트래픽을 처리하는 서비스와 간단한 서비스를 구분하여 처리하는 것입니다.
예를 들어 프론트 서버에서 대용량 트래픽 요청을 처리하는 서비스는 Kafka를 통해 비동기적으로 처리하고, 간단한 로직이나 서비스는 프론트 서버에서 직접 처리하도록 하는 것입니다.
[Spring][258] 카프카 적용의 적정선: 효율적인 시스템 구조 설계를 위한 고찰
문제 상황
Kafka Consumer 서비스가 bookDonationEventApplyOutput 토픽으로부터 메시지를 받아 처리하는 도중 List<UserResponseDto> 타입으로의 변환 과정에서 ListenerExecutionFailedException 오류가 발생하였습니다.
이 오류는 Kafka 리스너 메서드 실행 중 예외가 발생했음을 나타냅니다.
문제 분석

[Spring][258] 트러블 슈팅 : Kafka Consumer 서비스가 `bookDonationEventApplyOutput` 토픽으로부터 메시지를 받아 처리하는 도중 `List<UserResponseDto>` 타입으로의 변환 과정에서 `ListenerExecutionFailedException` 오류가 발생
Q. 문제 이번주부터 성능 개선에 대한 진행 방법과 진지하게 고민해보고 있습니다. 문제 해결하는 과정을 아래와 같은 방식으로 스토리를 정리해나가면 될까요?
문제상황 → 해결방안 → 의견조율 → 의견결정 → 비교 결과들 수집과 정리..
문제상황)
기획 당시 검색 기능과 페이지 기능 개선이 가장 중요한 토픽이 될 것으로 예측했었습니다.
현재 MVP 구현 단계에서는 실제 운영되고 있는 서비스들과 비교했을때 사용자가 불편함을 느낄 수 있을 수준으로 성능에 이상이 있음을 느끼고 있습니다.
(좀 더 구체적이여야 하는지?)
해결방안)
기본적으로 저희가 할 수 있는 방안 탐색은 구글링, 타 프로젝트 레퍼런스 체크 정도가 맞는지.
저희가 하고있는 수준은 구글링, ChatGPT를 통한 키워드를 최대한 탐색하고 적용할 수 있는 기술스택이나 라이브러리가 어떤것이 있는지 찾고 있습니다.
의견조율)
팀적으로 회의를 통해서 위 내용에 대해서 공유하면서 적절한 기술스택인지를 판단해봅니다. 기본적으로 경험자가 없기때문에 사실 이 부분의 신뢰도가 부족합니다. 더 많은 자료를 탐색해보는 것이 해답인지 궁금합니다.
의견결정)
어떠한 개선사항 토픽 하나에 대해 몇가지 기술 스택을 사용해보자는 의견이 모였다면,
예로 검색기능 개선에서는 아래와 같은 의견들을 모을 수 있었습니다.
 [Spring][258] 검색관련 문제해결 및 성능 개선 방안 수집
업무 분담은 어떤식으로 하는 것이 효율적이고 팀전체가 성능개선에 참여한 느낌을 줄지 궁금합니다.
팀원이 모두 각자 적용해보고 비교해보는 것은 뭔가 팀적인 움직임이 아닌것 같은 느낌입니다. 모두가 동일한것을 해보니 실력적인 향상은 가장 좋을 것 같지만 마치 그냥 동일한 프로젝트를 개인프로젝트처럼 진행하는 느낌일 것 같습니다..
아니면 일관성을 유지하기 위해서 전체 토픽을 맡아서 진행해보는게 맞는지
아니면 제가 구분해 둔 중간 토픽 정도로 분담하는것이 좋을지
[Spring][258] 검색관련 문제해결 및 성능 개선 방안 수집
업무 분담은 어떤식으로 하는 것이 효율적이고 팀전체가 성능개선에 참여한 느낌을 줄지 궁금합니다.
팀원이 모두 각자 적용해보고 비교해보는 것은 뭔가 팀적인 움직임이 아닌것 같은 느낌입니다. 모두가 동일한것을 해보니 실력적인 향상은 가장 좋을 것 같지만 마치 그냥 동일한 프로젝트를 개인프로젝트처럼 진행하는 느낌일 것 같습니다..
아니면 일관성을 유지하기 위해서 전체 토픽을 맡아서 진행해보는게 맞는지
아니면 제가 구분해 둔 중간 토픽 정도로 분담하는것이 좋을지
[Spring][258] 검색관련 문제해결 및 성능 개선 방안 수집
업무 분담은 어떤식으로 하는 것이 효율적이고 팀전체가 성능개선에 참여한 느낌을 줄지 궁금합니다.
팀원이 모두 각자 적용해보고 비교해보는 것은 뭔가 팀적인 움직임이 아닌것 같은 느낌입니다. 모두가 동일한것을 해보니 실력적인 향상은 가장 좋을 것 같지만 마치 그냥 동일한 프로젝트를 개인프로젝트처럼 진행하는 느낌일 것 같습니다..
아니면 일관성을 유지하기 위해서 전체 토픽을 맡아서 진행해보는게 맞는지
아니면 제가 구분해 둔 중간 토픽 정도로 분담하는것이 좋을지
A. 멘토님답변정리!
팀적으로 회의를 통해서 위 내용에 대해서 공유하면서 적절한 기술스택인지를 판단해봅니다. 기본적으로 경험자가 없기때문에 사실 이 부분의 신뢰도가 부족합니다. 더 많은 자료를 탐색해보는 것이 해답인지 궁금합니다.
현재상황에서는 교차체크가 현실적이고 그중에 정확한 방법일 것이므로 좋다.
현재 상황에서는 위 방법을 선택해야 하고,
추후에
CS, OS, Network, Data Structure, Algorithm 등 심화 공부를 통해서 아이디어를 획득 할 수 있다.
→ 어려운 문제, 상황을 해결할 키가 다르기 때문에, 계속해서 꾸준히 공부해야 한다.
그 중에 우선순위는 Data Structure , Algorithm 을 공부해보면 이런 문제 해결의 아이디어를 제공 할 수 있는 기본기를 쌓아 나갈 수 있다. https://www.yes24.com/Product/Goods/122445610 이것 같은 책들을 찾아보자.
A. 멘토님답변정리!
업무 분담은 어떤식으로 하는 것이 효율적이고 팀전체가 성능개선에 참여한 느낌을 줄지 궁금합니다.
현재는 분담하더라도 모든것을 혼자 할 수도 없으며, 모든것을 같이 하는것도 문제가 있다.
결국 팀프로젝트기 때문에 분담해야 하며, 프로젝트가 종료되더라도 다른 팀원의 코드, 기능을 내가 직접 다뤄보고 차이점을 느끼고, 그 선택과정을 살펴볼 필요가 있다.
이러한 프로젝트 복기를 해보면서 장기적으로 나만의 정리를 해보면서 공부해야 한다.
Q. 문제 해결을 위한 많은 기술적 해결 방안들이 있었는데, 블로그든 공식 문서든 각 기술들의 장 단점들을 설명해도 와닿지 않는 부분들이 많아 여러 기술들을 프로젝트에 적용해 보는 것이 좋을 것 같다는 생각이 들었습니다.
프로젝트를 할 때, 각 기술 간의 장 단점을 기준으로 가장 필요한 것을 선택한 후 하나만 적용해 프로젝트 코드를 작성하는 것이 좋을지, 아니면 각 기술별 메소드를 생성해서 일단 코드를 작성해 보는 것이 좋을지 궁금합니다.
또한 프로젝트에서 해당 기술들에 대한 분석을 프로젝트 내에서 끝낸 후에, 분석 과정들을 코드로 남겨두는 것이 좋은지, 그 중 가장 좋다고 판단한 버전을 제외하면 모두 삭제하는 것이 옳은 것인지 궁금합니다.
A. 멘토님답변정리!
기술스택을 써봐야 아는것이기 때문에, 학습과정에서 현재 사용하는것을 우선하는것은 어쩔수없는 선택이고, 틀린 선택이 아니다. 직접 해보는 것이 맞다.
만약 효과가 없더라도, 그것 자체도 경험으로 쌓아두는게 좋다. 실무에서는 데드라인이있기 때문에, 그 실패 경험도 추후 기술 선택에서의 실수를 줄일 수 있는 경험이기 때문에 쌓아두는게 좋다.
과거 코드 및 주석도 우선 모두 남겨놓는게 좋다. 스터디 과정의 프로젝트기 때문에, 브랜치도 삭제할 필요는 없다.
배포 최종본만 가장 깔끔하게 release 태그화 시켜놓을 필요는 있다.
Q. 현재 구현된 책 대출/예약 프로세스는 아래와 같습니다.
대출 : 로그인한 유저가 직접 버튼을 눌러 책을 대출/반납하는 방식
예약 : 대출된 책이 반납되는 즉시 첫번째 예약자가 자동으로 책을 대출
ebook을 대출하는 것이 아니기 때문에 위 방식은 실물 책을 사용하는 도서관 서비스에는 부적합하다고 생각됩니다.
학습용 프로젝트로서 위의 대출/예약 프로세스를 유지해도 상관없는지, 혹은 실제 서비스에 대입 가능하도록 프로세스를 바꿔야 하는지 문의드립니다.
A. 멘토님답변정리!
현재 상태 서비스 프로세스를 유지해도 좋을 것 같다.
서비스가 잘되는것, 최적화하는것도 중요하지만,
우리에게 중요한것은 문제해결을 위한 기술선택, 트러블 슈팅 등 이런 과정을 더 강조하는것이 우선순위가 높다.
Q. 현재 책 나눔 서비스를 제공하는 시스템에서 특정 기간 동안 신청 순서대로 책을 배부하는 구조를 가지고 있습니다.
이 과정에서 하나의 책에 여러명이 신청이 되는 동시성 문제가 발생하였습니다.
이를 해결하기 위해 데이터베이스 수준에서의 락, 애플리케이션 수준에서의 락(세마포어 및 뮤텍스), 혹은 카프카를 통한 구조적 해결 방법이 있다고 조사하였고 현재는 데이터베이스 수준의 락(비관적인 락, 낙관적인 락) 및 애플리케이션 수준에서 락(세마포어 및 뮤텍스)를 구현했습니다.
애플리케이션
또한 현재 카프카를 통해 동시성 문제를 해결하는 것을 시도 중에 있습니다.
현재 진행 중인 대용량 트래픽을 처리하는 프로젝트에서 Kafka를 도입하여 확장성, 탄력성 및 고가용성을 향상시키고자 합니다.
Kafka의 프로듀서와 컨슈머를 분리하여 여러 서버에 배치하는 아키텍처를 고려하고 있습니다. 이와 관련하여, 서버를 세 개로 나누어 프로듀서, Kafka, 컨슈머를 각각 다른 서버에 배치하면 성능 향상 측면에서 이점이 있는지, 아니면 프로듀서와 컨슈머를 같은 서버에 두고 Kafka 서버만 분리하는 것이 더 효율적인지 궁금합니다.
또한, 여러 서버에 걸쳐 비동기적인 작업 처리와 결과 전송을 위해 웹소켓이나 서버 센트 이벤트 등을 사용하는 방법과, 컨슈머가 직접 클라이언트에게 응답을 보내지 않고 프로듀서를 통해 응답을 전달하는 구조 중 어느 쪽이 더 효율적인지, 실무에서는 어떤 방식을 주로 사용하는지에 대한 멘토님의 의견을 듣고 싶습니다.
코드를 재구성하고 새로운 기술을 도입하는 데 있어 난이도와 시간적인 부담이 큰데, 이러한 구조 변경이 성능 향상 측면에서 실질적인 이점을 제공할 수 있는지, 그리고 장기적으로 보았을 때 이러한 아키텍처 변경이 프로젝트에 긍정적인 영향을 미칠 것인지에 대한 멘토님의 경험과 조언을 구하고자 합니다.
A. 멘토님답변정리!
상황에 따른 접근 : 구조변경이나 기술 도입은 서비스에 따라 다를 수 있으므로, 특정 서비스에 맞는 접근 방법을 고려해야 합니다. A, B 사이의 구체적인 상황과 요구사항을 기반으로 결정을 내려야 합니다.
난이도와 시간적인 부담 : 코드를 재구성하고 새로운 기술을 도입하는 과정은 난이도가 높고 시간이 많이 소요될 수 있습니다. 이러한 부담을 감안하여 구조변경이 성능향상 측면에서 실질적인 이점을 제공 하는지 장기적으로 프로젝트에 긍정적인 영향을 미칠지에 대해 충분히 고민해 봐야합니다.
이해도와 오류 해결 : 현재 저희 프로젝트에 대한 구조 이해가 높다면, 구조 변경 과정에서 발생 할 수 있는 중간오류를 우회하거나 해결책을 찾는 데 유리할 것으로 보입니다.
따라서 지금 상황에서는 시도하는 것이 맞다고 조언 하셨습니다.
실패 케이스에 대한 고려 : 구조 변경이 성공 할 수 있지만, 실패할 위험 역시 존재합니다.
실패 케이스에 대한 고민과 준비가 필요하다고 하십니다.
Q. 저희가 챌린지에서 다뤄보고 싶은 성능 개선 토픽은 아래처럼 2개를 목표로 두었습니다.
의견을 여쭤보고 싶습니다.
[Spring][258] 검색관련 문제해결 및 성능 개선 방안 수집
[Spring][258] 동시성 문제 해결 및 성능 개선 방안 수집
[Spring][258] 검색관련 문제해결 및 성능 개선 방안 수집
[Spring][258] 동시성 문제 해결 및 성능 개선 방안 수집 A. 멘토님답변정리!
챌린지 토픽 선정은 적절하며 둘다 풀이하기 어려운 문제들이 맞다.
이번 프로젝트를 통해 잘 접근해보는 것이 좋다.
[Spring][258][3주차 멘토링] 질문내용 정리와 답변
문제 상황

Kafka를 사용하여 데이터를 전송하는 과정에서 프로듀서에서 객체를 직접 전송하려 할 때 역직렬화 문제가 발생하였습니다.
이로 인해 메시지를 정상적으로 처리하지 못하는 상황이 발생하였습니다
원인 분석
[Spring][258] 트러블슈팅 : 프로듀서에서 메시지를 전송하는 과정에서 역직렬화 문제 발생
기존 프로젝트에 카프카 적용 할려던 구조

기존에 생각했던 프로젝트의 구조는 크게 세 부분으로 구성되어 있습니다.
사용자의 요청은 클라이언트 서버를 통해 이루어지고, 이후 카프카 서버를 통해 데이터가 전송되어 백엔드 서버에서 처리됩니다.
처리된 결과는 다시 카프카를 통해 클라이언트 서버로 전송되어 최종적으로 사용자에게 뷰를 반환합니다.
문제 인식 및 고찰
[Spring][258] Kafka를 활용한 실시간 데이터 처리: 시스템 구조 및 개선 방향 고찰
1. Kafka 다운로드 및 설치

1.1 다운로드
•
•
다운로드 받은 kafka_2.13-2.8.0.tgz 파일을 압축 해제하여 폴더로 변환합니다.
1.2 파일 구성 확인
•
kafka_2.12-3.6.0 폴더 안에는 주로 사용할 bin과 config 폴더가 있습니다.
◦
bin/windows 폴더: Zookeeper와 Kafka를 실행 및 종료할 수 있는 배치 파일이 있습니다.
◦
config 폴더: Zookeeper와 Kafka 설정을 담고 있는 설정 파일들이 있습니다.
2. Zookeeper 및 Kafka 실행
[Spring][258] 카프카 기초 구현

Kafka를 시도하는 이유
1.
현재 진행 중인 프로젝트의 서비스는 대용량 트래픽을 받는 서비스이다.
→ kafka를 사용하면 데이터 베이스나 애플리케이션에 락을 걸지 않고 전송 속도를 제어해서 동시성 문제가 발생하지 않는 속도로 순차적으로 전달한다면 락보다 속도가 빠를것입니다.
2.
확장성이 중요한 경우
→ 서비스가 계속 성장하고 더 많은 트래픽을 처리해야 할 경우, Kafka는 쉽게 확장할 수 있는 구조를 가지고 있어 미래의 성장에 대비할 수 있습니다.
3.
탄력성과 고가용성이 중요한 경우
→ Kafka는 분산 시스템으로 설계되어 있어 노드 하나가 실패하더라도 서비스의 가용성을 유지할 수 있습니다.
즉 저희 서비스의 확장성과 안정성, 서버 과부하 방지, 동시성 문제를 성능 저하하는 락없이 해결하기 위해 카프카가 필요합니다.
책나눔서비스
→ 선착순(티켓팅)과 비슷한 서비스
→ 동시성문제가 발생가능성 높다.
→ 해결을 위해 Lock을 사용해보았다.
→ Lock을 사용함으로써 성능 저하 문제가 발생
→ 성능의 차이는 JMeter로 확인했음 →
Lock을 사용하면 평균 222
세마포어를 적용하면 111
2배정도 차이가 발생했다.
[Spring][258] 카프카를 통한 동시성 문제 해결 고민
공통 - Controller, 검색 키워드와 페이징 처리를 위한 페이저블 객체
우선 공통적으로 적용된 컨트롤러 코드는 다음과 같습니다.
프론트엔드로부터 keyword 를 QueryString으로 …?keyword=abc와 같은 형태로 HTML폼으로부터 특정 값들을 추출 할 수 있으며, HTTP요청에 담아 컨트롤러로 문자열을 전달 할 수 있습니다.
페이지 처리를 위해서는 순수 JPA를 사용하게 되면 Total Count를 뽑아와서 현재 내가 몇번째 페이지인지를 계산해서 표시를 해주어야 합니다. 그런데 이런 계산을 모두 직접 계산하는 메소드, 변수를 직접 생성하고 매개변수로 Service에 전달하게 되면 코드가 복잡해지게 됩니다! 페이저블 객체를 사용하지 않는 경우 추가되어야 하는 코드는 다음과 같습니다.
이 복잡한 코드를 해결해주기 위해 스프링 데이터 JPA는 페이징과 정렬을 표준화 해두었습니다.
현재 페이지, 페이지 크기, 정렬 기준, 정렬 방향을 HTTP요청으로 받아오고 pageable 객체를 통해 페이징 처리된 객체를 아래와 같이 생성할 수 있습니다.
keyword, pageable 객체를 Service 계층에 필요한 데이터를 조회(READ)하는 비지니스 로직에 활용 될 수 있도록 매개변수로 전달하게 됩니다.
초기 MVP JPA - Service 계층에서의 구현 상태 코드

[Spring][258] JPA → JPQL → QueryDSL 변화과정
문제 상황



Paging
[Spring][258] 프로젝트 성능 개선 : 대용량 데이터 처리를 위한 페이징에서 슬라이스로의 전환
이전 글에서 우리는 세마포어를 사용하여 동시성 문제를 해결하는 방법을 살펴보았습니다.
그러나 동시성 제어에 대한 탐구는 여기서 그치지 않고, 이번 글에서는 뮤텍스(Mutex)를 활용하여 동시성 문제를 해결해보려고 합니다.
뮤텍스란?
뮤텍스(Mutex)는 여러 스레드가 동시에 공유 자원에 접근하는 것을 막아주는 동기화 메커니즘입니다.
뮤텍스는 한 번에 하나의 스레드만 공유 자원에 접근할 수 있게 하여 데이터의 일관성을 유지할 수 있도록 도와줍니다.
뮤텍스를 사용한 동시성 문제 해결 과정
ReentrantLock을 사용하여 뮤텍스를 구현하였습니다.
lock() 메소드를 호출함으로써 자원에 대한 접근을 시도하고 unlock() 메소드를 호출함으로써 자원의 접근 권한을 해제합니다.
성능 테스트
이번 성능 테스트의 대상은 33번 책이며 성능 테스트 도구로는 JMeter를 사용합니다. JMeter 설정은 이전 테스트와 동일합니다.


[Spring][258] Spring 뮤텍스를 활용한 동시성 문제 해결
검색 구현 후 느린 검색 속도
•
도입 이유
•
문제 상황
◦
검색에 7~10초 가량 소요될 정도로 시간이 오래걸림
◦
→ 이 시간이 오래걸리는것이, 페이징 때문인지 파악하기가 어려움.
◦
→ 콘솔 로그에서 단순 시간 체크를 해보니 전체 페이지숫자를 연산하는것때문에 느리다
•
해결 방안 의견
◦
%KEYWORD%와 같은 like절의 키워드 검색 속도를 개선 할 수 있는 방법이 없을지 파악 필요
◦
검색 쿼리 최적화: 검색 쿼리를 최적화하여 불필요한 부하를 줄이고 더 효율적으로 데이터를 가져올 수 있도록 개선하는 것이 중요
◦
Full-Text Search Index 검색은 자연어 처리에 기반하고 있어 사용자가 검색할 때 사용하는 언어의 특성을 고려할 수 있어요. 이를 통해 더 유연한 검색이 가능하며, 대용량의 텍스트 데이터에서 효과적으로 활용될 수 있다.
◦
Elasticsearch나 Solr 같은 검색 엔진을 도입하면 검색 엔진은 대용량 데이터에서 빠르고 효율적인 검색을 지원하며, 다양한 기능과 유연성을 제공
◦
캐싱 활용 자주 사용되는 검색어나 결과를 캐싱하여 중복 검색 요청 개선
◦
파티셔닝 및 샤딩: 데이터를 파티셔닝하거나 샤딩하여 검색 범위를 축소
•
의사 결정
검색 결과가 다수 나타날 때 [페이징] 자체가 성능을 좌우하는 문제
•
도입 이유
◦
도서 키워드 검색 시 키워드 검색 결과에 대해서도 페이징 처리가 추가되어있음
◦
해당 페이징 링크를 이동할 때도 첫 키워드 검색과 유사한 시간이 소요됨
유저 - 도서 대출 등 서비스 이용용도 도서 검색 기능 화면
관리자 - 도서 관리용 도서 검색 화면
[Spring][258] 검색관련 문제해결 및 성능 개선 방안 수집
진행중 | 완료 | |
송ㅇㅇ | 카프카 | 세마포어, 뮤텍스 (ReentrantLock) |
정ㅇㅇ | Redisson 분산락(10.27 예정) | 비관적락, 낙관적락
트랜잭션 격리수준변경
Syncronized |
1.
락공유 자원에 접근할 때 그 자원을 사용하는 스레드만이 접근하도록 제한한다.다른 스레드들은 대기한다.
•
뮤텍스(Mutex), 세마포어(Semaphore)
1.
트랜잭션
여러 작업을 하나의 묶음으로 처리하여 모든 작업이 성공적으로 이루어지거나 아무런 작업도 이루어지지 않도록 하는 방법이다.
2.
데드락 회피
자원 할당 상태와 스레드의 요구를 고려하여 데드락이 발생하지 않도록 자원을 할당한다.
Locking
-ReentrantLock
트랜잭션 격리 수준을 더 높게 설정하기
•
현재 설정된 Isolation.REPEATABLE_READ 대신 Isolation.SERIALIZABLE을
특정 엔터티에 대한 동시 접근 제한
a.
애플리케이션 로직 재검토
•
다중 스레드 환경에서 동시에 동일한 데이터에 접근하는 로직이 있는지 체크한다.
•
필요한 경우, 해당 로직을 동기화 메커니즘을 사용하여 동시 접근을 방지한다.
•
synchronized 키워드나 ReentrantLock 등의 도구를 사용하여 동시성 문제를 해결할 수 있다.
b.
추가적인 예외 처리
•
현재 NullPointerException이 발생하는 곳에 더 구체적인 예외 처리를 추가하여 사용자에게 명확한 오류 메시지를 제공한다.
[Spring][258] 동시성 문제 해결 및 성능 개선 방안 수집
문제 상황



Paging
[Spring][258] 프로젝트 성능 개선 : 대용량 데이터 처리를 위한 페이징에서 슬라이스로의 전환
세마포어란?
세마포어는 다중 스레드 프로그래밍에서 동시에 공유 자원에 접근하는 스레드의 수를 제한하여 동시성 문제를 방지하는 데 사용되는 변수나 추상 데이터 타입입니다.
세마포어는 특정한 수의 토큰을 가지며, 스레드가 세마포어를 획득하려면 토큰을 얻어야 합니다.
토큰이 없다면, 스레드는 대기 상태에 들어갑니다.
세마포어는 주로 두 가지 종류가 있습니다
이진 세마포어와 카운팅 세마포어이진 세마포어는 0 또는 1의 값을 가지며, 상호 배제를 위해 사용됩니다.
카운팅 세마포어는 0 이상의 값을 가질 수 있으며, 제한된 수의 자원에 대한 접근을 관리합니다.
현제 이 글에서 동시성 문제 해결을 위해서 이진 세마포어를 사용했습니다.
문제 상황
이벤트 신청 페이지

현재 프로젝트를 진행하며 이벤트 신청 페이지를 통해 사용자들이 책을 신청할 수 있는 기능을 제공하고 있습니다.
그러나 성능 테스트를 해보니 다수의 사용자가 동시에 같은 책을 신청할 때 문제가 발생하였습니다.
JMeter을 이용한 동시성 테스트
[Spring][258] Spring 세마포어를 통한 동시성 오류 해결
문제
Spring Boot에서 Controller 계층의 메서드를 테스트하던 중 NullPointerException이 발생했다.
@RequestParam을 사용하여 요청 파라미터를 받아오는 과정에서 파라미터의 기본값이 null로 설정되어 있었고, 이로 인해 테스트 중에 null 값이 메서드로 전달되었다.
Mockito를 사용하여 서비스 계층의 메서드를 모의(Mock)할 때 any(클래스.class) 형태로 작성하였지만, 실제로는 null 값이 전달되어 문제가 발생했다.
문제 분석
@RequestParam의 기본값이 null로 설정되어 있고, Mockito를 사용하여 서비스 계층의 메서드를 모의할 때 any(클래스)를 사용했기 때문에, null 값을 받아들일 수 없었다.
해결
디버거를 사용하여 실제로 어떤 값이 메서드로 전달되는지 확인했다.
이 과정에서 null 값이 전달되는 것을 확인하고, Mockito의 when 구문에서 사용하는 any() 메서드를 any(클래스)에서 any()로 변경하여 문제를 해결할 수 있었다.
any() 메서드는 어떤 타입이나 값이든 받아들일 수 있기 때문에, null 값도 문제없이 처리할 수 있다.
[Spring][258] 트러블 슈팅 : Spring Boot 테스트: @RequestParam의 기본값과 Mockito any() 메서드 사용 시 주의점
문제 상황

bookService 객체가 초기화되지 않아 해당 객체의 메서드를 호출할 때 NullPointerException이 발생하였다.
문제 원인
[Spring][258] 트러블 슈팅: `BookServiceTest`에서 `NullPointerException` 발생 문제
Q. 페이징 처리에 관련된 코드 질문
우선 페이저블 객체를 사용하는것이 표준화되었다고 해서 페이저블 객체로 페이징을 구현해보았습니다.
페이징 처리에서 페이저블 객체를 사용하면 좋은점 조사
페이징 처리할 부분이 많아지면서 팀원 각자 기능에 페이징을 구현했는데, 추후 병합해보니 표현 방식이 조금 다른것을 발견했습니다.
동료는 페이저블 객체를 서비스 계층에서 사용했고, 컨트롤러의 매개변수에서 어노테이션으로 구현 한 것으로 차이가 있었습니다.
두 방식 중에 어떤 방식이 좋을지 판단이 어려워서 코드의 장단점을 조사해봤는데
두 코드의 차이점, 장단점 조사
•
성능적 차이가 발생할 만한 요소는 없는지도 궁금합니다.
•
또한 실무에서 어떤식 많이쓰는지, 단순히 개발자의 성향? 컨벤션을 정하는거에 따른것인지 궁금합니다.
A. 멘토님답변정리!
코드의 통일성을 맞추는것은 필수
어노테이션 기반은 자동화기 때문에, 내부적인 코드, 빌드 순서 등 동작의 흐름을 알기 어렵기때문에 문제
영익님것처럼 서비스에 구현하는것을 추천함, 장단점은 있지만 서비스가 더 직관적, 개발자가 컨트롤할만함.
Q. 페이징에 대해 아래와 같이 접근해보았습니다.
책 나눔 이벤트와 도서 사이에 1대N의 관계가 입니다.
처음에는 책 나눔 이벤트에서 도서를 패치 조인하여 페이징을 시도했는데 메모리에서 페이징이 되어 오작동의 위험이 있다고 알게 되었습니다.
그래서 도서 쪽(N)에서 패치 조인하여 페이징 처리를 진행했습니다.
이런 방식이 옳은 접근인지 궁금하고, 책 나눔 이벤트(1)에서 JPQL을 사용하여 직접 쿼리를 작성해 페이징을 시도할 때 발생하는 구체적인 문제점이 무엇인지 알려주실 수 있을까요?
그리고 도서 쪽(N)에서 페이징을 처리할 때 겹치는 문제나 다른 이슈가 있을 수 있는지도 여쭤보고 싶습니다
A. 멘토님답변정리!
우선 페이징 처리는 1이던 N이던 어디에서든 필요하다. 쿼리문이 어떤 식으로 작동되는지 보고 파악 할 필요가 있다.
페이징 처리를 하는 대상을 직접 가져오는 방법이 맞다.
Q. 코드 디버깅 중 특정 이슈에 직면했습니다. 디버깅을 통해 프로그램의 흐름을 멈췄음에도 불구하고 디버거를 통해 해당 객체를 조회하니 실제 쿼리가 전달되었습니다.
그 결과 디버거에서와 콘솔에서의 결과가 달라 혼란을 겪었습니다.
제가 문제를 탐색한 결과, Java와 ORM 프레임워크를 사용할 때 디버거로 객체의 상태를 확인하려고 할 때 그 객체에 설정된 지연 로딩이 동작하게 되어 이러한 문제가 발생하는 것을 알게 되었습니다.
이를 "디버거 지연로딩 트랩"이라고 하는 것 같더군요.
이에 대한 해결 방법이나 권장 사항이 있을까요?
특히 디버깅 중에 예상치 못한 데이터베이스 쿼리가 실행되는 것을 피하거나 데이터의 무결성 문제나 데이터 접근 문제를 방지하는 방법에 대한 조언을 얻고 싶습니다.
A. 멘토님답변정리!
객체에 어떤 데이터가 있을 지 디버거 커서가 넘어갈때 발생하는 문제인데,
실제 코드 실행과 디버깅 환경은 다를 수 있다. 문제가 아니라, 디버거를 사용하여 객체의 상태를 확인하면서 발생하는 데이터베이스 쿼리가 있을 수 있음에 주의해야 하며, 이로 인한 부작용을 방지하기 위해 충분한 주의가 필요합니다.
Q. 동일 http 메소드(get, post, put, delete), 동일 endpoint에서 Request parameter만 다를 경우 별도의 컨트롤러 함수를 생성해서 전달되도록 하려 했으나 동일한 경로로 취급이 되는지 에러가 났습니다. 그래서 이를 하나로 합친 후 파라미터 값에 따라서 별도의 서비스 메소드를 출력하는 형태로 생성해서 구현했습니다.
1. 동일한 경로에도 입력받는 매개변수 목록에 따라서 별도의 컨트롤러 메소드를 생성하는 것이 가능한지 궁금합니다.
2. 이것이 불가능할 경우, 혹은 일반적으로 매개변수 목록을 구분해서 별도의 서비스 메소드를 호출하는 것이 좋은지, 하나의 서비스 메소드에서 모든 매개변수 목록을 입력받은 후 서비스에서 이를 처리하는 것이 좋은지 궁금합니다.
A. 멘토님답변정리!
동일한 경로에도 입력받는 매개변수 목록에 따라서 별도의 컨트롤러 메소드를 생성하는 것은 불가능→ 메소드 레벨에서는 분리가 안된다. 실행부에서 조건문이나 service로 분기하는 것으로 해야한다. OR PathVariable로 api를 나누는 것이 맞을 수 있다.
매개변수 목록을 구분해서 별도의 서비스 메소드를 호출하는 것이 좋은지 → 지양해야 한다. API를 나눠서 설계를 해야하는 것이 필요하다.
keyword , category 두가지 검색 유형이 겹치면서 4가지 유형이 나타나고
SRP
Single responsibility principle
하나의 역할만을 담당해야 한다.
원칙에 따라서, 우선 4개의 API로 구분되야 하는 것이 기본적으로 맞고, Controller / Service 모두 분기되는것이 맞다. 이후에 코드의 중복성 등을 고려하고 합치는 등 고려
Q. 도서 800mb 1000만건 도서 데이터를 수집했습니다.
저희가 생각하는 것은 우선 많은 데이터를 검색하는 쪽의 성능개선을 목표로하는데,
800mb짜리 1개의 파일과 같은 용량 자체가 큰 데이터를 처리하는것과
클라이언트로 전송하는 횟수와 서버에서 데이터를 처리하는 용량의 차이?
일반적인 기업은 이 중 어떤것을 중점으로 보는가?
A. 멘토님답변정리!
이미지나 영상같은것을 다룰수 있는 콘텐츠, 서비스를 먼저 정하고 추가 기능으로 해볼만하다.
횟수와 사이즈 둘다 경험해보는 것이 필요하다. 횟수적 대용량 데이터의 검색 최적화 만큼 , 대용량 파일의 최적화 IO처리도 중요하다.
[Spring][258] [2주차 멘토링] 질문내용 정리와 답변
문제 상황
1.
JPA 페이징 처리 문제BookDonationEvent와 Book 간의 1대다 관계에서 BookDonationEvent 중심의 페이징 쿼리 실행 시 원하는 결과를 얻지 못하는 현상이 발생했다.
커스텀 커리를 작성하였지만 정상적으로 동작하지 않는다.
도서와 event가 1대 다 관계라서 정상적으로 작동하지 않는 걸로 추정된다.
원인 분석
페이징 처리의 복잡성
JPA의 페이징 처리는 논리적으로 간단하지만 join fetch를 사용하면서 발생하는 문제는 각 BookDonationEvent가 여러 Book을 가질 수 있기 때문이다.
따라서 한 BookDonationEvent 내부의 여러 Book들이 페이징 처리의 대상이 되면서 원하는 페이징 결과를 얻기 어려웠던 것 같다.
해결
적절한 페이징 처리
BookDonationEvent를 중심으로 페이징하는 대신 직접적으로 Book을 조회하는 방식으로 쿼리를 변경하여 문제를 해결했다.
이 방식을 사용하면 BookDonationEvent에 종속되지 않고 원하는 조건과 함께 Book만을 페이징 처리하여 결과를 얻을 수 있다.



[Spring][258] 트러블 슈팅 : JPA 페이징 처리
문제 상황
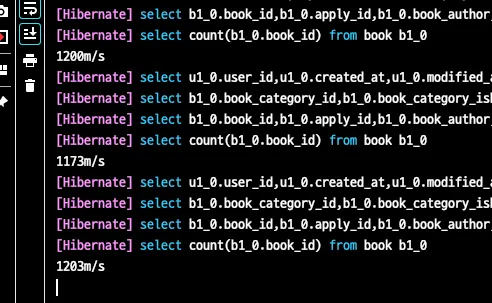
코드를 진행 중 getbooks.get(0)을 사용해 특정 책 하나만을 조회하려고 했으나, 이상하게 전체 책을 조회하는 쿼리가 실행되었다는 문제가 발생했다.
특히나 디버거를 통해 실행할 때와 콘솔에서 직접 실행했을 때 쿼리의 결과가 다르게 나타났다.
콘솔

디버거


문제 탐색
[Spring][258] 트러블 슈팅 : 디버거에서의 지연 로딩(Lazy Loading) 트랩
문제

문제 상황
BookRepository의 findPageByBookStatus 메서드에서 페이징 쿼리를 사용하는데 필요한 Pageable 매개변수가 누락되어 오류가 발생했다.
트러블 슈팅 절차
1.
원인 파악
•
로그 메시지를 확인하면, Could not create query for ... Reason: Paging query needs to have a Pageable parameter라는 메시지가 보인다.
이는 Pageable 매개변수가 없어서 발생하는 문제이다.
[Spring][258] 트러블 슈팅 : Spring JPA에서 페이징 쿼리 오류 해결
Load more